一、原理
Motivation
以前的方法:把源代码当作文本文件,使用信息检索模型搜索与查询语句相关的代码片段,主要依赖源代码和自然语言之间的文本相似性。这种方法缺少对查询语句和源代码深层语义的理解。比如,当查询语句是“read an object from an xml”时,与其对应的代码片段如下。查询语句中的关键词"read"和"object"和代码中的"load"和"instance"虽然语义相近,但是文本完全不同。这种情况下使用信息检索模型就无法得到好的结果。
public static < S > S deserialize(Class c, File xml) {
try {
JAXBContext context = JAXBContext.newInstance(c);
Unmarshaller unmarshaller = context.createUnmarshaller();
S deserialized = (S) unmarshaller.unmarshal(xml);
return deserialized;
} catch (JAXBException ex) {
log.error("Error-deserializing-object-from-XML", ex);
return null;
}
}
本文的方法:把代码片段和自然语言描述编码到高维向量空间,使用高维向量之间的相似性衡量自然语言描述与代码片段的相关性,依据高维向量之间的相似性进行搜索。映射到高维空间这种做法不仅能够提取出自然语言或者代码片段中的深层语义,也能够去除其中不相关文本的噪声。
Sequence Embedding
Recurrent Neural Network是用于Sequence Embedding的典型网络。RNN的结构如下图所示。隐藏层计算并记录当前输入的高维向量表示,隐藏层的向量与序列的下一个输入用于计算新的向量表示。这样新的向量里面就包含了序列之前的记忆信息,也就是结合了上文语义信息得到当前输入的高维表示。输入序列通过RNN之后可以得到其对应的高维向量表示,该向量包含了输入序列的深层语义信息。

Joint Embedding
Joint Embedding用于把同质的数据映射到统一的向量空间,用向量空间的距离度量衡量数据的语义相似性。公式写为
和
是映射函数,J是向量相似性度量函数。通过Joint Embedding可以把同质的数据通过高维空间相近的向量联系在一起。
二、网络结构:CODEnn
CODEnn的具体结构如下图所示,从代码片段中提取出代表性数据特征:方法名称、API序列,分别用RNN提取语义信息(符号由于是单个单词,所以使用多层感知机提取语义信息),之后融合成一个向量表示。代码段对应的自然语言描述也用一个RNN网络提取语义信息。得到的两个向量用cos函数衡量相似性。
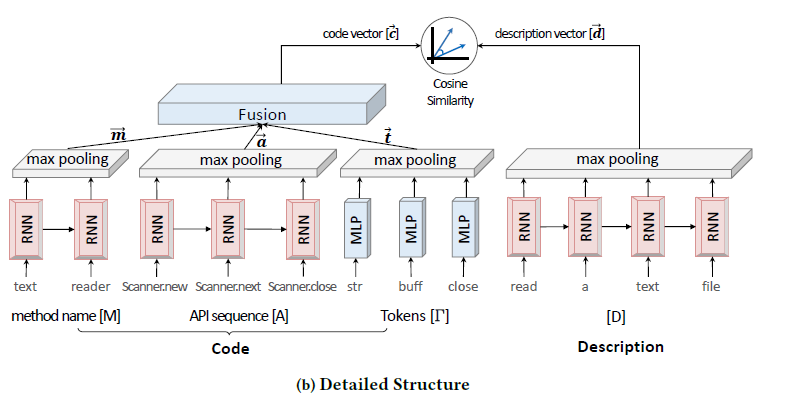
模型的优点
- 从代码段中提取出了有效的表征(method name, API sequence, Tokens)。直接使用完整的代码段存在两个问题:存在大量与查询语句无关的信息;有效表征之间相距较远,使用RNN提取上下文之间的关联信息有限。
模型的缺点:
- 使用fusion的方法处理embedding得到的结果不合理。代码段不同的表征所蕴含的深层语义信息可能不重合或者完全不同,使用加权相加的方法把不同表征的embedding融合在一起可能导致完整语义信息的不同部分被fuse到一起。
- 单向RNN提取语义信息具有局限性。代码段和对应描述都具有上下文信息,使用单向RNN提取的信息具有局限性。
三、重现结果
| epochs=200 | |||||
|---|---|---|---|---|---|
| dataset | acc@top5 | acc@top10 | MRR | MAP | nDGG |
| validation set(pool=200) | 0.756259 | 0.845612 | 0.579432 | 0.579432 | 0.643666 |
| validation set(pool=800) | 0.545417 | 0.664965 | 0.386002 | 0.386002 | 0.452403 |
| test set(pool=200) | 0.755136 | 0.846565 | 0.579599 | 0.579599 | 0.644025 |
| test set(pool=800) | 0.546007 | 0.666215 | 0.389056 | 0.389056 | 0.455014 |
| epochs=210 | |||||
| dataset | acc@top5 | acc@top10 | MRR | MAP | nDGG |
| validation set(pool=200) | 0.763946 | 0.854014 | 0.590155 | 0.590155 | 0.653864 |
| validation set(pool=800) | 0.560868 | 0.674792 | 0.397505 | 0.397505 | 0.463657 |
| test set(pool=200) | 0.762517 | 0.853707 | 0.589216 | 0.589216 | 0.653039 |
| test set(pool=800) | 0.557396 | 0.672014 | 0.398689 | 0.398689 | 0.463785 |
对比在python上的重现性能上有0.05的drop。按照完全相同的操作得到的实验曲线如下(时间有限只跑了400多个epoch):

从实验曲线看出performance在200个epoch之后就开始下降,对应的loss不再继续减小。最好的结果出现在第210个epoch,详细的数据见上面的表格。说明在python上的重现的文档上report的参数设置与实验结果是不匹配的。
原论文数据集是Java的代码,重现时数据集是python的代码,两个数据集的大小也不相同,所以结果也不具有可比性。
四、改进思路
针对前面提到的两个缺点,提出下面两个改进的方向
- 使用attention的module来处理method name, API sequence, Tokens embedding得到的向量。不同的代码段与自然语言描述之间可能有不同的对应关系,使用attention的结构能够很好的解决这个问题。
- 使用双向的RNN结构用于提取代码段和自然语言描述的上下文信息。
由于时间有限,没有对这两个思路进行实现。
五、对合作伙伴的评价
我的搭档涂涵越工作很积极,国庆期间阅读完了deep code search的论文并分享了他的看法。后续和我一起对实验结果进行了详细的分析。