一、前言
最近由于疫情影响,时间比较多,所以开始学习之前一直想学,但是却没时间学的Redis。这两天研究了一下Redis的持久化以及主从复制机制,现在已经很晚了,就不多废话了。这篇博客就来谈一谈Redis的主从复制机制。在这里需要提醒一下,主从复制依赖于Redis的快照持久化(RDB),所以如果不了解持久化,请先去研究那一块的内容,可以看看这篇博客:详细分析Redis的持久化操作—RDB与AOF。
二、正文
2.1 什么是主从复制
首先我们来谈一谈最基本的问题——什么是主从复制,为什么需要它?我们知道,现在的应用基本上都会使用集群进行部署,同一个应用部署在多台服务器上,各台服务器互相同步,各自承担一部分任务,以此来减轻单台服务器的压力。而主从复制就是Redis用来对存储相同数据的多台服务器进行同步的机制。
假设我们只在一台服务器上部署了Redis服务器,那所有需要访问Redis服务器的请求,都需要这一台服务器来处理,这对服务器来说有很大的压力。如果访问的很频繁,那么一台服务器根本处理不过来,所以我们需要多台服务器同时部署Redis,然后每一台服务器承担一部分任务。
如果我们部署了多台Redis服务器,存储相同的数据,为同一个应用进行服务,那么不难想到,我们需要处理一个问题——数据同步。我们必须保证这多台服务器的Redis数据库中,存储的数据是一致的,而且都应该是正确的数据,否则将会导致对请求进行错误的处理,比如查询出的是过期的数据,或者对已经过期的数据进行了修改。而主从复制,就是Redis对这多台服务器进行数据同步的机制。
在主从复制机制中,Redis将服务器分为主服务器和从服务器,主服务器负责接收用户提交的修改指令,修改数据库中的数据,同时将修改同步到从服务器中,而从服务器的任务就是与主服务器进行数据同步,并分担本应该由主服务器执行的查询请求,减小主服务器的压力,除此之外,为了减轻主服务器的压力,我们也可以关闭主服务器的持久化操作,而让从服务器来进行持久化。
2.2 主从复制的实现过程
完整的主从复制包含以下两步:
- 同步:将从服务器当前的状态,更新为主服务器当前的状态,也就是使用主服务器中存储的数据,替换掉从服务器的数据;
- 命令传播:主服务器执行每一次修改操作后,都需要告知从服务器,让从服务器执行相同的操作,以保证一致性;
下面我就来分别分析一下这两个过程的详细实现。
2.3 同步的实现原理
从服务器与主服务器同步,需要使用到SYNC指令,详细的执行流程如下:
- 从服务器连接到主服务器,并向主服务器发送
SYNC指令; - 主服务器接收到
SYNC指令后,开始执行BGSAVE指令(快照持久化),此时主服务器将调用fock(),创建一个子进程,子进程去生成Redis当前状态的一个快照;在这个过程中,新到达主服务器的写指令将会被记录在缓冲区; - 主服务器执行完
BGSAVE后,将快照文件发送给从服务器,在发送的过程中,如果还有新的写指令到达,也会继续记录在缓冲区;从服务器接收到主服务器发来的快照文件后,将丢弃自己内存中的数据,开始加载快照文件中记录的数据,加载完成后,就可以处理接收到的请求了; - 主服务器在发送完快照文件后,开始将缓冲区中记录的写指令也同步到从服务器;从服务器接收到主服务器发来的指令,便依次执行这些指令,执行完后,就与主服务器的状态一致了;
2.4 命令传播的实现原理
为什么需要命令传播?这个应该很好理解。经过上面的同步后,主服务器与从服务器存储的数据就一致了,这之后,从服务器就可以分担查询操作,但是写操作还是需要主服务器完成。所以,虽然当前主从服务器已经一致,但是主服务器如果执行了一次写操作,而从服务器没有执行,它们又将变成不一致的状态。而命令传播的实现原理很简单:主服务器每次执行写操作,都会将这个写指令发送给从服务器,从服务器接收到后,也执行这个写指令,这样就能让主服务器和从服务器持续的保持一致。
有人可能会想,为什么是将指令发送到从服务器,而不是重新执行一次同步操作呢?答案很简单,因为上面的同步操作,需要很大的开销。执行BGSAVE指令创建快照,需要创建一个子进程,同时生成一个文件,需要进行大量的磁盘IO,在数据量很大的情况下,可能会使主服务器产生数毫秒甚至是一秒的停顿。而向从服务器传输一个指令的开销,要比上面的同步小得多。
2.5 部分重同步介绍
以上介绍的主从复制过程,是一个开销非常大,而且比较耗时的操作(主要是同步过程耗时),于是从Redis2.8开始,提供了一种优化机制——部分重同步。我们考虑这样一种情况,假设一台从服务器已经与主服务器完成了同步,进入了命令传播阶段,但是由于某些原因,主从服务器之间的网络连接断开了,从服务器在一段时间后,重新连接上了主服务器。按理来说,从服务器和主服务器断开连接的这段时间,没有同步对主服务器的写操作,此时它们已经不一致了,那么从服务器需要重新执行一次主从复制,这又是一次非常耗时的操作。而Redis2.8之后,提供了一种优化机制,若在上面的情况发生时,如果满足某些条件(具体条件之后叙述),可以不进行一次完整的主从复制,而是只同步断开连接的这段时间里,没有同步的操作,这就是部分重同步。
