集合类和接口之间的关系图,能够比较清楚的展示各个类和接口之间的关系(其中:点框为接口(...) 短横线框为抽象类(---) 实线为类)
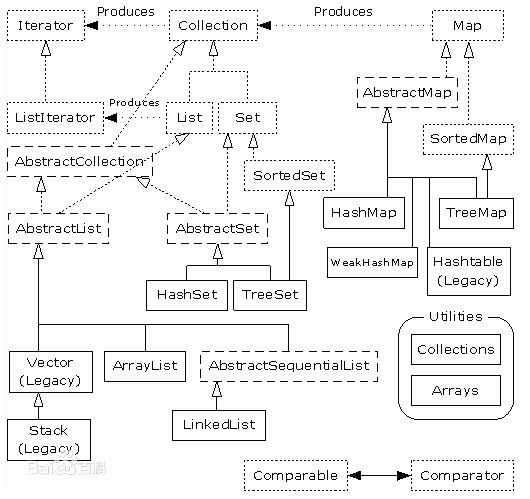
上图可以看到:集合可以分成两部分来学习。一个是以Collection为顶层接口,这种集合是单值元素<value>。一个是以Map为顶层接口,这种结合是<key,value>形式。
List和Set
Collection接口下面直接继承的有抽象类 AbstractCollection和两个接口:List、Set
相同点:
1、提供大致相同的操作数据集合的方法,例如:add()、remove()、congtains()、size()等
不同点:
1、List元素可重复、元素有序(和添加顺序一致)、元素可为空
2、Set元素不可重复、元素无序、元素可为空
2、Set元素不可重复、元素无序、元素可为空
思考:可空和不可为空的限定条件是什么?
List子类:ArrayList、LinkedList、Vector
ArrayList底层数据结构是数组,LinkedList底层数据结构是链表。Vecotor和ArrayList差不多,但是线程安全,这也就意味着它速率比ArrayList慢。
数组和链表的数据结构特点:
数组:下标访问,所以访问速度比较快,TC为O(1),插入的时候需要移动数据元素,插入慢。TC为O(n)
链表:插入速度快T(1)。只需要改变指针指向。访问慢O(n),需要从头开始一个一个查找。
Set子类:HashSet、TreeSet
HashSet基于HashMap的key实现,元素不重复。TreeSet实现了SortedSet,基于TreeSet的key实现,意味着有序,当然也是不重复。
HashSet唯一性保证:
基于HashMap的key实现,当通过hash()方法计算出要插入的Entry[]数组的位置后,通过equals()方法来进行比较,equals()方法比较的是两个对象的引用是否相等,如果不相等,则插入,如果相等,则把这个值覆盖上一个。
TreeSet有序性保证:
如果简单类型,由于他们继承了Comparable,直接比较,如果为自定义对象,则需要显示实现Comparable,实现comparableTo()方法,方法内规则自己定义。
Map之HashMap和TreeMap
HashMap key和value值允许为空,key相同时,前者会覆盖后者,保持最新。
Comparable和Comparator
可以看到在TreeMap里面有两套比较的方法,分别使用了Comparable和Comparator。if...else分别使用两种方式。所以对于集合排序,二者都可以使用。
1 Comparator<? super K> cpr = comparator; 2 if (cpr != null) { 3 do { 4 parent = t; 5 cmp = cpr.compare(key, t.key); 6 if (cmp < 0) 7 t = t.left; 8 else if (cmp > 0) 9 t = t.right; 10 else 11 return t.setValue(value); 12 } while (t != null); 13 } 14 else { 15 if (key == null) 16 throw new NullPointerException(); 17 @SuppressWarnings("unchecked") 18 Comparable<? super K> k = (Comparable<? super K>) key; 19 do { 20 parent = t; 21 cmp = k.compareTo(t.key); 22 if (cmp < 0) 23 t = t.left; 24 else if (cmp > 0) 25 t = t.right; 26 else 27 return t.setValue(value); 28 } while (t != null); 29 }
Comparable是在集合内部定义的方法的排序,像Integer,String等都会实现Comparable接口,所以天生具有可比较的属性。
Comparator是在集合外部定义的方法,如果排序规则不能满足需要,可以显示实现该接口,然后重写方法定义规则,当然重写Comparable也是可以的。
