从别人那里COPY过来的,不是原创。
1.什么是大端,什么是小端?
大端:数据的高位字节存放在低地址内,数据的低位字节存放在高地址内。
小端:数据的高位字节存放在高地址内,数据的低位字节存放在低地址内。(低低,高高)
一个整型是4个字节,如:0x1a2b3c4d。电脑读取内存数据时,是从低位地址到高位地址进行读取(从左到右)。
在小端机器中从低地址到高地址的存放方式为:0x4d,0x3c,0x2b,0x1a;(低地址存低位,高地址存高位),地址从低到高增长
在大端机器中从低地址到高地址的存放方式为:0x1a,0x2b,0x3c,0x4d;(低地址存高位)
2.方法一:将字符数据赋给整型数据,通过读取整型数据的值来判别大端还是小端
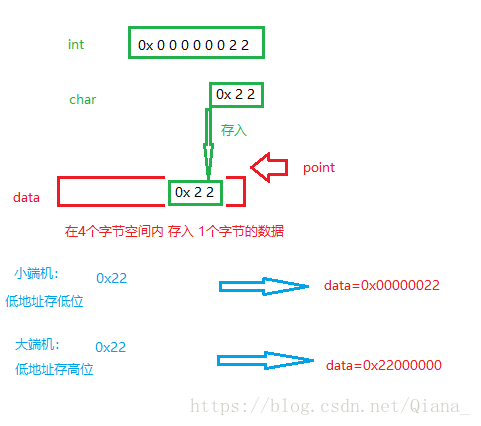
#include<iostream>
using namespace std;
int main()
{
unsigned int data = 0;
unsigned int *point = &data;
*(char*)point = 0x22;
if(data == 0x22)
cout << "这是一个小端机" << endl;
else if(data == 0x22000000)
cout << "这是一个大端机" << endl;
else
cout << "无法判定该机器类型" << endl;
return 0;
}

3.方法二:通过联合体的共享内存特性,来判断大端机、小端机
union是一个联合体,所有变量公用一块内存,在内存中的存储是按最长的那个变量所需要的位数来开辟内存的。
#include<iostream>
using namespace std;
union UN{
char ch;
int data;
};
int main()
{
union UN un;
un.data = 0x1a2b3c4d;
if(un.ch == 0x4d)
cout << "这是一个小端机" << endl;
else if(un.ch == 0x1a)
cout << "这是一个大端机" << endl;
else
cout << "无法判定该机器" << endl;
return 0;
}
因为联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写。
4.方法三:通过指针来判断
将一个整型数据赋给字符型数据,通过查看字符型数据的值来判定是大端机还是小端机。将整型赋给字符型,会发生数据的丢失。如果是大端机,则会丢失低字节;如果是小端机,则会丢失高字节。和第一种方法很类似,一个是查看整型的值,一个是查看字符型的值。
#include<iostream>
using namespace std;
int main()
{
int data = 1;
char* p = (char*)&data;
if(*p == 1)
cout << "这是一个小端机" << endl;
else if(*p == 0)
cout << "这是一个大端机" << endl;
return 0;
}
输出结果:
