1.框架与工作流
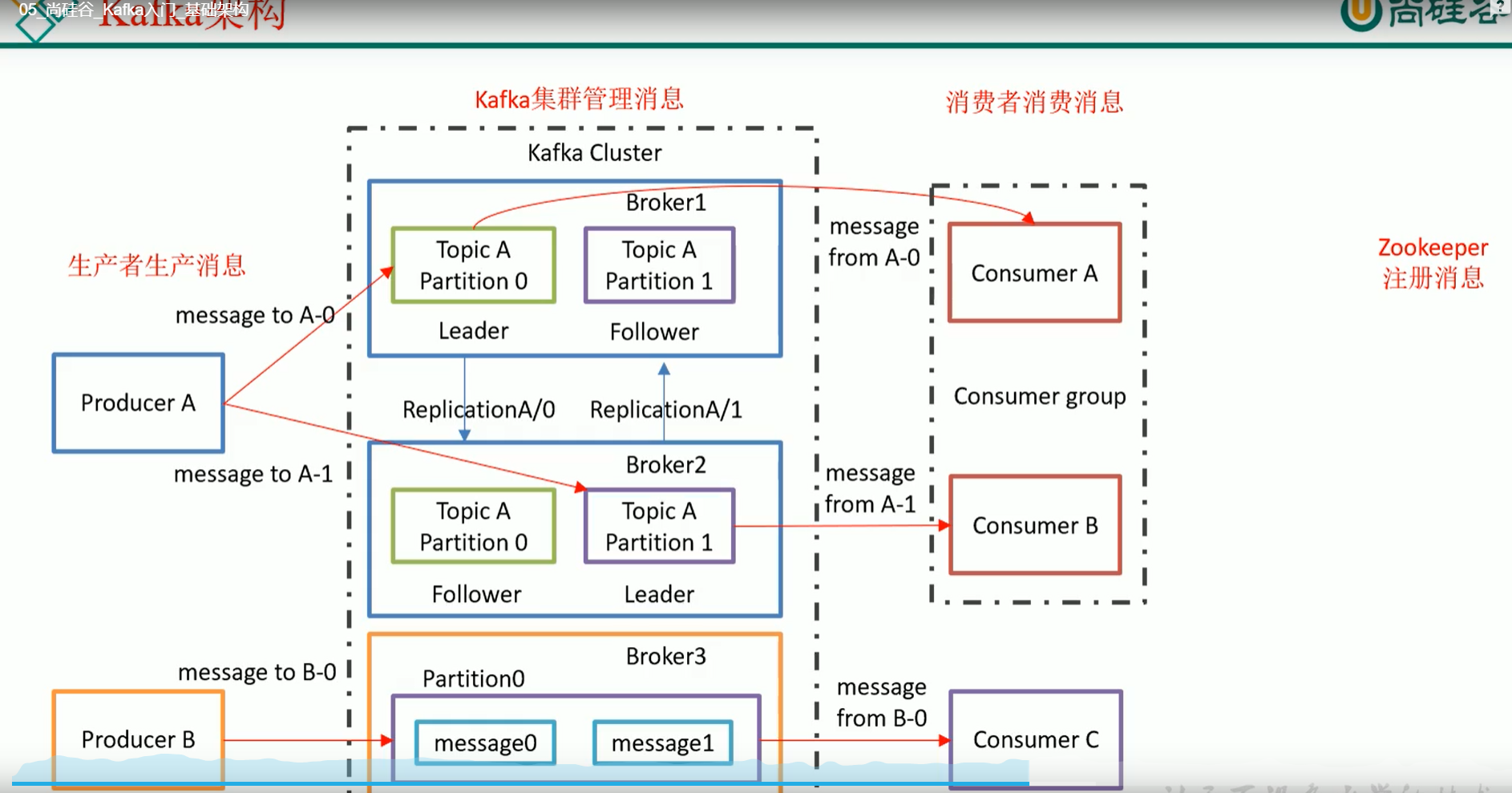
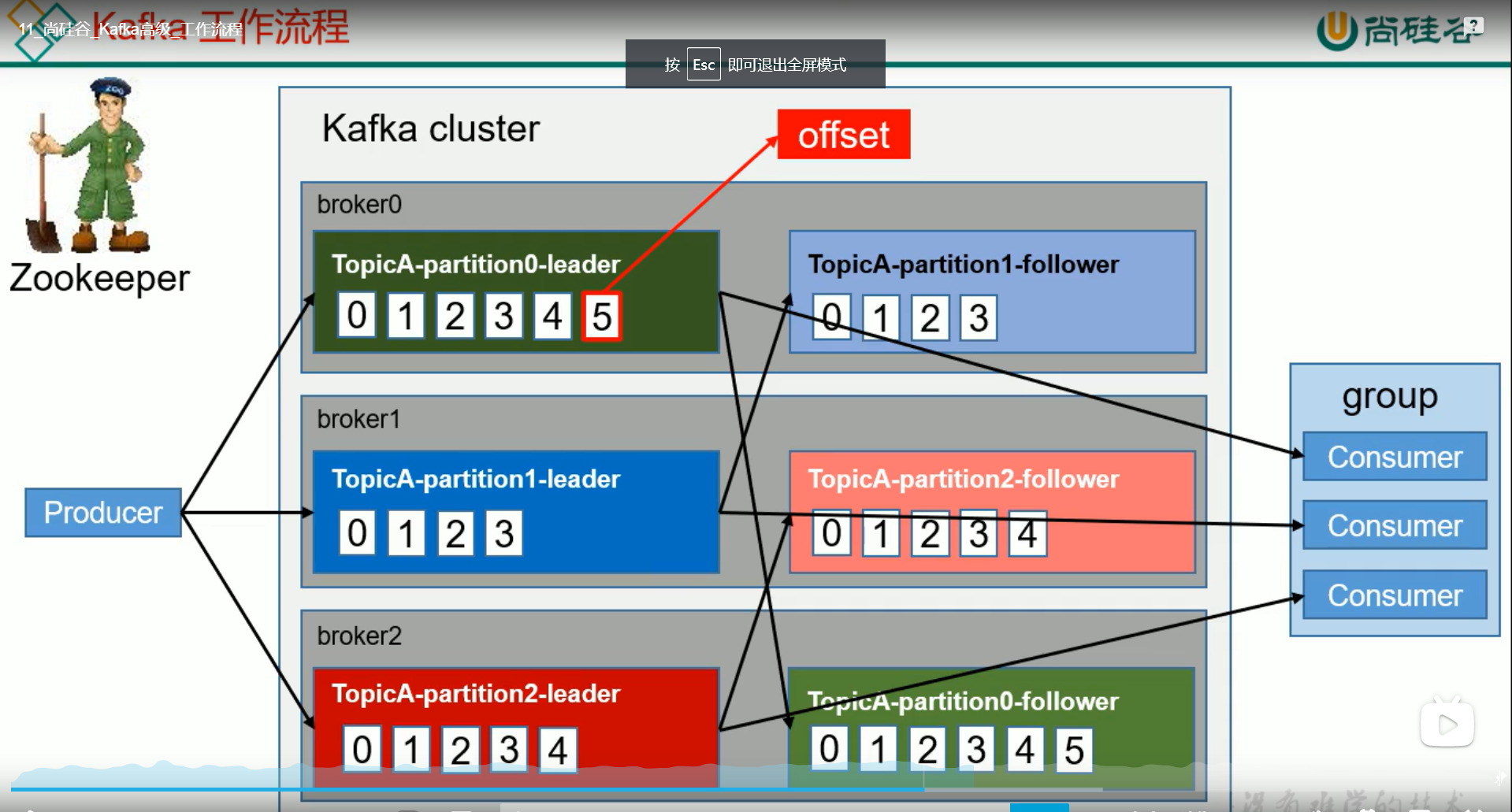
2 内部结构