使用Comparator是策略模式,就是不改变策略本身,而是通过一个策略对象来改变他的行为。(策略模式需要复习)
比较两个对象的值,使用两种接口的实现方式如下:
Comparable
int result = person1.comparTo(person2)
Comparator
PersonComparator comparator= new PersonComparator(); comparator.compare(person1,person2);
Collections
Collections是一个类,区别于Collection接口。Collections提供了几个操作集合对象的方法,同时提供了几个静态共有常量。
常量如下:
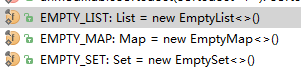
这些常量可以在参数判断时使用。例如:
1 Map getMap(String key){ 2 if(StringUtil.isEmpty(key)){ 3 return Collections.EMPTY_MAP; 4 } 5 ... ... 6 }
几个比较常用的方法:sort()、addAll()、isEmpty()等,重点看sort()方法
1 public static <T extends Comparable<? super T>> void sort(List<T> list) { 2 list.sort(null); 3 }
sort()方法主要用来对List排序,因为Set无序。
这里主要看对于ArrayList的排序。因为它比较常用。
1 public void sort(Comparator<? super E> c) { 2 final int expectedModCount = modCount; 3 Arrays.sort((E[]) elementData, 0, size, c); 4 if (modCount != expectedModCount) { 5 throw new ConcurrentModificationException(); 6 } 7 modCount++; 8 }
这里面调用了Arrays.sort()方法,点进去看到函数是这样的:
1 public static <T> void sort(T[] a, int fromIndex, int toIndex, 2 Comparator<? super T> c) { 3 if (c == null) { 4 sort(a, fromIndex, toIndex); 5 } else { 6 rangeCheck(a.length, fromIndex, toIndex); 7 if (LegacyMergeSort.userRequested) 8 legacyMergeSort(a, fromIndex, toIndex, c); 9 else 10 TimSort.sort(a, fromIndex, toIndex, c, null, 0, 0); 11 } 12 }
这里看到,如果是LegacyMergeSort.userRequested
1 static final class LegacyMergeSort { 2 private static final boolean userRequested = 3 java.security.AccessController.doPrivileged( 4 new sun.security.action.GetBooleanAction( 5 "java.util.Arrays.useLegacyMergeSort")).booleanValue(); 6 }
这里理解为是一个配置,通过传参数来设置使用传统的归并排序。否则的话,使用TimSort排序,这个是归并排序的优化版,也就是说,默认使用TimSort排序。
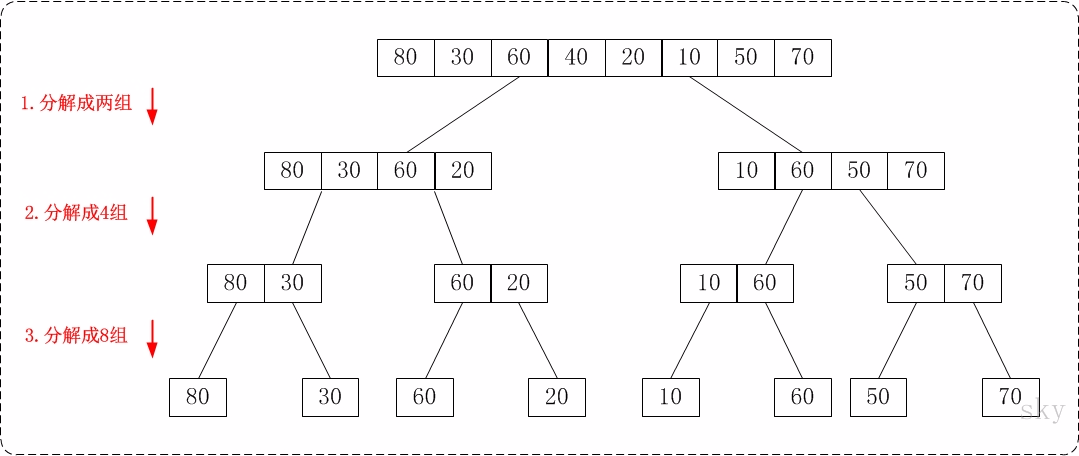
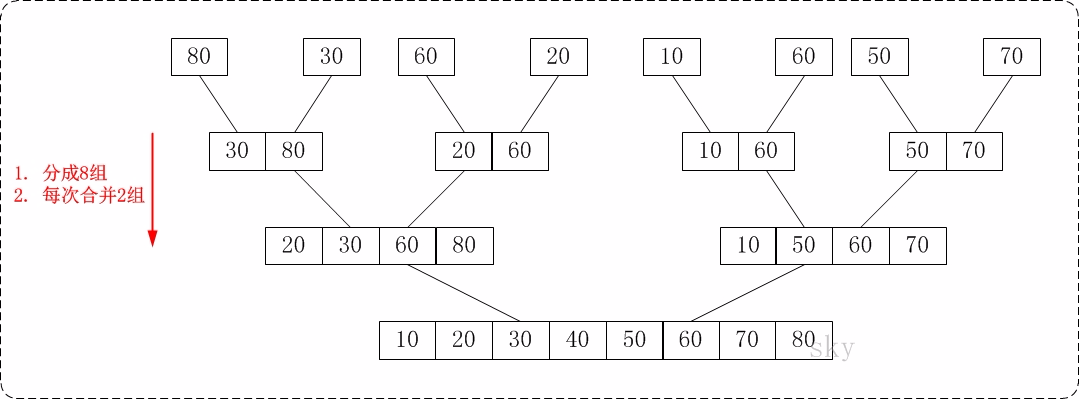
归并排序:大致思路就是先把待排序数组依次分解,然后递归两两组合排序,直至整个数组有序。时间复杂度O(N*logN).
下面两个图就比较直观反映了数据处理过程
Collection是个接口,然后JDK提供了Collections类来对接口通用方法进行操作。类似的还有Arrays工具类。以后自己在设计接口的时候也可以考虑此种方式。
源码-HashMap
HashMap源码关键点:
