一 redis 数据格式
- 短连接 长连接pconnect
- tcp协议
- 交互数据格式
交互采用特殊的格式1."+"号开头表示单行字符串的回复set aa aa 返回的格式就是 +OK2."-"号开头表示错误的信息回复。ss ss 返回的格式就是-ERR unknown command 'ss'3.":"号开头表示一个整数回复。 如":0 "del aa返回的格式就是 存在 :1 不存在 :04."$"号开头表示一个批量的回复。如GET mykey get aa *2 $3 get $2aa返回$2aa5."*"号开头表示多个批量回复。如GET mykey get aa *2 $3 get $2aa
- pipe 模型
*3 起始命令表示有3个参数
$3 表示下一个命令参数长度为3
set 参数命令
$2 表示下一个命令参数长度为2
aa
$4 表示下一个命令参数长度为4
bbbb
利用这种格式我们可以将数据库中的直接插入redis中
##商品活动 select CONCAT('*4 $4 hset $',LENGTH(concat('p_white_',item_id)),' p_white_',item_id,' $',LENGTH(promotion_id),' ',promotion_id,' ' , '$' , LENGTH(promotion_id) , ' ' , promotion_id , ' ') from ( SELECT i.sku as item_id , i.promotion_id as promotion_id from mia_test2.promotion as p,mia_test2.promotion_items as i where p.end_time>=now() and p.status=3 and p.id = i.promotion_id and i.status=0 )as t; mysql -uxxx -pxxx -hxxx --default-character-set=utf8 --skip-column-names --raw < aa.sql| redis-cli -h 172.16.104.236 -p 6379 --pipe #300w数据 半分钟导入
二 redis 执行流程
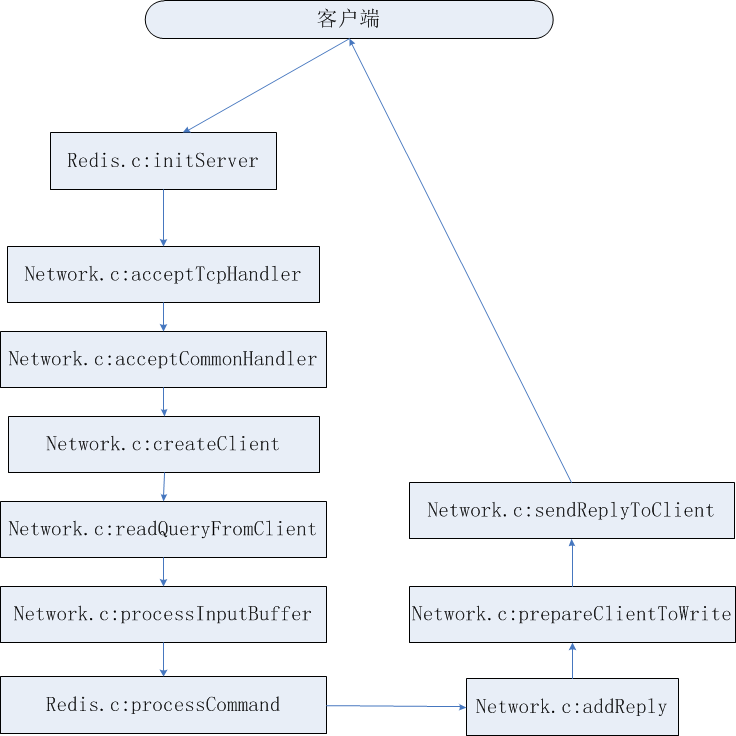
processInputBuffer 解析协议->processInlineBuffer processMultibulkBuffer协议
addReply 是一个list 他会返回结果不断的追加到链表(缓冲区)中,最后输出一起刷新给客户端
三 redis 主从
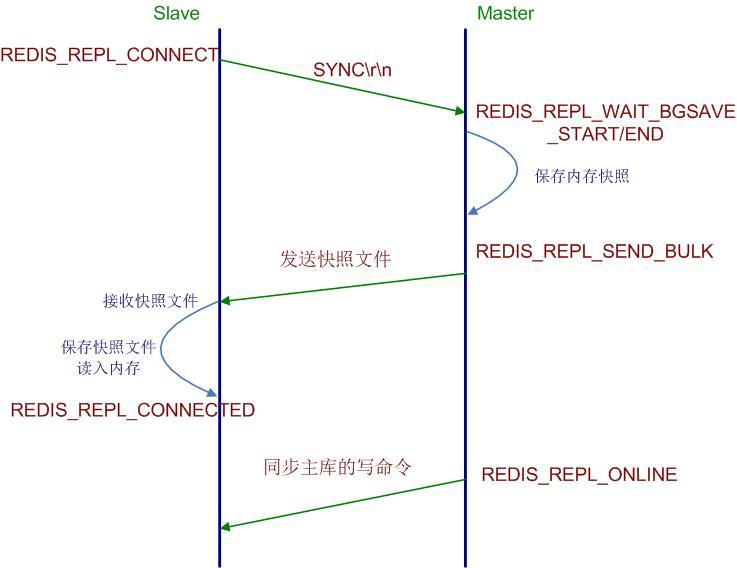
- Slave端在配置文件中添加了slave of指令,于是Slave启动时读取配置文件,初始状态为REDIS_REPL_CONNECT。
- Slave端在定时任务serverCron(Redis内部的定时器触发事件)中连接Master,发送sync命令,然后阻塞等待master发送回其内存快照文件(2.8+Redis已经不需要让Slave阻塞,此时client 读取的是历史数据)。
- Master端收到sync命令简单判断是否有正在进行的内存快照子进程,没有则立即开始内存快照,有则等待其结束,当快照完成后会将该文件发送给Slave端。
- Slave端接收Master发来的内存快照文件,保存到本地,待接收完成后,清空内存表,重新读取Master发来的内存快照文件,重建整个内存表数据结构,并最终状态置位为 REDIS_REPL_CONNECTED状态,Slave状态机流转完成。(重建整个内存数据结构的时候,slave是阻塞状态,client连接redis 将产生错误)
- Master端在发送快照文件过程中,接收的任何会改变数据集的命令都会暂时先保存在Slave网络连接的发送缓存队列里(list数据结构),待快照完成后,依次发给Slave,之后收到的命令相同处理,并将状态置位为 REDIS_REPL_ONLINE。
- 在2.8之后replication 支持增量复制,Master会在其内存中创建一个复制流的等待队列(list数据结构),Master和它所有的slave都维护了复制的replication offset 和 a master run id,因此,当网络连 接断开后,Slave会请求Master继续进行未完成的复制,从所记录的replication offset 开始。如果run id变化了,或者replication offset 不可用,那么将会进行一次全部 数据的复制.(当Master变更,Slave端会进行一次全量同步,主备从方案)
- 每增加一台从库,Master端都会重新执行一遍主从复制,建议从库最好一次性增加好,或者不要在服务器繁忙的时候增加从库
- 不建议redis的内存设置超过32G,redis replication 时 bgsave 会消耗大量的内存,传输快照文件时会消耗大量带宽, load快照会锁死从库.
- bgsave 很消耗内存 请预留redis已使用量 一半的内存用于 bgsave子进程消耗。