练习1#
1 ucore.img 是如何生成的
使用 make V= 查看详细的步骤
cc kern/init/init.c 使用cc工具进行预处理
gcc
-Idir 将dir 作为查找目录(头文件)
-ggdb 符加信息到允许gdb进行debug的程度
-gstabs 将符加信息以 stabs format 格式输出 这一个是主要被dbx 在大多数bsd 系统上使用
-m32
-Wall 输出所有的警告信息
-fno-buildin 不允许不易build__in__开头的buildin 函数
-nostdinc 不查找默认的c程序
-fno-stakc-portector 不使用栈保护机制
-C 生成.o 可重定位目标模块
-m32 生成32位系统的Application Binary Interface
ld
将多个可重定位模块进行重定位
-T 制定需要的脚本
kernel.ld 简析:
output_format 指定为 elf32-i386 输出的bfd格式
output_arch( 同上
entry 程序入口点
程序加载的位置 .=0x100000;
.text 节包括 .text .stub .text.* gnu.linkonce.t.*
provide 定义符号 etext=. //我才是额外的位置text
.rodata 节包括 rodata rodata.* .un.linkonce.r.*
调试信息在下面
.stab
定义 STAB_BEGIN 的位置
*.stab
定义__STAB_END__的位置
.=align(0x1000) 限定Data 的书对其
.data 包括 *.data
定义 edata在这里
.bss {
}
定义 end 在这里
/DISCARD/ eh.frame .note.GNU-stack
大概的顺序 是先构成 kernel
构成 bootblock
构筑 sign 运行了 sgin
使用sign在bootblock 最后510 511 个字节标价 0x55 0xaa
使用dd 命令 在一块区域写0 count=10000
在那块写 bootblock 512 个字节
然后写 kernel
练习2#
在 *0x7c00 出的断点语句 是cli
cli 将 IF 置0 屏蔽可屏蔽中断
对应的sti 将 IF 置1 回复相应课屏蔽中断
第二条指令 cld
cld 置 df(direction flag) 为0 说明内存地址向高地址增加
std 置 df 为1 说明内存地址向低地址增加
ntel文档使用MOVSD传送双字,而GNU文档使用MOVSL传送双字。
源操作数和目的操作数分别使用寄存器(e)si和(e)di进行间接寻址;没执行一次串操作,源指针(e)si和目的指针(e)di将自动进行修改:±1、±2、±4,其对应的分别是字节操作、字操作和双字操作。注:
附:
inb 的含义
inb 是x86.h 下的一个函数 定义如下
static inline uint8_t inb(uint16_t port){
uint_t data;
asm volatile(“inb %1,%0” :"=a"(data),"d"(port));
}
这里 %1 绑定到 a(data) 上 指定变量data 使用=a eax 寄存器 edi指定port 使用
于是inb 函数的具体含义应该是 从port 读取一个byte 到eax 返回
waitdisk(void){
while((inb(0x1f7)&0xc0)!=0x40)
从0x1f7 端口读取的数 如果不是 01** **** 就等待
}
readsect 接受 void*dst uint32_t secno
等待硬盘工作
将 1 写入端口 0x1f2
将 secno的低位1字节 写入端口0x1f3
将第二个字节 写入端口0x1f4
...
