整理了Node.js、PHP、Go、JAVA、Ruby、Python等语言的爬虫框架。不知道读者们都用过什么爬虫框架?爬虫框架的哪些点你觉得好?哪些点觉得不好?

Node.js
- node-crawler

https://github.com/bda-research/node-crawler
Github stars = 3802
北京bda资讯公司数据团队的作品
优点:
- 天生支持非阻塞异步IO
- 支持对 DOM 快速选择
- 符合jQuery语法的选择器功能(默认使用Cheerio)
- 支持连接池模式,并发数和重连数均可配置
- 支持请求队列的优先权(即不同URL的请求能有不同的优先级)
- 支持延时功能(某些服务器对每分钟内连接数有限制)
- 支持 forceUTF8 模式以应对复杂的编码问题,当然你也可以自己为不同的连接设置编码
关于V8引擎
- 一个完整JavaScript引擎的执行过程大致流程如下:源代码-→抽象语法树-→字节码-→JIT(JIT编译器)-→本地代码
- 在V8引擎中,源代码先被解析器转变为抽象语法树(AST),然后使用JIT编译器的全代码生成器从AST直接生成本地可执行代码。
PHP
- QueryList

https://github.com/jae-jae/QueryList
Github stars = 1016
特点
- 拥有与jQuery完全相同的CSS3 DOM选择器
- 拥有与jQuery完全相同的DOM操作API
- 拥有通用的列表采集方案
- 拥有强大的HTTP请求套件,轻松实现如:模拟登陆、伪造浏览器、HTTP代理等意复杂的网络请求
- 拥有乱码解决方案
- 拥有强大的内容过滤功能,可使用jQuey选择器来过滤内容
- 拥有高度的模块化设计,扩展性强
- 拥有富有表现力的API
- 拥有高质量文档
- 拥有丰富的插件
- 拥有专业的问答社区和交流群
Go
- Colly

https://github.com/gocolly/colly
Github stars = 5065
Features
- Clean API
- Fast (>1k request/sec on a single core)
- Manages request delays and maximum concurrency per domain
- Automatic cookie and session handling
- Sync/async/parallel scraping
- Distributed scraping
- Caching
- Automatic encoding of non-unicode responses
- Robots.txt support
- Google App Engine support

- Pholcus
https://github.com/henrylee2cn/pholcus
GitHub stars = 4089
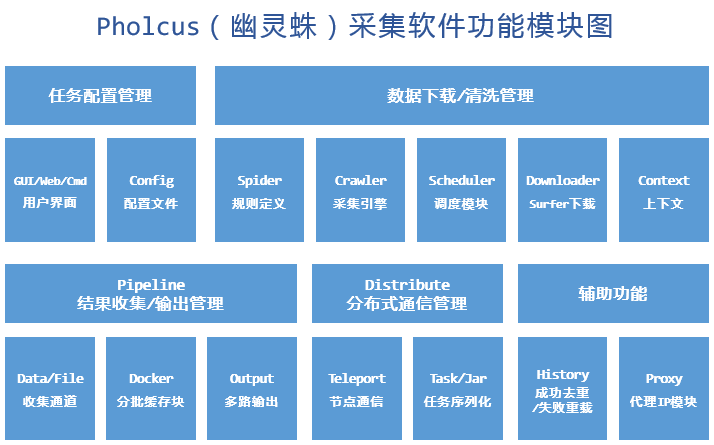
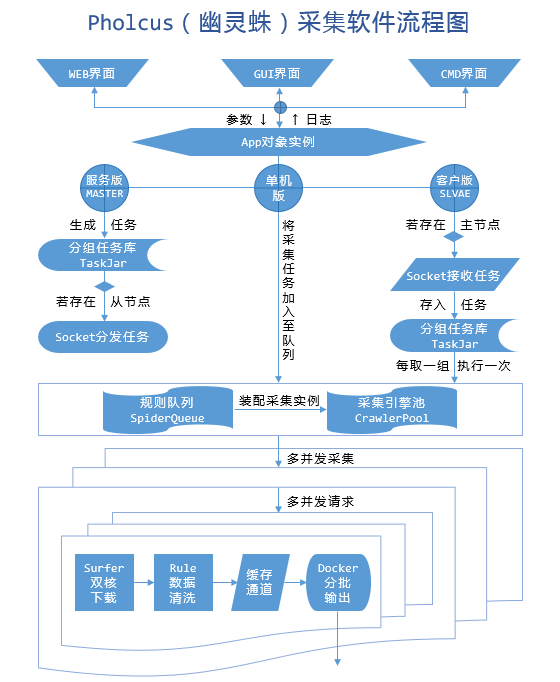
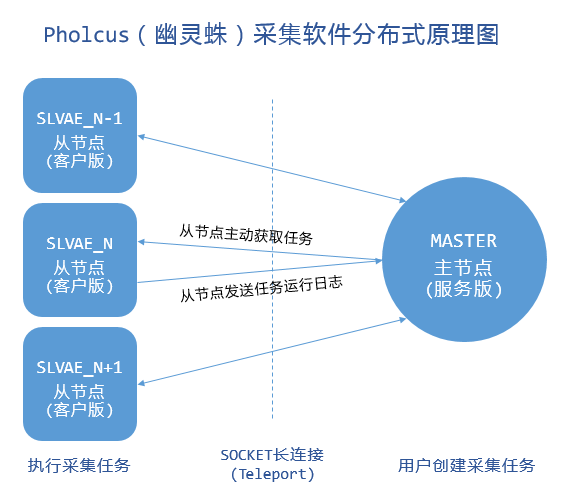
支持单机、服务端、客户端三种运行模式,拥有Web、GUI、命令行三种操作界面;规则简单灵活、批量任务并发、输出方式丰富(mysql/mongodb/kafka/csv/excel等)、有大量Demo共享;另外它还支持横纵向两种抓取模式,支持模拟登录和任务暂停、取消等一系列高级功能。