- 数组+链表(JDK1.7及以前)
- 数组+红黑树(JDK1.8)
- 一个元素的添加过程
- 线程不安全的解释
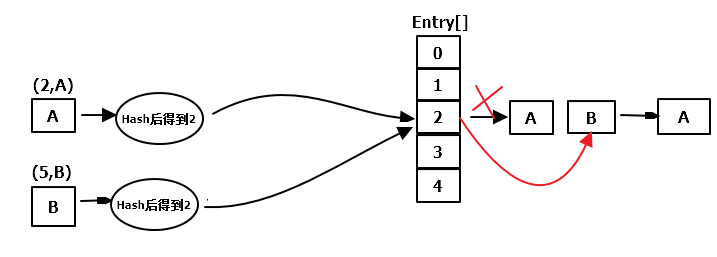
这里画一个图,有点不恰当的是Entry[]里面应该存放链表的第一个元素。这里直接画到了外面。
Entry数组结构如下:
1 static class Entry<K,V> implements Map.Entry<K,V> { 2 final K key; 3 V value; 4 Entry<K,V> next; 5 int hash; 6 }
2、数组+红黑树(JDK1.8)
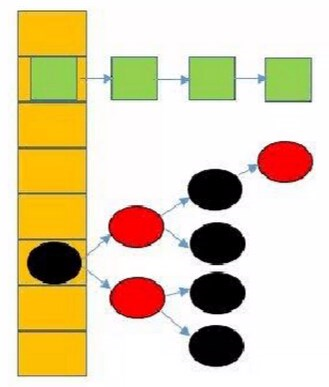
3、一个元素的添加过程
HashMap的特点是key不能重复,key-value值均可为空,如果key为null,hash值返回0。有一个地方需要注意的是:key相等和key通过hash之后相等的区别。也就是说,如果key1=key2,那么通过hash之后的值也相等,插入同一个Entry数组对应的下标中。然后会通过equals()方法判断二者是否相等,如果相等,则后者覆盖前者保持最新。如果不相等,则把该元素插入到Entry元素根节点位置,原节点往后移动作为该节点的下一个节点或者子节点(对于树)。
4、线程不安全的地方
(1)put操作
当有A、B两个线程Hash之后同时到达Entry数组的下表 i 时,就有可能出现问题。先来看一下一个线程hash之后的插入操作,其实就是一个链表的插入过程。
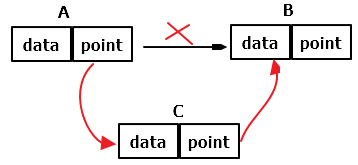
详细步骤:
1.oldValue = Entity[4];
2.Entity[4] = newValue;
3.newValue.next = oldValue;
那么在多线程操作情况下,可能线程1在“2”步执行完成后,还没执行“3”步时,线程2执行了containsKey方法,这时就取不到"oldValue"。再过几毫秒去看,又有"oldValue"了。
(2)resize操作
一个线程在hash找下标,一个在扩容,出现问题。
源码-ConcurrentHashMap
ConcurrentHashMap源码关键点:
- 它是线程安全的,如何保证
- 分段锁相比Hashtable整个Synchronized方法的优势
- 分段锁的时候,size()方法的处理
if (key == null || value == null) throw new NullPointerException();
Hashtable是线程安全的,保证线程安全的方法是在每个方法上面加上Synchronize。
synchronized int size(); synchronized boolean isEmpty(); ... ...
相比Hashtable,ConcurrentHashMap采用了分段锁(Segment)来保证线程安全性。每个段相当于是一个小的Hashtable。但同时会存在多个Segment(默认16),这样,每个段之间的操作是真正的并发而彼此之间不受影响。
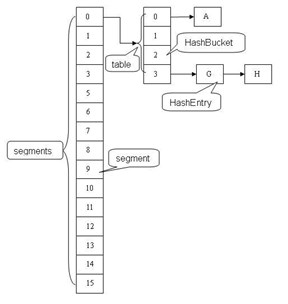
从上图可以看到:一个ConcurrentHashMap包含多个segment,每个segment都是一把锁,对应一段table(这个table就是HashMap的结构,由HashBucket【hash桶】和HashEntry组成)。各个segment之间是彼此独立的。每个Segment均继承了可重复锁ReetrantLock
static final class Segment<K,V> extends ReentrantLock implements Serializable
Segment下面包含很多歌HashEntry列表数组。对于一个key,需要经过三次hash操作,才能最终定位这个元素的位置。三次hash分别是:
1、对于一个key,先进行一次hash操作,得到hash值h1,即h1=hash1(key);
2、将得到的h1的高几位进行第二次hash,得到hash值h2,即h2=hash2(h1高几位),通过h2能确定该元素放在哪个Segment中;
3、将得到的h1进行hash,得到hash值h3,即h3=hash3(h1),通过h3能够确定该元素放置在哪个HashEntry。