第四个字节的低位部分写入 端口 0x1f6 (secno>>24)& 0xf | 0xe0
将 0x20 写入端口0x1f7
等待硬盘
练习3##
- a20的开启
- GDT表初始化
- 如何使能进入保护模式
从这里了解的:http://hengch.blog.163.com/blog/static/107800672009013104623747/
非常好的文章
以前的是只有1M的内存空间 有20根地址线
但是寻址使用的是段寻址:
segment 和 offset 寄存器都是16位的
所以最大值就是 0xffffh
两个寄存器合起来就是
0x10ffef h 大约是1088k 就是超过了20位地址线的限制,所以在这时候就出现了回滚现象。
后来地址线变长了以后但是为了向前兼容,就是用了a20 Gate 屏蔽第21根地址线。
在保护模式下这样就只能访问奇数M的内存,这显然是不能接受的
所以需要打开 a20Gate
下面是源码阅读 bootasm.S 计算机执行的第一批指令
cli 先屏蔽中断
cld 置1说明指令向高位增长
xorw %ax %ax
movw %ax %ds
movw %ax %es
movw %ax %ss
置零关键的寄存器 段寄存器ds es ss
开始开始a20
inb $0x64 %al 从0x64 端口读入一个字节(等待不忙(8042 input buffer empty))
testb $0x2 %al 直到status register 第二个bit 是0
向port 0x64 输入0xd1
movb $0xd1 %al
outb %al $0x64
重复等待 0x64端口的 2bit 是0(不忙)
inb $0x64 %al 从0x64 端口读入一个字节(等待不忙(8042 input buffer empty))
testb $0x2 %al 直到status register 第二个bit 是0
向0x60端口 发送0xdf (含义 是设置p2'a20 bit to 1) df 11011111 1bit
附:分段存贮管理机制##
只有在保护模式下才能使用分段存贮管理记住
逻辑地址
段描述符(描述段的属性)
段描述符表(包含段描述符的数组)
段选择子(段寄存器,用于定位段描述符表中表项的索引)
逻辑转换地址(程序员使用的地址) 到物理地址(实际的物理内存地址) 分为以下两步
[1] 分段地址转换: CPU将逻辑地址(由段选择子 和 段偏移offser 构成) 中的段选择子的内容作为段描述符表的索引,找到表中对应的段描述符。
然后吧段描述符中保存的段基址加上段偏移值,形成线性地址(Linear address)
如果没有分页存贮管理机制 线性地址就是实际地址
[2]分页地址转换,线性地址 转换成实际地址
要建立好段描述符 和段描述符表
gate a20开启之后就 使用命令: lgdt gdtdesc
来具体看看 gdt 是如何构建的
.p2align 2 强制使用4 bytes 进行对齐(2 单位应该是 word)
gdt :
seg_nullasm : 生成一个空段
seg_asm: 分别是kern 的代码段和数据段
seg_asm:
gdtdesc: //生成了加载近GDTR的48位内容
.word 0x17
.long gdt
//全局描述符表目前只有三个条目
段描述符#
每一个段 由如下三个参数进行定义:
段基地址(Base Address) 段界限(Limit) 和 段属性(Attributes)
定义在kern/m/mmu.h 中定义了一个段描述符的具体格式
-
段基地址:
规定线性地址空间中 段的起始地址。 在80386保护模式下,段基地址长32位。因为基地址长度与寻址地址长度相同。 送一任何一个段可以从任何一个字节开始。(与实模式不同,实模式下的边界 必须被16整除) -
段界限:
规定段的大小。 80386保护模式下 ,段界限由20位表示。可以以字节为单位或者4K 为段位; -
段属性(Granularity)
确定段的各种性质,用符号G 来表示
G=0 表示 界限以字节为单位 那么20位的空间 就有1M的返回 增量是1字节
G=1 表示 界限以4K 为单位 对应的范围就是 4G
类型 (TYPE):用语区别 不同类型的描述符 : 可表示描述的段是代码段还是数据段,访问权限:读写执行 ,段的扩展方向
描述符特权级(Descriptor Privilege Level) : 用来实现保护机制
段存在位(Segment-Presenr bit ): 如果这一位位0, 那么这个描述符是非法的,不能用来实现地址转换。 如果一个非法的描述符被加载进了一个段寄存器。处理器会立即产生异常。 ?操作系统可以使用任何被标记位 available 的位
已访问位:当处理器访问该段(当一个指向该 段描述符的选择子被加载进一个段寄存器时) 将自动设置访问位。操作系统可以清除该位。
段描述符的结构如下
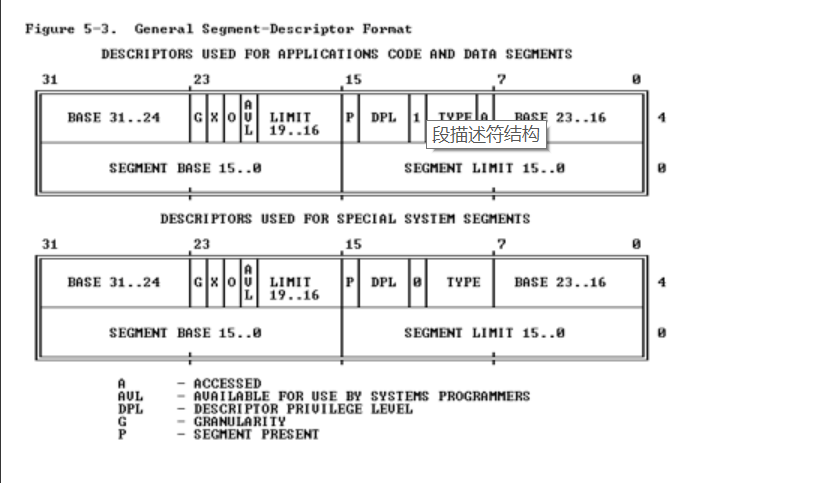
全局 段描述符表
是一个保存多个段描述符的数组,其起始地址保存在全局段描述符表寄存器 GDTR 中。
GDTR 长48位 其中高32为基地址 低16位为段界限。
由于GDT不能有GDT本身之内的描述符进行描述定义?