框架特点
- 为具备一定Go或JS编程基础的用户提供只需关注规则定制、功能完备的重量级爬虫工具;
- 支持单机、服务端、客户端三种运行模式;
- GUI(Windows)、Web、Cmd 三种操作界面,可通过参数控制打开方式;
- 支持状态控制,如暂停、恢复、停止等;
- 可控制采集量;
- 可控制并发协程数;
- 支持多采集任务并发执行;
- 支持代理IP列表,可控制更换频率;
- 支持采集过程随机停歇,模拟人工行为;
- 根据规则需求,提供自定义配置输入接口
- 有mysql、mongodb、kafka、csv、excel、原文件下载共五种输出方式;
- 支持分批输出,且每批数量可控;
- 支持静态Go和动态JS两种采集规则,支持横纵向两种抓取模式,且有大量Demo;
- 持久化成功记录,便于自动去重;
- 序列化失败请求,支持反序列化自动重载处理;
- 采用surfer高并发下载器,支持 GET/POST/HEAD 方法及 http/https 协议,同时支持固定UserAgent自动保存cookie与随机大量UserAgent禁用cookie两种模式,高度模拟浏览器行为,可实现模拟登录等功能;
- 服务器/客户端模式采用Teleport高并发SocketAPI框架,全双工长连接通信,内部数据传输格式为JSON。
JAVA
- webmagic
https://github.com/code4craft/webmagic
Github stars = 6643

webmagic的主要特色:
- 完全模块化的设计,强大的可扩展性。
- 核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。
- 提供丰富的抽取页面API。
- 无配置,但是可通过POJO+注解形式实现一个爬虫。
- 支持多线程。
- 支持分布式。
- 支持爬取js动态渲染的页面。
- 无框架依赖,可以灵活的嵌入到项目中去。
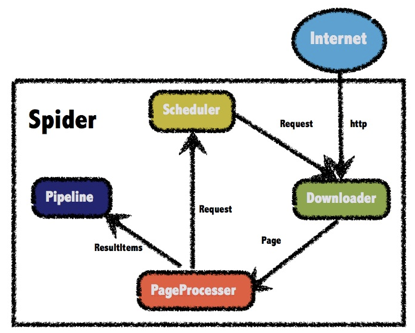
WebMagic的四个组件:
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
- crawler4j
https://github.com/yasserg/crawler4j
GitHub stars = 2944
没有文档,只有git
优点
- 多线程采集
- 内置了Url 过滤机制,采用的是BerkeleyDB 进行url的过滤。
- 可扩展为支持结构化提取网页字段,可作为垂直采集用
- WebCollector
https://github.com/CrawlScript/WebCollector
GitHub stars = 1883
没有文档,只有git
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
- Nutch
https://github.com/apache/nutch
GitHub stars = 1703
Features
- Fetching and parsing are done separately by default, this reduces the risk of an error corrupting the fetch parse stage of a crawl with Nutch.