CoucurrentHashMap中主要实体类就三个:ConcurrentHashMap(整个Hash表),Segment(片段),HashEntry(节点)
不变(Immutable)和易变(Volatile)
ConcurrentHashMap允许多个读操作并发进行,读操作不需要加锁。如果使用传统的技术,如HashMap中的实现,如果允许可以在hash链的中间添加或删除元素,读操作将得到不一致的数据。ConcurrentHashMap实现技术是保证HashEntry几乎是不可变的。HashEntry代表每个hash链中的一个节点,结构如下:
1 static final class HashEntry<K,V> { 2 final K key; 3 final int hash; 4 volatile V value; 5 volatile HashEntry<K,V> next; 6 }
在JDK1.6中,HashEntry中的next指针也定义为final,并且每次插入将添加新节点作为链的头节点,每次删除节点时,会将删除节点之前(这里指时间的前后,不是指位置)的所有节点拷贝一份组成一个新的链,而将当前节点的上一个节点的next指针指向当前节点的下一个节点,从而在删除之后有两条链存在,因而可以保证即使在同一条链中,有一个线程正在删除,而另一个线程正在遍历,他们都能工作良好,因为遍历的线程能继续使用原有的链。因而这是一种更加细粒度的happens-before关系,即如果遍历线程在删除线程结果后开始,则它能看到删除后的变化,如果它发生在删除线程正在执行中间,则它会使用原有的链,而不会等到删除线程结束执行后再执行,也就是说,这种情况下遍历线程看不到删除线程的影响。而HashMap中的Entry只有key是final的
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; }
不变模式是多线程安全里最简单的一种保障方式。因为你拿他没有办法,想改变它也没有机会。
不变模式主要通过final关键字来限定。Final域使得确保初始化安全性成为可能。
下面主要通过对ConcurrentHashMap的初始化、put操作、get操作、size操作和containsValue操作进行分析和学习。
初始化
构造函数的源码如下:
1 public ConcurrentHashMap(int initialCapacity, 2 float loadFactor, int concurrencyLevel) { 3 if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0) 4 throw new IllegalArgumentException(); 5 if (concurrencyLevel > MAX_SEGMENTS) 6 concurrencyLevel = MAX_SEGMENTS; 7 // Find power-of-two sizes best matching argumentsint sshift = 0; 8 int ssize = 1; 9 while (ssize < concurrencyLevel) { 10 ++sshift; 11 ssize <<= 1; 12 } 13 this.segmentShift = 32 - sshift; 14 this.segmentMask = ssize - 1; 15 if (initialCapacity > MAXIMUM_CAPACITY) 16 initialCapacity = MAXIMUM_CAPACITY; 17 int c = initialCapacity / ssize; 18 if (c * ssize < initialCapacity) 19 ++c; 20 int cap = MIN_SEGMENT_TABLE_CAPACITY; 21 while (cap < c) 22 cap <<= 1; 23 // create segments and segments[0] 24 Segment<K,V> s0 = 25 new Segment<K,V>(loadFactor, (int)(cap * loadFactor), 26 (HashEntry<K,V>[])new HashEntry[cap]); 27 Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize]; 28 UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]this.segments = ss; 29 }