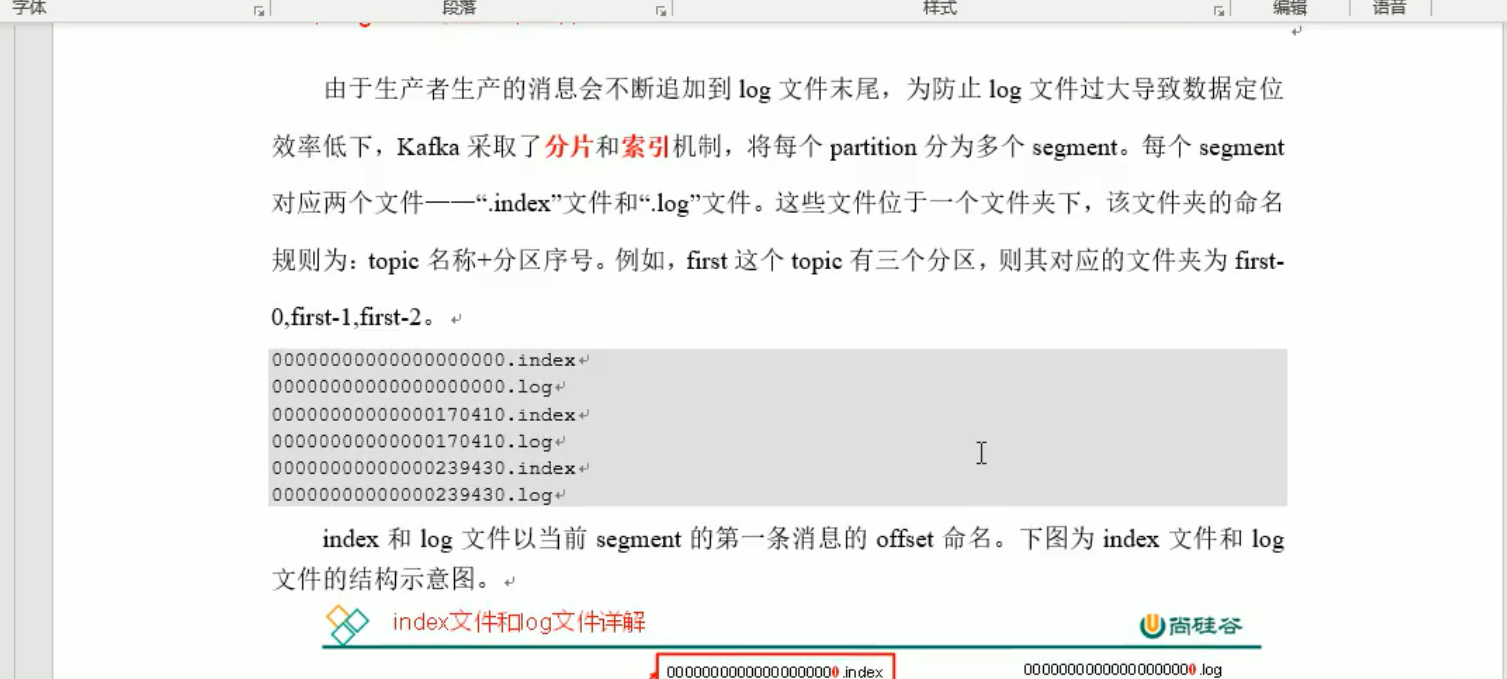
kafka的每个主题分区的数据在 first-0(主题名-分区号)文件夹下,保存 n组xxx.log文件与xxx.index文件。log文件存发送消息的元数据,每个大小默认为1G,index为log的索引存这些消息的序号与起始地址。index每个索引大小一样,这样硬件寻址的时候,可以跳跃(n-1)*length个地址,找到第n条数据的信息,查起来很快!