- Plugins have been overhauled as a direct result of removal of legacy Lucene dependency for indexing and search.
- The number of plugins for processing various document types being shipped with Nutch has been refined. Plain text, XML, OpenDocument (OpenOffice.org), Microsoft Office (Word, Excel, Powerpoint), PDF, RTF, MP3 (ID3 tags) are all now parsed by the Tika plugin. The only parser plugins shipped with Nutch now are Feed (RSS/Atom), HTML, Ext, JavaScript, SWF, Tika & ZIP.
- MapReduce ;
- Distributed filesystem (via Hadoop)
- Link-graph database
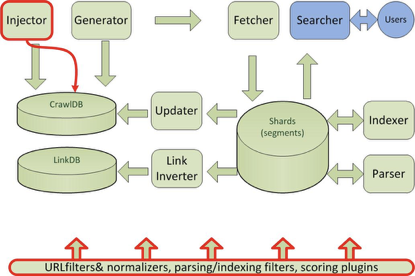
Nutch的优缺点
优点:
Nutch支持分布式抓取,并有Hadoop支持,可以进行多机分布抓取,存储和索引。另外很吸引人的一点在于,它提供了一种插件框架,使得其对各种网页内容的解析、各种数据的采集、查询、集群、过滤等功能能够方便的进行扩展,正是由于有此框架,使得 Nutch 的插件开发非常容易,第三方的插件也层出不穷,极大的增强了 Nutch 的功能和声誉。
缺点:
Nutch的爬虫定制能力比较弱
- heritrix3
https://github.com/internetarchive/heritrix3
GitHub stars = 1192
特点
- 能够同时运行多个抓取任务,唯一的限制是要给并行运行的抓取任务分配内存.
- 基于Spring框架去管理XML配置.并且只用这一个XML配置就替换Hertrix1.X的order.xml和其他配置文件.
- 可以通过浏览器工具很方便易用的浏览和修改Spring Bean.
- 增强扩展了Spring框架.可以配置得很细致.具体见Sheets.
- 更安全的控制台限制.通过HTTPS去访问和操作控制台.
- 增强了扩展性.以前的版本,如果有千万级以上的种子都会先载入内存,如此有可能使得超过分配给Heritrix的内存导致内存溢出.Heririx3.0则解决了这个问题.允许这种大规模抓取.
- 可以灵活的修改一个正在运行的抓取任务.通过修改Bean和Action Directory两种方式来修改.
- 引入了并行队列.当抓取指定的站点以前只有一个队列,如此会导致该队列的过于庞大.和抓取缓慢.并行队列的话,会将同一个站点的URL分成多个队列去并行抓取.
- 增加了脚本控制台,可以通过输入各种各样的脚本,如AppleScript,ECMAScript,Python,JS去控制和访问Heritrix的基本组件运行情况(很有意思).