传入的参数有initialCapacity(初始容量),loadFactor(负载因子),concurrencyLevel(并发级别)三个参数。
1、initialCapacity指的是ConcurrentHashMap中每条链中的Entry的数量。默认值static final int DEFAULT_INITIAL_CAPACITY = 16;
2、loadFactor表示负载因子,当ConcurrentHashMap中元素大于loadFactor*最大容量时需要扩容。(最大容量=每条链的entry格式*Entry的数组长度)
3、concurrencyLevel(并发级别)用来确定Segment的个数,Segment的个数是大于等于concurrencyLevel的第一个2的n次方的数。比如,如果concurrencyLevel为12,13,14,则segment的数目就为16(2的四次方)。默认值static final int DEFAULT_CONCURRENCY_LEVEL = 16。理想情况下ConcurrentHashMap的真正的并发访问量能够达到concurrencyLevel(这种情况就是访问的数据恰好分别落在不同的Segment中,而这些线程能够无竞争的自由访问)
put操作
put操作的源码如下:
public V put(K key, V value) { Segment<K,V> s; if (value == null) throw new NullPointerException(); int hash = hash(key); int j = (hash >>> segmentShift) & segmentMask; if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment s = ensureSegment(j); return s.put(key, hash, value, false); }
final V put(K key, int hash, V value, boolean onlyIfAbsent) { HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value); V oldValue; try { HashEntry<K,V>[] tab = table; int index = (tab.length - 1) & hash; HashEntry<K,V> first = entryAt(tab, index); for (HashEntry<K,V> e = first;;) { if (e != null) { K k; if ((k = e.key) == key || (e.hash == hash && key.equals(k))) { oldValue = e.value; if (!onlyIfAbsent) { e.value = value; ++modCount; } break; } e = e.next; } else { if (node != null) node.setNext(first); else node = new HashEntry<K,V>(hash, key, value, first); int c = count + 1; if (c > threshold && tab.length < MAXIMUM_CAPACITY) rehash(node); elsesetEntryAt(tab, index, node); ++modCount; count = c; oldValue = null; break; } } } finally { unlock(); } return oldValue; }
put操作需要加锁。
get操作
get操作不需要加锁(如果value为null,会调用readValueUnderLock,只有这个步骤会加锁),通过volatile和final来确保数据安全。
size()操作