Redis2.8之后,提供了一个新的指令来实现部分重同步,这个指令就是PSYNC。从2.8开始,实现主从复制使用的就不是SYNC了,而是PSYNC,它可以算是SYNC的升级版本。PSYNC支持两种模式:
- 完整重同步:如果
Redis判断当前从服务器需要与主服务器重新进行一次完整的主从复制,则PSYNC指令将执行与SYNC指令完全一样的操作,上面已经描述过了,这里就不重复叙述了; - 部分重同步:若从服务器与主服务器断线重连后,满足某些条件,则不进行完整重同步,而是只同步断线过程中,没有同步的部分;
2.6 部分重同步的实现原理
下面我们就来详细分析一下,部分重同步是如何实现的。部分重同步需要依赖以下三个部分:
- 服务器的运行
id; - 主服务器的复制积压缓冲区;
- 主从服务器的复制偏移量;
(1)服务器的运行 id
每一台服务器都会被分配一个运行id,用来标识服务器的身份。从服务器在与一台主服务器连接后,会记录主服务器的id。从服务器与主服务器断开后,可能会重新连接一台主服务器,但是并不一定就是原来的那一台。当从服务器连接到一台主服务器后,会向主服务器发送自己记录的主服务器id,主服务器判断这是不是自己,如果是,表明从服务器之前连接的就是自己,则有可能可以使用部分重同步机制,否则,将重新进行一次完整同步。
(2)主服务器的复制积压缓冲区
首先,复制积压缓冲区是一个固定长度,先进先出的队列,默认 1MB。主服务器在接收到用户发来的写指令时,不仅仅会将写指令发送给从服务器进行同步,同时还会将这个指令放入到复制积压缓冲区中,目的是在从服务器没有成功接收到的时候能够重传。复制缓冲区的结构大致如下:
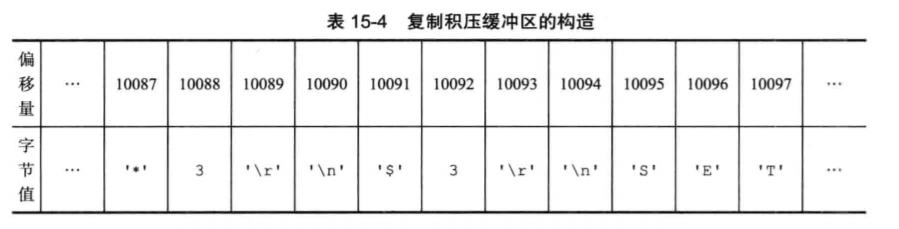
可以看到,对于复制积压缓冲区中的每一个字节,都有一个对应的偏移量。如果当前缓冲区已经满了,但是又有新的指令需要放入其中,则会将最先放入其中的指令移除,腾出足够空间后,将新指令放入,也就是LRU算法(最近最久未使用),所以,缓冲区中能够存储的指令是有限的。
(3)主从服务器的复制偏移量
主服务器和从服务器会分别维护自己的复制偏移量,主服务器每发送出一个字节,主服务器偏移量就+1,而从服务器每完成一个字节的同步,从服务器偏移量就+1。
什么情况下会触发部分重同步呢?答案就是:若从服务器与主服务器断开连接,并重新连接到同一个主服务器后,会将自己记录的复制偏移量发送给主服务器,主服务器判断这个偏移量之后的所有字节,是否还在复制缓冲区中,如果在,则表明可以进行部分重同步,将复制缓冲区中,这个偏移量之后的所有字节发送给从服务器;若不完全包含,则表明从服务器需要同步的数据,有一部分无法在缓冲区中找到,此时就需要进行一次完整同步。
2.7 配置从服务器
下面讲一讲如何将一台Redis服务器,配置为从服务器,有两种方式:
(1)配置文件
可以在配置Redis的配置文件中,加入以下配置项:
slaveof 主服务器ip 主服务器端口
在配置文件中配置了上面这一行,则当前服务器就是一台从服务器,它启动时,就会尝试区连接上面上面这个配置项指定好的主服务器,并在连接成功后发送PSYNC指令,完成之前介绍的步骤。
(2)指令
第二种方式就是使用指令,在Redis服务器输入下面这一行指令,当前服务器就会作为一个从服务器,尝试连接主服务器,并进行主从复制:
127.0.0.1:6379> SLAVEOF 主服务器ip 主服务器端口
2.8 主从复制的安全性
在使用Redis 复制功能时的设置中,强烈建议在 主服务器 和 从服务器 中启用持久化。当不可能启用时,例如由于非常慢的磁盘性能而导致的延迟问题,应该配置实例来避免重置后自动重启。
为了更好地理解为什么关闭了持久化并配置了自动重启的 主服务器 是危险的,检查以下故障模式,这些故障模式中数据会从 主服务器 和所有 从服务器 中被删除:
- 我们设置节点
A为 主服务器 并关闭它的持久化设置,节点B和C从 节点A复制数据。 - 节点
A崩溃,但是他有一些自动重启的系统可以重启进程。但是由于持久化被关闭了,节点重启后其数据集合为空。 - 节点
B和 节点C会从节点A复制数据,但是节点A的数据集是空的,因此复制的结果是它们会销毁自身之前的数据副本。
当 Redis Sentinel 被用于高可用并且 主服务器 关闭持久化,这时如果允许自动重启进程也是很危险的。例如, 主服务器 可以重启的足够快以致于 Sentinel 没有探测到故障,因此上述的故障模式也会发生。任何时候数据安全性都是很重要的,所以如果 主服务器 使用复制功能的同时未配置持久化,那么自动重启进程这项应该被禁用。
三、总结
以上就对Redis的主从复制做了一个比较详细的描述,时间太晚了,就不说别的了,希望能够为需要的人答疑解惑吧。