本文简单介绍了熵、信息增益的概念,以及如何使用信息增益对监督学习的训练样本进行评估,评估每个字段的信息量。
1、熵的介绍
在信息论里面,熵是对不确定性的测量。通俗来讲,熵就是衡量随机变量随机性的指标。比如一个随机变量X的状态有{1,2,...,n},如果X取1的概率为1,其他状态为0,那么这个随机变量一点儿随机性都没有,也就是信息量为0;反之,如果每个状态的概率都相当,也就是说这个随机变量不倾向任何一个状态,因此随机性最高。(在离散情况,均匀分布的熵最高;在连续情况,正态分布的熵最高。)
熵的计算公式:
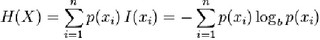
![]()
I(xi)是状态xi的信息量,H(X)是对各个状态的信息量的加权平均。如果不理解I(xi) ,可以简单地这样理解,如果p(X=xi) 很小的话,也就是说这种情况出现很罕见,因此要推测该状态就比较不容易,随机性就高,所以该状态的信息量就大。
另外,有一点需要注意的是,熵是有单位的,具体取决于用什么log底,b。比如b=2的时候,单位是bit。bit就是位,和平常我们学习的存储单位“bit”是一样的。这点如果不理解的话,大家可以做个简单的计算,令随机变量有两个状态,每个状态的概率为0.5,令b=2,这样算出来的熵是1(bit)。1bit表示我们如果要传输这个随机变量的信息的时候,需要存储量是1bit。熵还可以这样理解,熵就是我们要传输一个随机变量的信息时,需要使用的存储量。这种理解和上述是一致的,因为如果变量随机性高的话,我们传输时就需要使用更多的bit,所以,存储量大和随机性高是相同意思的。
最后,为了避免大家对概念的混淆,我们总结如下一段话:
熵越高,不确定性越高,随机性越强,信息量越大,需要的存储量就越大。
2、信息增益IG
信息增益在不同情况下,意思稍微有点区别,我们使用的概念和决策时的概念是一致的。但是,另外一种情况,即如下介绍的KL-divergence,也是可以用来筛选特征的,所以,下面,我们首先介绍一下KL-divergence,大家如果感兴趣,可以专门去了解一下。
在信息论和机器学习中,信息增益(Information Gain)或者Mutual Information都是表示Kullback–Leibler divergence,这个概念是用来描述两个随机变量之间的依赖程度,简单的理解,两个随机变量的KL-divergence就是已知某个随机变量的时候,我们还需要多少信息才能预测另一个随机变量的取值,因此,该指标是不对称的(asymmetric)。这个指标也可以用来做特征筛选,计算的指标就是一致某个特征的取值时,推测label还需要多少信息量,该量越大,说明特征提供的信息越少,否则说明特征提供的信息量很大,使得我们不需要额外的信息就可以推知label信息。
在决策树中,信息增益和KL-divergence不一样,这里信息增益指的是在划分数据集之前和之后信息发生的变化。

这里信息增益有个关键点就是对样本进行划分。像决策树,就是根据特征字段的值对样本进行划分,使得获得的信息增益最大。
3、使用IG计算字段的信息量
对于离散值的字段,我们根据该字段的取值情况对样本进行划分,将计算得到的信息增益作为字段的信息量。如果字段取值是连续性,熵和信息增益都有连续版本,但是连续版本需要求积分,计算量很大,所以,为了方便计算,我们先将字段执行离散化操作,然后计算字段的信息量。
得到字段的信息量之后,我们就可以根据一个阈值对字段进行筛选,去掉那些没有信息的字段。也可以使用topN选择最优信息量的字段。