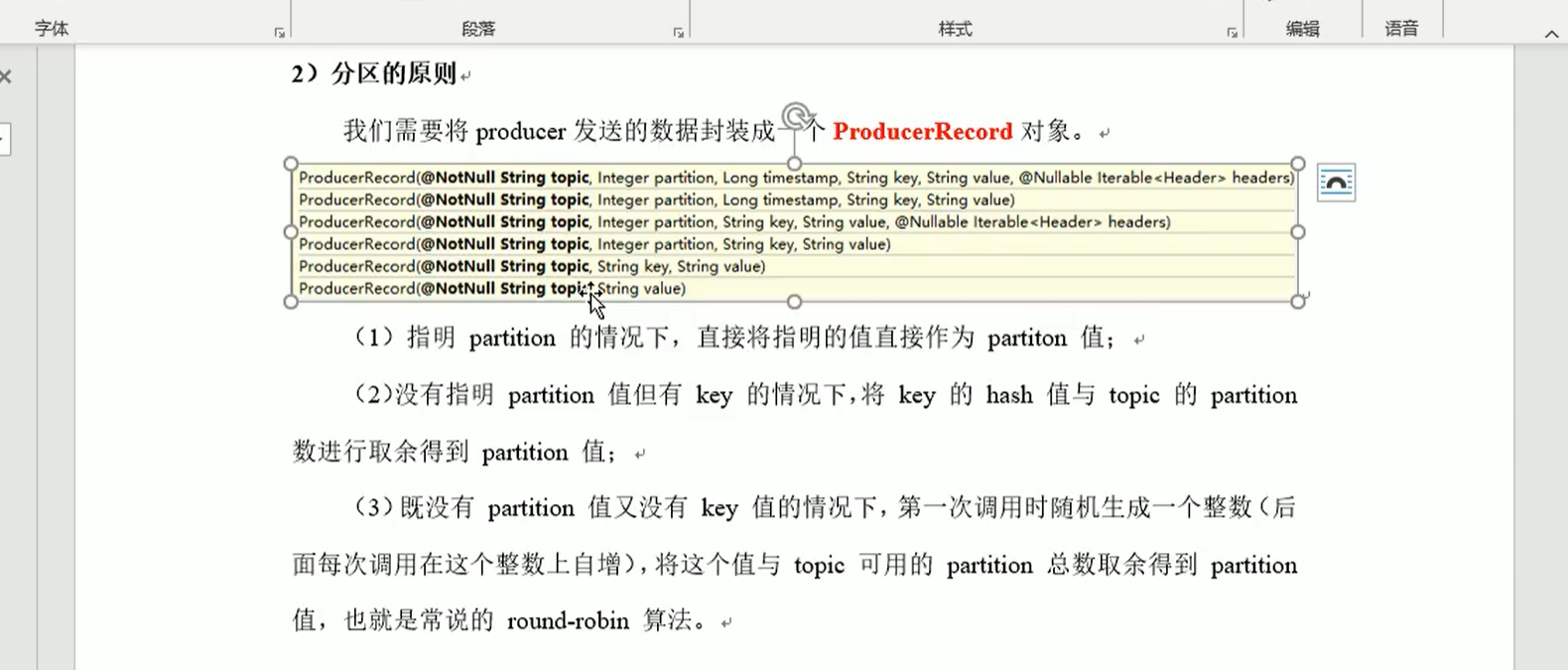
3 分区的接口方法与含义
4 ACK与ISR
ACK: 生产者给kakfa集群发送消息后,kafka会给生产者返回ack表明,已经成功接收到消息。如何解决以下问题
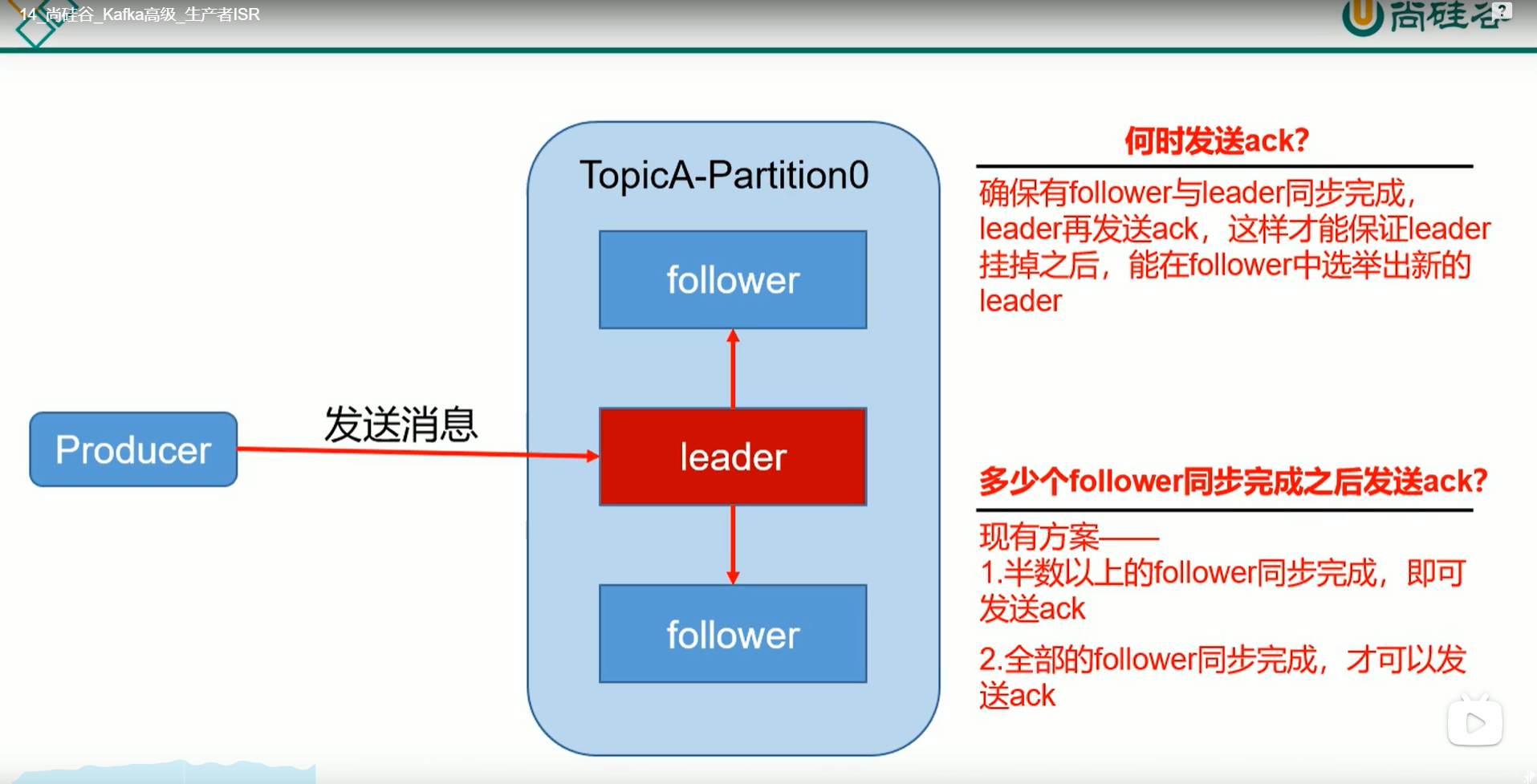

引入ISR

ISR 就是从10台foller机器中选5台进入ISR,这5台如果某在单位时间内不