1、关于编码方式
1.1简单认识几种编码格式
python3.X默认编码格式是UTF-8。ASCII码(python2.X默认编码格式)只适用于美国,GBK只适用于中文,UNICODE和UTF-8兼容全部的字符类型。
详细查看https://www.cnblogs.com/txbbkk/p/9291971.html
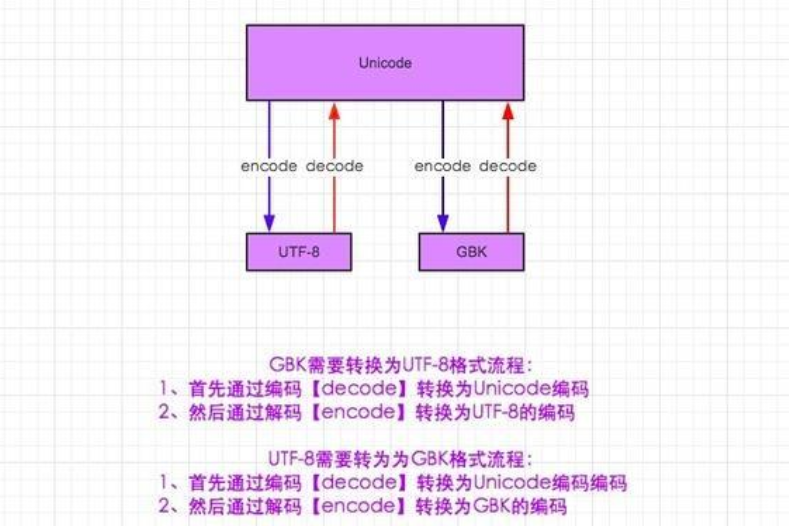
我们在处理不同文件和不同来源的数据过程中,可能碰到多种编码格式的数据,处理方法是:1、通过编码【decode】将当前字符类型转化为unicode,2、通过解码【encode】将unicode字符类型转化为目标类型,如下图:
1.2、查看字符串的编码方式
1.3、不同的编码类型转换
import sys
import chardet
print(sys.getdefaultencoding()) #获取系统默认编码格式:utf-8
s = "你好" #utf-8
print(s,chardet.detect(str.encode(s)))
s_gbk = s.encode('gbk') #编码到gbk???
s_utf_8 = s.encode('utf-8') #编码到utf-8
print(s_gbk,chardet.detect(s_gbk))
print(s_utf_8,chardet.detect(s_utf_8))
print(s_gbk.decode('gbk')) #解码到utf-8
print(s_utf_8.decode('utf-8')) #解码到utf-8
2、其他
建议代码中涉及到中文的字符串前面加一个n,比如 n'天蝎座',这样就不会因为编码方式不同而出现乱码