在大数据使用、开发过程的性能优化一般可以从以下角度着手进行。
- SQL 语句优化。使用关系数据库的时候,SQL 优化是数据库优化的重要手段,因为实现同样功能但是不同的 SQL 写法可能带来的性能差距是数量级的。我们知道在大数据分析时,由于数据量规模巨大,所以 SQL 语句写法引起的性能差距就更加巨大。典型的就是 Hive 的 MapJoin 语法,如果 join 的一张表比较小,比如只有几 MB,那么就可以用 MapJoin 进行连接,Hive 会将这张小表当作 Cache 数据全部加载到所有的 Map 任务中,在 Map 阶段完成 join 操作,无需 shuffle。
- 数据倾斜处理。数据倾斜是指当两张表进行 join 的时候,其中一张表 join 的某个字段值对应的数据行数特别多,那么在 shuffle 的时候,这个字段值(Key)对应的所有记录都会被 partition 到同一个 Reduce 任务,导致这个任务长时间无法完成。淘宝的产品经理曾经讲过一个案例,他想把用户日志和用户表通过用户 ID 进行 join,但是日志表有几亿条记录的用户 ID 是 null,Hive 把 null 当作一个字段值 shuffle 到同一个 Reduce,结果这个 Reduce 跑了两天也没跑完,SQL 当然也执行不完。像这种情况的数据倾斜,因为 null 字段没有意义,所以可以在 where 条件里加一个 userID != null (userID is not null)过滤掉就可以了。
- MapReduce、Spark 代码优化。了解 MapReduce 和 Spark 的工作原理,了解要处理的数据的特点,了解要计算的目标,设计合理的代码处理逻辑,使用良好的编程方法开发大数据应用,是大数据应用性能优化的重要手段,也是大数据开发工程师的重要职责。
- 配置参数优化。根据公司数据特点,为部署的大数据产品以及运行的作业选择合适的配置参数,是公司大数据平台性能优化最主要的手段,也是大数据运维工程师的主要职责。比如 Yarn 的每个 Container 包含的 CPU 个数和内存数目、HDFS 数据块的大小和复制数等,每个大数据产品都有很多配置参数,这些参数会对大数据运行时的性能产生重要影响。
- 大数据开源软件代码优化。曾经和杭州某个 SaaS 公司的大数据工程师聊天,他们的大数据团队只有 5、6 个人,但是在使用开源大数据产品的时候,遇到问题都是直接修改 Hadoop、Spark、Sqoop 这些产品的代码。修改源代码进行性能优化的方法虽然比较激进,但是对于掌控自己公司的大数据平台来说,效果可能是最好的。
Spark 性能优化
关于性能测试,我们使用的是 Intel 为某视频网站编写的一个基于 Spark 的关系图谱计算程序,用于计算视频的级联关系。我们使用 5 台服务器对样例数据进行性能测试,程序运行总体性能如下图。
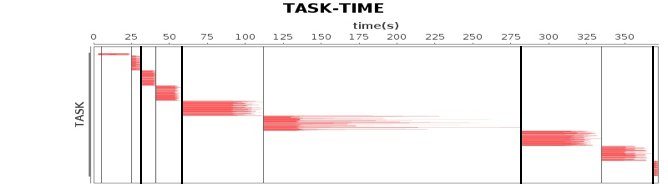
这张图我在专栏 Spark 架构原理分析过。我们将 4 台 Worker 服务器上主要计算资源利用率指标和这张图各个 job 与 stage 的时间点结合,就可以看到不同运行阶段的性能指标如何,从而发现性能瓶颈。
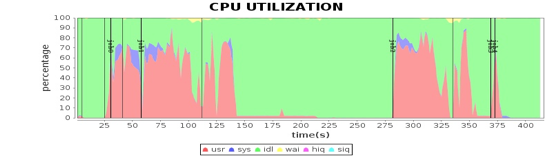
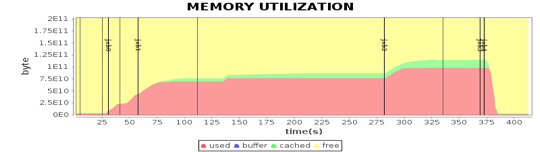
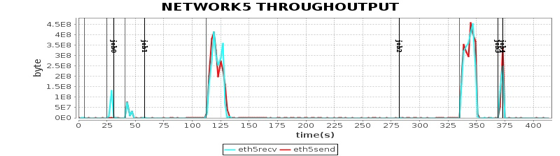
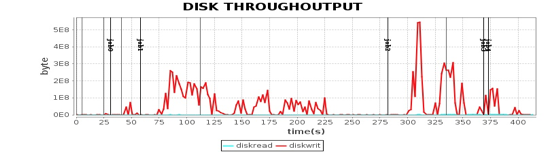
从这些图我们可以看到,CPU、内存、网络、磁盘这四种主要计算资源的使用和 Spark 的计算阶段密切相关。后面我主要通过这些图来分析 Spark 的性能问题,进而寻找问题根源,并进一步进行性能优化。