能与leader同步,则被踢出,或者某台与leader相差消息数量大于n,也会被踢出。
0.9版本以后,将相差数量去除,因为如果相差数量是1000,而发送消息每个batch为1200,那每次一发消息,ISR中的节点将全部被踢出,稍后同步后,又进入,而且还得访问zk,这样无线循环浪费资源
ack参数配置
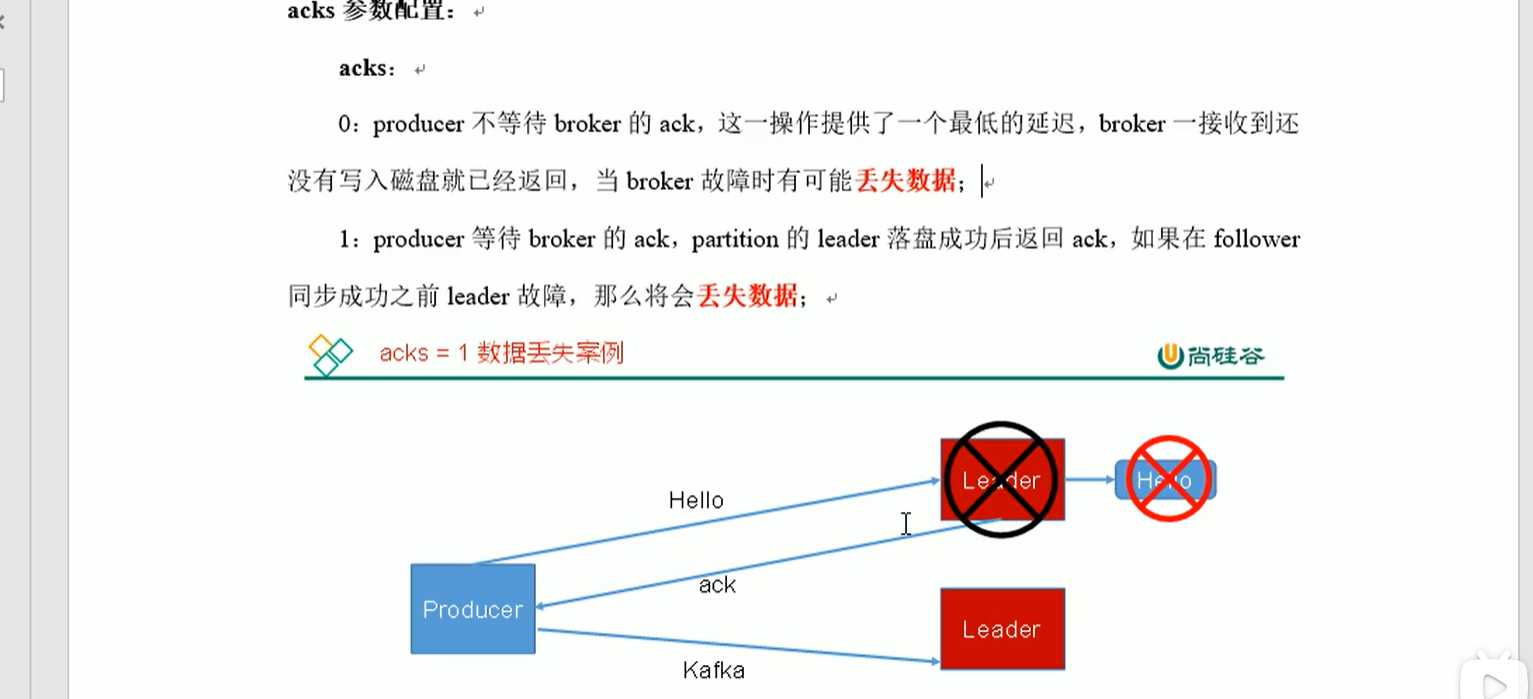
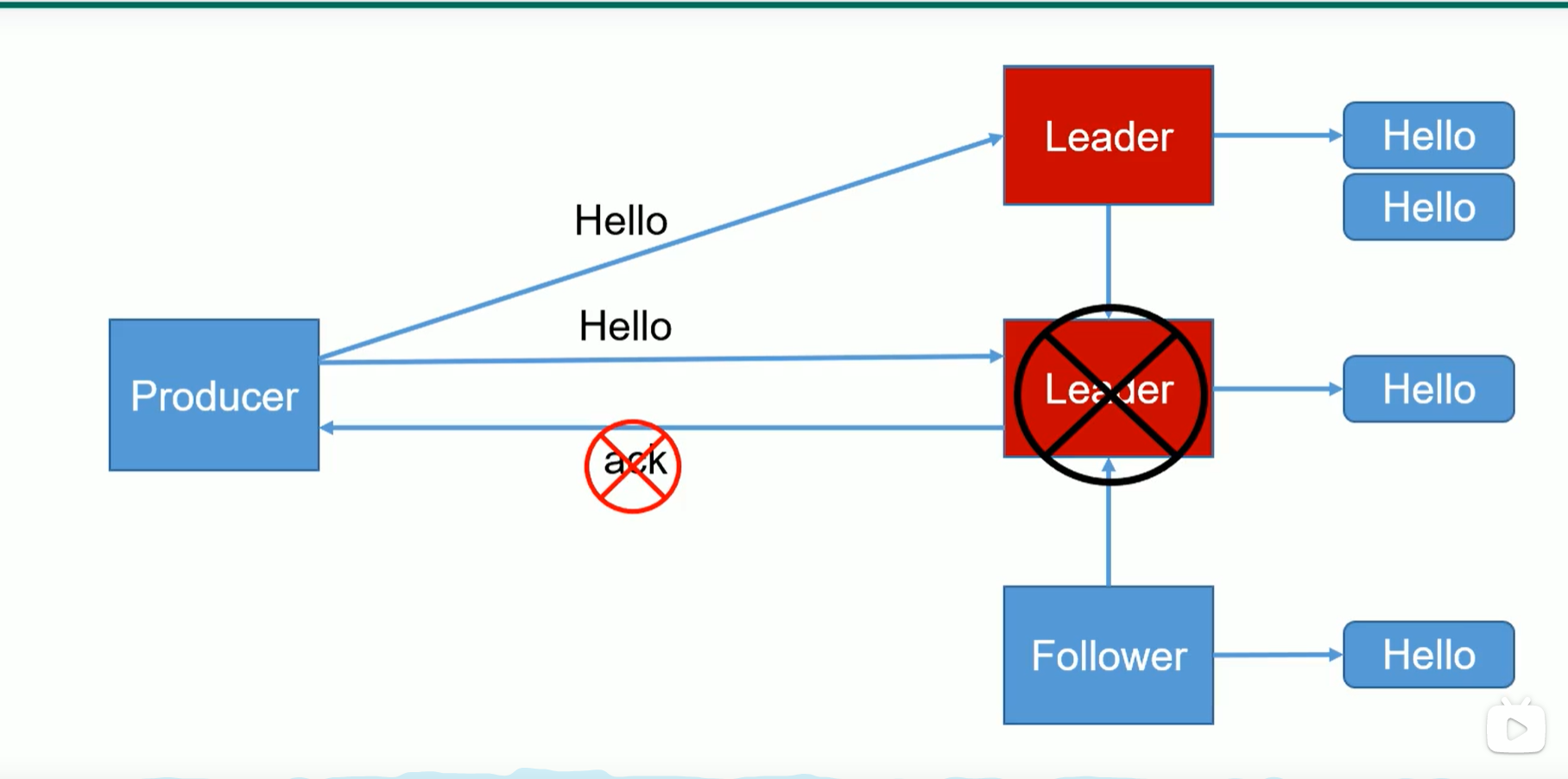