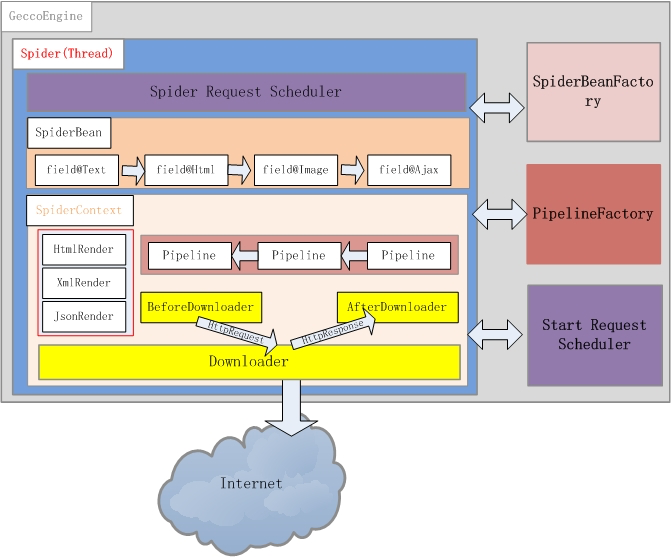
- Gecco
https://github.com/xtuhcy/gecco
GitHub stars = 1171
主要特征
- 简单易用,使用jquery风格的选择器抽取元素
- 支持爬取规则的动态配置和加载
- 支持页面中的异步ajax请求
- 支持页面中的javascript变量抽取
- 利用Redis实现分布式抓取,参考gecco-redis
- 支持结合Spring开发业务逻辑,参考gecco-spring
- 支持htmlunit扩展,参考gecco-htmlunit
- 支持插件扩展机制
- 支持下载时UserAgent随机选取
- 支持下载代理服务器随机选取
Ruby
Wombat
https://github.com/felipecsl/wombat
Github stars = 1083
Wombat is a simple ruby DSL to scrape webpages on top of the cool Mechanize and Nokogiri gems. It is aimed to be a more high level abstraction if you dont want to dig into the specifics of getting the page and parsing it into your own data structure, which can be a decent amount of work, depending on what you need.
最后,Python
- Scrapy
https://github.com/scrapy/scrapy
GitHub stars = 27682
- 内建的CSS选择器和XPath表达式
- 基于IPython交互式shell,方便编写爬虫和debug
- 内建的文件导出和保存方法,格式多样JSON、CSV、XML
- 健壮的编码支持
- 扩展性强,可以使用signals和API(中间件、插件、管道)添加自定义功能
- 多种用于处理session、cookies、HTTP认证、user-agent、robots.txt、抓取深度限制的中间件和插件
- Scrapy内建Telnet console,可用于debug
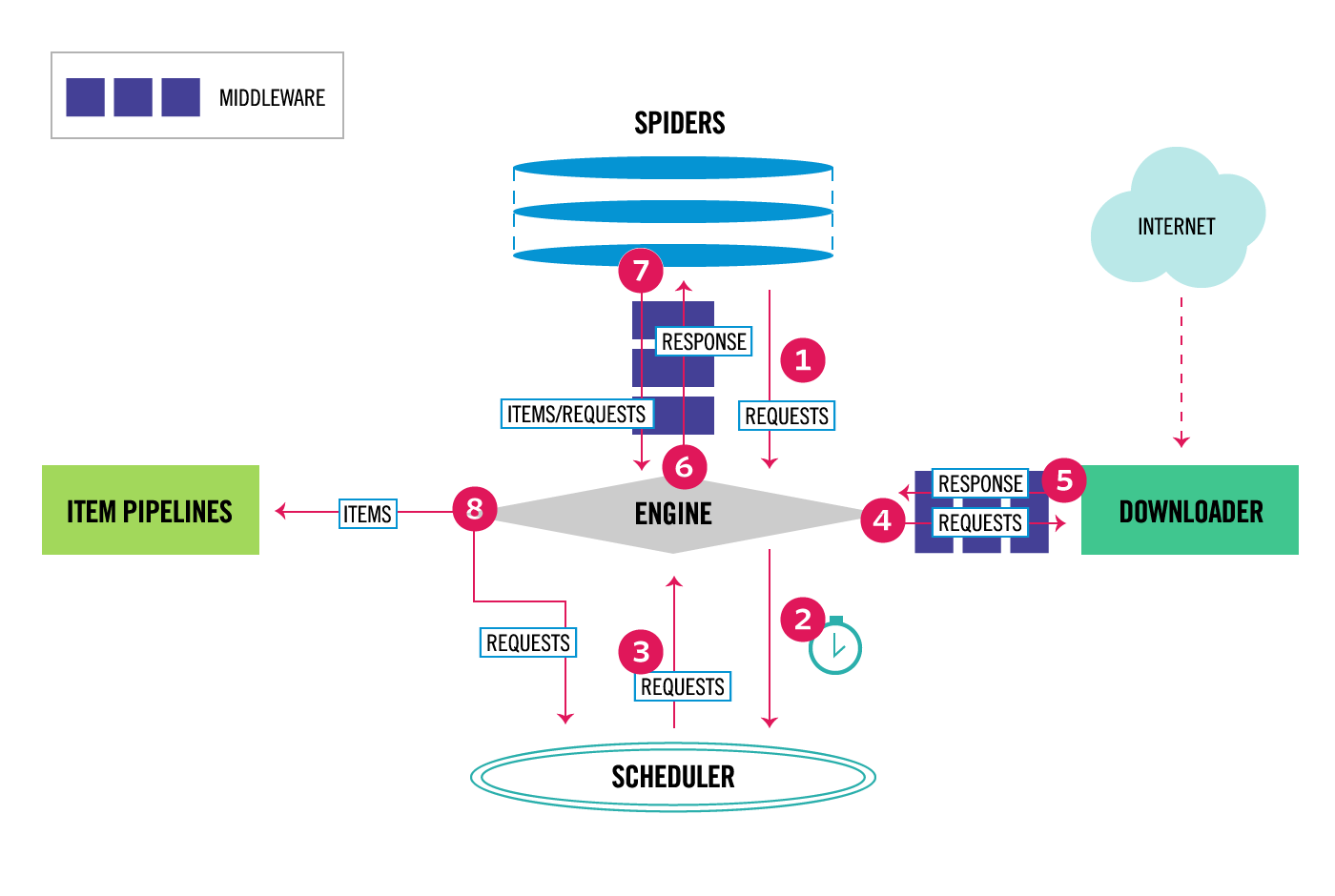
- PySpider
https://github.com/binux/pyspider
GitHub star = 11418
特点
- Powerful WebUI with script editor, task monitor, project manager and result viewer
- MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL with SQLAlchemy as database backend
- RabbitMQ, Beanstalk, Redis and Kombu as message queue
- Task priority, retry, periodical, recrawl by age, etc...
- Distributed architecture, Crawl Javascript pages, Python 2.{6,7}, 3.{3,4,5,6} support, etc...
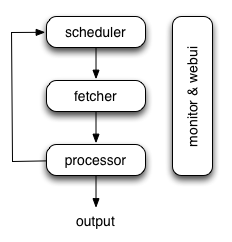
Scheduler
The Scheduler receives tasks from newtask_queue from processor. Decide whether the task is new or requires re-crawl. Sort tasks according to priority and feeding them to fetcher with traffic control (token bucket algorithm). Take care of periodic tasks, lost tasks and failed tasks and retry later.