所以处理器采用 GDTR 作为FDT 这一特殊的系统段。
注意,全局描述符表中第一个描述符设定为空段描述符。
GDTR 中的段界限以字节为单位,对于含有N个描述符的描述符表的段界限通常可以设为 8N-1。具体可以参考 boot/bootasm.S 中的gdt地址和 kern/mm/pmm.c 中的全局变量数组 gdt[] 分别基于汇编语言和 c 语言的 全局描述符表的实现
选择子
线性地址部分的选择子 是用来选择哪个描述符表 和在该表中索引一个描述符的,选择子可以作为指针变量的一部分。 从而对程序员是可见的 ,一般由加载器来设置。
选择子的格式

索引(Index):在描述符表中从8192个描述符中选择一个描述符。处理器自动将这个索引值乘以8(描述符的长度),再加上描述符表的基址来索引描述符表,从而选出一个合适的描述符。
表指示位(Table Indicator,TI):选择应该访问哪一个描述符表。0代表应该访问全局描述符表(GDT),1代表应该访问局部描述符表(LDT)。
请求特权级(Requested Privilege Level,RPL):保护机制,在后续试验中会进一步讲解。
全局描述符表的第一项不能被cpu 使用,当一个段选择子的 索引 inde 和表指示位(Table Indicator) 都等于0时, 可以当作一个空的选择子,既是 mmu.h 中的 SEG_NULL. 当段寄存器加载空选择子的时候,处理器不会产生异常。 但是当使用一个空选择子 访问内存的时候 会产生异常。
保护模式下的特权级##
在保护模式下,特权级总共由4个 编号从0(最高特权) 到3 (最低特权) 。 三种主要资源收到保护, 内存。IO 端口 。 以及执行特殊机器指令的能力。 在任一时刻,x86 CPU都是在一个特定的特权级下运行的,从而决定了代码可以做什么,不可以做什么。这些特权级经常被称为为保护环(protection ring),最内的环(ring 0)对应于最高特权0,最外面的环(ring 3)一般给应用程序使用,对应最低特权3。在ucore中,CPU只用到其中的2个特权级:0(内核态)和3(用户态)。
有大约15条机器指令被CPU限制只能在内核态执行,这些机器指令如果被用户模式的程序所使用,就会颠覆保护模式的保护机制并引起混乱,所以它们被保留给操作系统内核使用。如果企图在ring 0以外运行这些指令,就会导致一个一般保护异常(general-protection exception)。对内存和I/O端口的访问也受类似的特权级限制。
数据段选择子的内容可由程序直接加载到各个段寄存器(SS 或 DS 等) 当中。
这些内容里包含了请求特权级(RPL ) 字段。
当然,代码段寄存器 CS 的内容不能由装载指令MOV 直接设置,只能被那些话ui改变程序执行顺序的指令(JMP INT CALL) 间接的设置,而且 CS 拥有一个由CPU 维护的当前特权级的字段 CPL (current Privilege Level)
二者的结构如下图所示

代码段寄存器中的值 总是等于 CPU 当前的特权级, 只需知道CS中的CPL 就可以知道此刻的特权级了
CPU会在两个关键点上保护内存:当一个段选择符被加载时,以及,当通过线性地址访问一个内存页时。因此,保护也反映在内存地址转换的过程之中,既包括分段又包括分页。当一个数据段选择符被加载时,就会发生下述的检测过程:

当前的特权级 要加载的特权级
因为越高的数值代表越低的特权,上图中的MAX()用于选择CPL和RPL中特权最低的一个,并与描述符特权级(Descriptor Privilege Level,简称DPL)比较。如果DPL的值大于等于它,那么这个访问可正常进行了。RPL背后的设计思想是:允许内核代码加载特权较低的段。比如,你可以使用RPL=3的段描述符来确保给定的操作所使用的段可以在用户模式中访问。但堆栈段寄存器是个例外,它要求CPL,RPL和DPL这3个值必须完全一致,才可以被加载。下面再总结一下CPL、RPL和DPL:
