谁说大象不会跳舞
Hadoop是什么
Hadoop的官网:http://hadoop.apache.org/
官网定义:The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
Hadoop: 适合大数据的分布式存储和计算平台
现为Apache顶级开源项目,Hadoop不是指具体一个框架或者组件,它是Apache软件基金会下用Java语言开发的一个开源分布式计算平台。实现在大量计算机组成的集群中对海量数据进行分布式计算,适合大数据的分布式存储和计算平台。
举个简单例子:假如说你有一个篮子水果,你想知道苹果和梨的数量是多少,那么只要一个一个数就可以知道有多少了。如果你有一个集装箱水果,这时候就需要很多人同时帮你数了,这相当于多进程或多线程。如果你很多个集装箱的水果,这时就需要分布式计算了,也就是Hadoop。Hadoopd之所谓会诞生,主要是由于进入到大数据时代,计算机需要处理的数据量太过庞大。这时就需要将这些庞大数据切割分配到N台计算机进行处理。当大量信息被分配到不同计算机进行处理时,要确保最终得到的结果正确就需要对这些分布处理的信息进行管理,的一套解决方案。
总结
1、Hadoop是Apache旗下的一套开源适合大数据的分布式存储和计算平台平台
2、Hadoop提供的功能:利用服务器集群,根据户自定义业逻辑对海量数进行分布式处理
hadoop的概念:
狭义上: 就是apache的一个顶级项目:apahce hadoop
广义上: 就是指以hadoop为核心的整个大数据处理体系
Hadoop的起源
HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,为Apache Lucene项目的一部分,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
这个问题的解决方案源于Google的三大论文 :GFS ,BigTable和MapReduce。受此启发的Doug Cutting(Hadoop之父)等人用业余时间实现了DFS和MapReduce机制。2006年2月从Nutch被分离出来,成为一套完整独立的软件,起名为Hadoop。
Hadoop的成长过程经历了:Lucene–>Nutch—>Hadoop
三篇论文的核心思想逐步演变,最终:
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
Hadoop版本与架构核心
Apache开源社区版本,现已到3.x
Hadoop1.0版本两个核心:HDFS+MapReduce
Hadoop2.0版本,引入了Yarn。核心:HDFS+Yarn+Mapreduce
Yarn是资源调度框架。能够细粒度的管理和调度任务。此外,还能够支持其他的计算框架,比如spark等。
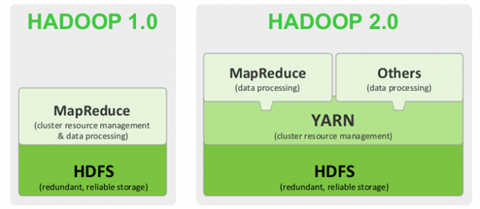
Hadoop3.0版本,未引入新核心,在原核心上,升级了很多东西。具体参见官网
Hadoop的核心组件:
1)Hadoop Common:支持其他Hadoop模块的常用工具。
2) Hadoop分布式文件系统(HDFS™):一种分布式文件系统,可提供对应用程序数据的高吞吐量访问。
3) Hadoop YARN:作业调度和集群资源管理的框架。
4) Hadoop MapReduce:一种用于并行处理大型数据集的基于YARN的系统。
大数据的处理主要就是存储和计算。
如果说安装hadoop集群,其实就是安装了两个东西: 一个操作系统YARN 和 一个文件系统HDFS。其实MapReduce就是运行在YARN之上的应用。
操作系统 文件系统 应用程序
win7 NTFS QQ,WeChat
YARN HDFS MapReduce
Hadoop理念
Hadoop可运行于一般的商用服务器上,具有高容错、高可靠性、高扩展性等特点
特别适合写一次,读多次的场景
适合场景
- 大规模数据
- 流式数据(写一次,读多次)
- 商用硬件(一般硬件)
不适合场景
- 低延时的数据访问
- 大量的小文件
- 频繁修改文件
PS
Hadoop起源的三个google论文 中文版
GFS Google的分布式文件系统Google File System
BigTable 一个大型的分布式数据库
MapReduce Google的MapReduce开源分布式并行计算框架