size()操作与put和get操作的最大区别在于,size操作需要遍历所有的Segment才能算出整个Map的大小,而put和get只关系一个Segment。假设我们当前遍历的Segment为SA,那么在遍历SA过程中其他的Segment比如SB可能会被修改,于是这一次运算出来的size值可能并不是Map当前的真正大小。一个比较简单的办法就是计算Map大小的时候所有的Segment都LOCK住,不能更新(包括put,removed等)数据,计算完之后再UNLOCK。这是普通人所能想到的方案,但是牛逼的作者还有一个更好的Idea:先给3次机会,不lock所有的segment,遍历所有segment,累加各个segment的大小得到整个Map大小,如果某相邻的两次计算获取的所有Segment的更新次数(每个Segment都有一个modCount变量,这个变量在Segment中的Entry被修改时会加1,通过这个值可以得到每个Segment的更新操作的次数)是一样的,说明计算过程中没有更新操作(至少从查看Map的大小方向来看没有变化),则直接返回这个值。如果这三次不加锁的计算过程中Map的更新次数有变化,则之后的计算先对所有的Segment加锁,再遍历所有Segment计算Map的大小,最后再解锁所有的Segment。源代码如下:
public int size() { // Try a few times to get accurate count. On failure due to// continuous async changes in table, resort to locking.final Segment<K,V>[] segments = this.segments; int size; boolean overflow; // true if size overflows 32 bitslong sum; // sum of modCountslong last = 0L; // previous sumint retries = -1; // first iteration isn't retrytry { for (;;) { if (retries++ == RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) ensureSegment(j).lock(); // force creation } sum = 0L; size = 0; overflow = false; for (int j = 0; j < segments.length; ++j) { Segment<K,V> seg = segmentAt(segments, j); if (seg != null) { sum += seg.modCount; int c = seg.count; if (c < 0 || (size += c) < 0) overflow = true; } } if (sum == last) break; last = sum; } } finally { if (retries > RETRIES_BEFORE_LOCK) { for (int j = 0; j < segments.length; ++j) segmentAt(segments, j).unlock(); } } return overflow ? Integer.MAX_VALUE : size; }
举个栗子:
一个Map中有四个Segment,标记为S1,S2,S3,S4。现在我们要获取Map的size。计算过程是这样的:
- 第一次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设每个Segment的大小分别为1,2,3,4,更新操作次数分为别2,2,3,1,则这次计算可以得到Map的总大小为1+2+3+4=10,总共更新次数为8;
- 第二次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设这次每个Segemnt的大小变成了2,2,3,4,更新次数分别为3,2,3,1,因为两次计算得到的Map更新次数不一致(第一次是8,第二次是9),则可以断定这段时间Map数据被更新。
- 第三次计算,不对S1,S2,S3,S4加锁,遍历所有的Segment,假设每个Segment的更新操作次数还是3,2,3,1,则因为第二次计算和第三次计算得到的Map更新次数是一致的,就能说明第二次计算和第三次计算这段时间内Map数据没有被更新,此时可以直接返回第三次计算得到的Map大小。
containsValue
containsValue操作采用了和size操作一样的想法。