保护模式的进入##
计算机的cr0寄存器中去取出内容,然后置PE为 on 再设置 cro寄存器
ljmp 指令两个参数一个是 prot_mode_cseg,protcseg :下面的地址
0x10就是代码段描述符的地址
这个指令是将 prot_mode_cseg 加载到cs 寄存器中
protseg:
movw $PROT_MODE_DSEG , %ax 将数据段描述符的位置放在ax位置
movw %ax %ds data Segment
movw %ax %es extra Segment
movw %ax %fs
movw %ax %gs
movw %ax %ss Stack Segment
mov $0x0 %ebp 将ebp 初始化为0
mov (start %esp 将esp 初始化为)start
call bootmain 调用bootloader
bootmain 做了那些事##
将硬盘上的第一页读到 0x10000 中的一个 hlfhdr中去
readseg 读取一个Segment 参数是 va count offset
count 的大小是 SectSize
end_va= va +count 读取的末尾地址
secsize 是512 一个扇区的大小
va -=offset%SECTSIZE //round down to sector boundary
secno=(offset/SECTSIZE) + 1 kernel starts at sectors 1
for(;va<end_va;va+=sectsize ,secno++) {
readsect((void *)va,secno );
}
接下来执行的是 if(ELFHDR->e_magic !=ELF_MAGIC){
goto bad;
}
判断加载进来的内核是否是一个合法的内核
struct proghdr ph,eph
ph=ELFHDR+ELFHDR+e_phoffset ph 指向program header
eph=ph +ELFHDR->e_phnum; 指向prpgram header 结束的地方
for(;ph<eph;ph++){ //遍历所有的program header
readseg(ph->p_va & 0xffffff ,ph->p_memsz,ph->offset) //
}
(void (*)(void) )()(ELFHDR->e_entry & 0xffffff))() ; 调用这个可执行文件的入口 //不在返回
练习4 加载过程##
1 如何读取扇区
使用readsect 读取扇区
第一个参数 *dst 表示都出来存放的位置,
第二个参数 secno 表示第几个扇区
使用IO端口进行读取
ps:
内核是从第一个扇区开始的
第0个扇区是引导扇区
2 如何加载ELF格式的内核的
使用readseg 函数接受三个参数: va 应该在内存中的起始虚拟地址, count 读入的大小, offset 相对于第一个扇区的 offset
因为必须读一整个扇区,所以读入的时候有可能会破坏低位 内存的东西 ?(不过我们是从高位向低位读 所以没有问题)
先读取ELFHDR,然后根据ELFHDR 内的信息逐个读入程序的段
最后调用ELFHDR 中的 e_entry & 0xffffff 字段进入内核
练习5 输出函数栈信息##
主要内容在 kdebug.c 中完成 下面将分析给出的一些实现好的功能,然后尝试自己完成
1
static void stab_binsearch(const struct stab stabs,int region_left,int region_right,int type, uintptr_t addr){
int l=region_left,r=*region_right,any_matches=0;
while(l<r){
int true_m=(l+r)/2,m=true_m;