ack = 0,只发数据,啥都不管
ack = 1,发数据,leader接收完成,再返回ack,继续发数据
ack = -1 所有的ISR全部同步数据后,再返回ack,继续发数据
ack = 0 的时候,在发数据后,不管leader活不活,都有可能丢数据(在网络中丢失),ack = 1时候 leader挂掉,follwer未同步就会丢数据。ack = -1的时候,若ISR里面只有leader,则与1情况一样
ack等于 -1 的时候,若ISR的follwer已经同步,但是在返回ack过程中,leader挂掉,则会重复发送数据,造成数据重复
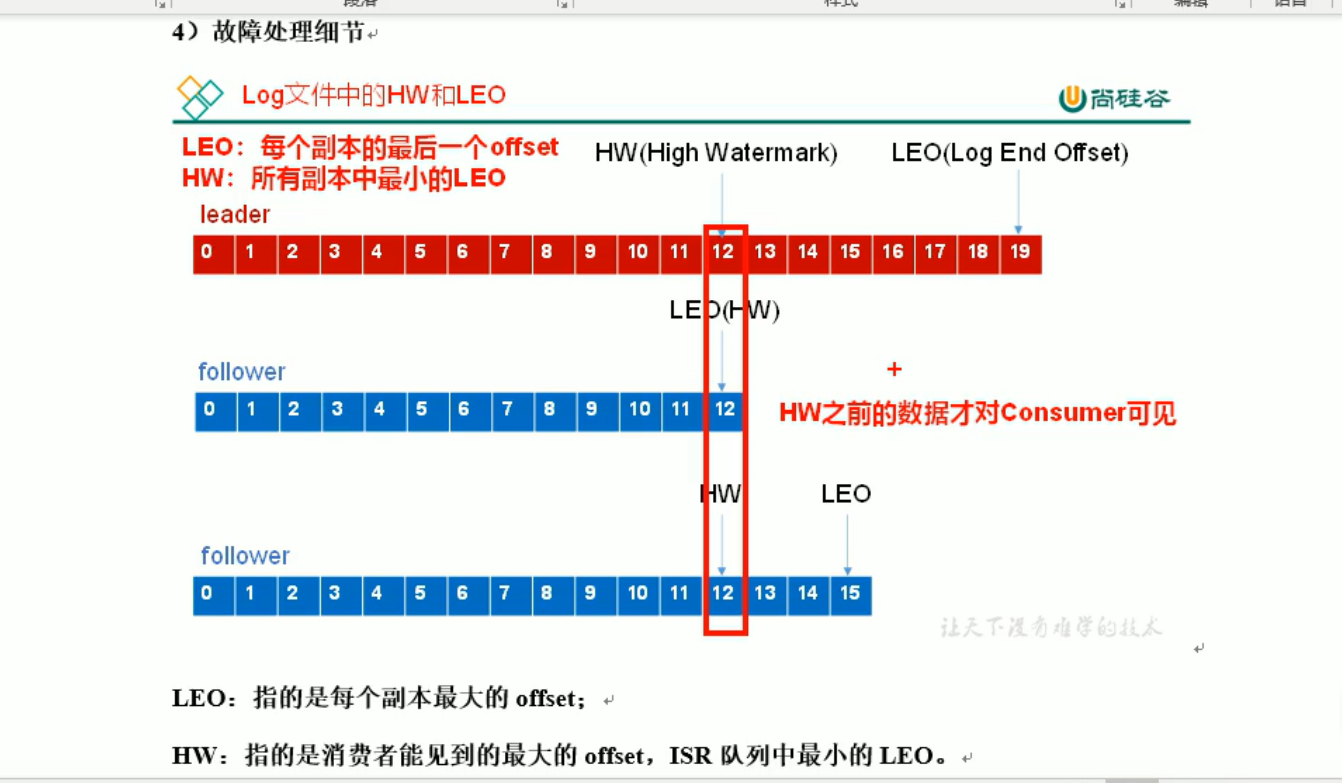
5.HW与LEO
HW:是在ISR中,所有的副本中,数据量最少的那个fowller的最后一个值,LEO是每个副本的最后一个值,如下图
分析:HW之前的数据只对消费者可见,当leader挂掉后,ISR中会选举出新的leader,然后,把HW之后的数据全部都切掉,这样生产者发送消息的时候,kafka集群就只接收HW之后的数据。
这样可以保证副本之间的数据一致性,消费者消费数据的一致性,并不能保证数据不丢失或不重复
6.kafka集群数据去重复

每个生产者在每次会话中,kafka集群都会给它分配一个producerID,发送的每条消息也会又个seqnum,根据这两个字段,可以确保同一个分区的同一个数据的唯一性