Note that in current implement of scheduler, only one scheduler is allowed.
Scheduler
The Scheduler receives tasks from newtask_queue from processor. Decide whether the task is new or requires re-crawl. Sort tasks according to priority and feeding them to fetcher with traffic control (token bucket algorithm). Take care of periodic tasks, lost tasks and failed tasks and retry later.
Processor
The Processor is responsible for running the script written by users to parse and extract information. Your script is running in an unlimited environment. Although we have various tools(like PyQuery) for you to extract information and links, you can use anything you want to deal with the response. You may refer to Script Environment and API Reference to get more information about script.
Result Worker (optional)
Result worker receives results from Processor. Pyspider has a built-in result worker to save result to resultdb. Overwrite it to deal with result by your needs.
WebUI
WebUI is a web frontend for everything. It contains:
- script editor, debugger
- project manager
- task monitor
- result viewer, exporter
Maybe webui is the most attractive part of pyspider. With this powerful UI, you can debug your scripts step by step just as pyspider do. Starting or stop a project. Finding which project is going wrong and what request is failed and try it again with debugger.
- Newspaper
https://github.com/codelucas/newspaper
GitHub star = 6386
下面这个demo站,可以展示提取标题、正文、关键词等信息。
http://newspaper-demo.herokuapp.com
Features
- Multi-threaded article download framework
- News url identification
- Text extraction from html
- Top image extraction from html
- All image extraction from html
- Keyword extraction from text
- Summary extraction from text
- Author extraction from text
- Google trending terms extraction
- Works in 10+ languages (English, Chinese, German, Arabic, …)