while(m>=l && stabs[m].n_type !=type){ //匹配到第一个类型相符的 类型不对就向下寻找
m--;
}
if(m<=l){
l=true_m+1;
continue;
}
any_matches=1;
if(stabs[m].n_value<addr){ //符号的值 应该也是一个地址
*region_left=m;
l=true_m+1;
}else if(stab[m].n_values>addr){
*region_right=m-1; //返回的实际上是 包含addr的最大地址 (不包括下一个匹配(类型))
r=m-1
}else{ //找右侧区域
region_left=m;
l=m;
addr++;
}
}
if(!any_matches){
region_right=region_left-1;
}else{
l=region_right;
for(;l>region_left&& stabs[l].n_type!=type;l--);
*region_left=l;
}
}
int debuginfo_eip(uintptr_t addr,struct eipdebuginto *info){ //将addr 处的结构信息填入 debuginfo
}
需要自己实现的部分
void print_stack_frame(){
uint32_t mebp=read_ebp();
uint32_t meip=read_eip();
int i;
for(i=0;i<STACKFRAME_DEPTH && ebp!=0 ;i++){
cprintf("ebp : %08x , eip: %08x
",mebp,meip);
cprintf("calling arguments: %08x %08x %08x %08x
",*(uint32_t*)(mebp+2),*(uint32_t*)(mebp+4),*(uint32_t*)(mebp+6),*(uint32_t*)(mebp+8));
print_debuginfo(meip-1);
mebp=((uint32_t *)mebp)[0]; //这里是有错误的 ebp 只需要记录上次调用这的位置 应该是 eip=((uint32_t *)mebp )[1] ebp=((uint32_t *)ebp)ebp[0]
meip=((uint32_t *)mebp)[1];
//错误的根源是我没有意识到read_eip 是一个 noninline-function 这样做是有好处的,可以快捷的读取到当前的eip值 真是6 // read_ebp 就是 inline的
}
}
Lab 6 中断服务的建立
中断与异常
由三种特殊的中断事件. 由CPU外部设备引起的外部事件如I/O 中断,时钟中断,控制台终端等 是异步产生的(即产生的时刻不确定),我们称之为异步中断(asynchronous interrupt) 也称为外部中断 简称中断
而把在CPU执行指令期间检测到不正常的或非法的条件(如除零错、地址访问越界)所引起的内部事件称作同步中断(synchronous interrupt),也称内部中断,简称异常(exception)。
。把在程序中使用请求系统服务的系统调用而引发的事件,称作陷入中断(trap interrupt),也称软中断(soft interrupt),系统调用(system call)简称trap。在后续试验中会进一步讲解系统调用。
本实验只描述保护模式下的处理过程。当CPU收到中断(通过8259A完成,有关8259A的信息请看附录A)或者异常的事件时,它会暂停执行当前的程序或任务,通过一定的机制跳转到负责处理这个信号的相关处理例程中,在完成对这个事件的处理后再跳回到刚才被打断的程序或任务中。中断向量和中断服务例程的对应关系主要是由IDT(中断描述符表)负责。操作系统在IDT中设置好各种中断向量对应的中断描述符,留待CPU在产生中断后查询对应中断服务例程的起始地址。而IDT本身的起始地址保存在idtr寄存器中。
(1) 中断描述符表(Interrupt Descriptor Table) 中断描述符表把每个中断或异常编号和一个指向中断服务例程的描述符联系起来。同GDT一样,IDT是一个8字节的描述符数组,(GDT 第一个条则是空段描述符)但IDT的第一项可以包含一个描述符。CPU把中断(异常)号乘以8做为IDT的索引。IDT可以位于内存的任意位置,CPU通过IDT寄存器(IDTR)的内容来寻址IDT的起始地址。指令LIDT和SIDT用来操作IDTR。两条指令都有一个显示的操作数:一个6字节表示的内存地址。指令的含义如下:
LIDT(Load IDT Register)指令:使用一个包含线性地址基址和界限的内存操作数来加载IDT。操作系统创建IDT时需要执行它来设定IDT的起始地址。这条指令只能在特权级0执行。(可参见libs/x86.h中的lidt函数实现,其实就是一条汇编指令)
SIDT(Store IDT Register)指令:拷贝IDTR的基址和界限部分到一个内存地址。这条指令可以在任意特权级执行。
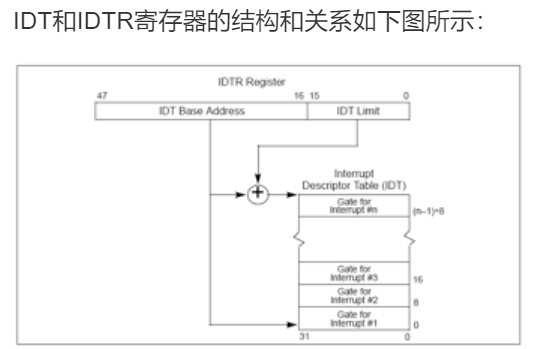
在保护模式下,最多会存在256个Interrupt/Exception Vectors。范围[0,31]内的32个向量被异常Exception和NMI使用,但当前并非所有这32个向量都已经被使用,有几个当前没有被使用的,请不要擅自使用它们,它们被保留,以备将来可能增加新的Exception。范围[32,255]内的向量被保留给用户定义的Interrupts。Intel没有定义,也没有保留这些Interrupts。用户可以将它们用作外部I/O设备中断(8259A IRQ),或者系统调用(System Call 、Software Interrupts)等。
(2) IDt gate descriptors
Interrupts/Exceptions应该使用Interrupt Gate和Trap Gate,它们之间的唯一区别就是:当调用Interrupt Gate时,Interrupt会被CPU自动禁止;而调用Trap Gate时,CPU则不会去禁止或打开中断,而是保留它原来的样子。
【补充】所谓“自动禁止”,指的是CPU跳转到interrupt gate里的地址时,在将EFLAGS保存到栈上之后,清除EFLAGS里的IF位,以避免重复触发中断。在中断处理例程里,操作系统可以将EFLAGS里的IF设上,从而允许嵌套中断。但是必须在此之前做好处理嵌套中断的必要准备,如保存必要的寄存器等。二在ucore中访问Trap Gate的目的是为了实现系统调用。用户进程在正常执行中是不能禁止中断的,而当它发出系统调用后,将通过Trap Gate完成了从用户态(ring 3)的用户进程进了核心态(ring 0)的OS kernel。如果在到达OS kernel后禁止EFLAGS里的IF位,第一没意义(因为不会出现嵌套系统调用的情况),第二还会导致某些中断得不到及时响应,所以调用Trap Gate时,CPU则不会去禁止中断。总之,interrupt gate和trap gate之间没有优先级之分,仅仅是CPU在处理中断时有不同的方法,供操作系统在实现时根据需要进行选择。
在IDT中,可以包含如下3种类型的Descriptor:
Task-gate descriptor (这里没有使用)
Interrupt-gate descriptor (中断方式用到)
Trap-gate descriptor(系统调用用到)
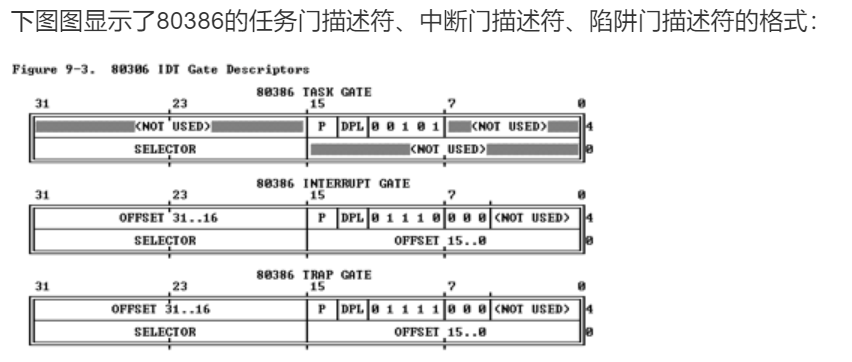
图9 X86的各种门的格式
可参见kern/mm/mmu.h中的struct gatedesc数据结构对中断描述符的具体定义。
(3) 中断处理中硬件负责完成的工作
中断服务例程包括具体负责处理中断(异常)的代码是操作系统的重要组成部分。需要注意区别的是,有两个过程由硬件完成:
硬件中断处理过程1(起始):从CPU收到中断事件后,打断当前程序或任务的执行,根据某种机制跳转到中断服务例程去执行的过程。其具体流程如下:
CPU在执行完当前程序的每一条指令后,都会去确认在执行刚才的指令过程中中断控制器(如:8259A)是否发送中断请求过来,如果有那么CPU就会在相应的时钟脉冲到来时从总线上读取中断请求对应的中断向量;
CPU根据得到的中断向量(以此为索引)到IDT中找到该向量对应的中断描述符,中断描述符里保存着中断服务例程的段选择子;
CPU使用IDT查到的中断服务例程的段选择子从GDT中取得相应的段描述符,段描述符里保存了中断服务例程的段基址和属性信息,此时CPU就得到了中断服务例程的起始地址,并跳转到该地址;
CPU会根据CPL和中断服务例程的段描述符的DPL信息确认是否发生了特权级的转换。比如当前程序正运行在用户态,而中断程序是运行在内核态的,则意味着发生了特权级的转换,这时CPU会从当前程序的TSS信息(该信息在内存中的起始地址存在TR寄存器中)里取得该程序的内核栈地址,即包括内核态的ss和esp的值,并立即将系统当前使用的栈切换成新的内核栈。这个栈就是即将运行的中断服务程序要使用的栈。紧接着就将当前程序使用的用户态的ss和esp压到新的内核栈中保存起来;
CPU需要开始保存当前被打断的程序的现场(即一些寄存器的值),以便于将来恢复被打断的程序继续执行。这需要利用内核栈来保存相关现场信息,即依次压入当前被打断程序使用的eflags,cs,eip,errorCode(如果是有错误码的异常)信息;
CPU利用中断服务例程的段描述符将其第一条指令的地址加载到cs和eip寄存器中,开始执行中断服务例程。这意味着先前的程序被暂停执行,中断服务程序正式开始工作。
硬件中断处理过程2(结束):每个中断服务例程在有中断处理工作完成后需要通过iret(或iretd)指令恢复被打断的程序的执行。CPU执行IRET指令的具体过程如下:
程序执行这条iret指令时,首先会从内核栈里弹出先前保存的被打断的程序的现场信息,即eflags,cs,eip重新开始执行;
如果存在特权级转换(从内核态转换到用户态),则还需要从内核栈中弹出用户态栈的ss和esp,这样也意味着栈也被切换回原先使用的用户态的栈了;
如果此次处理的是带有错误码(errorCode)的异常,CPU在恢复先前程序的现场时,并不会弹出errorCode。这一步需要通过软件完成,即要求相关的中断服务例程在调用iret返回之前添加出栈代码主动弹出errorCode。
下图显示了从中断向量到GDT中相应中断服务程序起始位置的定位方式

1
中断描述符表(也可简称为保护模式下的中断向量表)中一个表项占多少字节?其中哪几位代表中断处理代码的入口?
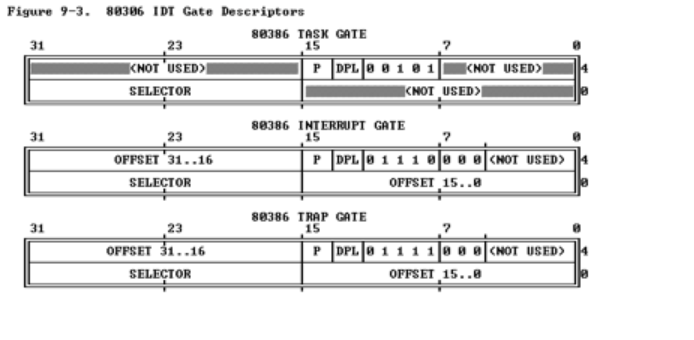
8个字节,从图来看对于 interrupt gate 来说0..15 到48-63 是偏移
16-31是段选择子
实现##
手动给的生成了 汇编文件 vector.s
在vector 文件中声明了变量 __vector
已经有了地址
使用SETGATE 宏进行设计就Ok
助教解答:trap gate与interrupt gate的唯一区别,是调用interrupt gate里的handler前会清EFLAGS的IF位(即关中断),而调用trap gate的handler时对IF位没有影响。
GD_ETEXT 的乘8操作 ,是为了选择到对应的段描述符。
Intel CPU设计时,认为设置4级特权级可以适应更多的应用方式。但当前的主流OS只用了两个特权级,内核态(0级)和用户态(3级)就满足了需求。1,2特权级一般就没啥人用了。
结论:多看pizza,多读
这里同样的使用lidt 的时候传入的是一个 界限和基址 所以不止是基址要注意