select distinct Salary as SecondHighestSalary from Employee order by Salary desc limit 1 offset 1;
select d.Name as Department,e.Name as Employee,e.Salary from Employee e inner join Department d on e.DepartmentId = d.Id and e.Salary >=( select max(Salary) from Employee where DepartmentId = d.Id );
select class from courses group by class having count(distinct student)>=5;
select Score,( select count(distinct Score) from Scores where Score >= s.score) as Rank from Scores s order by Score desc;
如何统计某张表里每个小时(存的年月日时分秒格式)的数据量
SELECT DATE_FORMAT(insertDate,'%Y-%m-%d %H:00:00') as time ,count(*) as count from auto_case GROUP BY time order by time;
SELECT HOUR(e.time) as Hour,count(*) as Count FROM error_log e WHERE e.date = '2017-09-02' GROUP BY HOUR(e.time) ORDER BY Hour(e.time);
输出某个字段下值出现次数超过三次的值
SELECT business_unit_code from t_replenish_config GROUP BY business_unit_code HAVING count( *)>3;
时间日期格式转换成时间戳格式,UNIX_TIMESTAMP()
SELECT UNIX_TIMESTAMP(NOW()); // 1539238930
时间戳格式转换成时间日期格式,FROM_UNIXTIME()
SELECT FROM_UNIXTIME(1539238971); // 2018/10/11 14:22:51
查询表中最后一条数据
select * from table order by id DESC limit 1;
查询一天所有数据
select * from table where date(column_time) = curdate();
查询一周数据
select * from table where DATE_SUB(CURDATE(),INTERVAL 7 DAY)<=date(column_time);
表中插入数据
insert into table (column1,column2...) values (value1,value2...);
删除
#删除表
drop table tablename;
#删除数据
delete from table1 where 范围
alter update insert区别:
update 是修改记录
alter 是修改表结构,添加字段
insert是插入数据
新增列
alter table tablename add column columnName varchar(20) not null;
为 jmccms_dic_type 表添加字段 dt_test_default,并设置默认值为 20
ALTER TABLE jmccms_dic_type ADD dt_test_default int DEFAULT 20 COMMENT '测试添加默认值'; desc jmccms_dic_type;
为 jmccms_dic_type 已有表中的 dt_test_Alert 字段设置默认值
ALTER TABLE jmccms_dic_type ALTER COLUMN dt_test_Alert SET DEFAULT '陈小佳'; desc jmccms_dic_type;
删除 jmccms_dic_type 表中 dt_test_Alert 的默认值刘德华
ALTER TABLE jmccms_dic_type ALTER COLUMN dt_test_Alert DROP DEFAULT; desc jmccms_dic_type;
删除 jmccms_dic_type 表中 dt_test_Alert 字段
ALTER TABLE jmccms_dic_type DROP COLUMN dt_test_Alert;
查询区分大小写
SELECT * FROM username WHERE LIKE BINARY '%小%'
新建表
create table if not exists testTable( id INT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT, phone VARCHAR(13) NOT NULL COMMENT '手机号', code INT NOT NULL COMMENT '验证码', uid INT COMMENT 'uid', insertDate datetime COMMENT '创建时间' )ENGINE=INNODB DEFAULT CHARSET=utf8
InnoDB是MySQL默认的存储引擎,默认的隔离级别是RR(Repeatable read可重复读),实现了串行化级别的效果,保留了较好的并发性能。
1.INNER JOIN (内连接)
内连接是一种一一映射关系,就是两张表都有的才能显示出来 用韦恩图表示是两个集合的交集,如图: 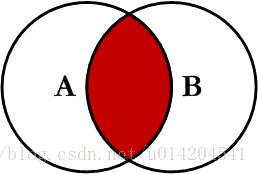
SELECT A.PK AS A_PK,A.Value AS A_Value,B.PK AS B_PK,B.Value AS B_Value FROM table_a A INNER JOIN table_b B ON A.PK = B.PK;
2.LEFT JOIN (左连接)
左连接是左边表的所有数据都有显示出来,右边的表数据只显示共同有的那部分,没有对应的部分只能补空显示,所谓的左边表其实就是指放在left join的左边的表
用韦恩图表示如下:
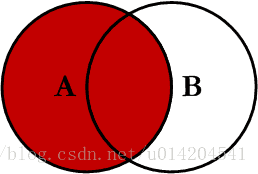
SELECT A.PK AS A_PK,A.Value AS A_Value,B.PK AS B_PK,B.Value AS B_Value FROM table_a A LEFT JOIN table_b B ON A.PK = B.PK;
3.RIGHT JOIN(右连接)
右连接正好是和左连接相反的,这里的右边也是相对right join来说的,在这个右边的表就是右表
用韦恩图表示如下:
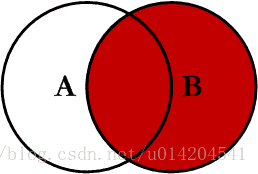
SELECT A.PK AS A_PK,A.Value AS A_Value,B.PK AS B_PK,B.Value AS B_Value FROM table_a A RIGHT JOIN table_b B ON A.PK = B.PK;
4.OUTER JOIN(外连接、全连接)
查询出左表和右表所有数据,但是去除两表的重复数据
韦恩图表示如下: 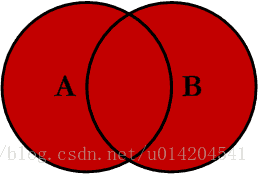
SELECT A.PK AS A_PK,A.Value AS A_Value,B.PK AS B_PK,B.Value AS B_Value FROM table_a A LEFT JOIN table_b B ON A.PK = B.PK UNION SELECT A.PK AS A_PK,A.Value AS A_Value,B.PK AS B_PK,B.Value AS B_Value FROM table_a A RIGHT JOIN table_b B ON A.PK = B.PK;
https://blog.csdn.net/u014204541/article/details/79739980
- mysql都有什么锁
MySQL有三种锁的级别:页级、表级、行级。
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
算法:
next KeyLocks锁,同时锁住记录(数据),并且锁住记录前面的Gap
Gap锁,不锁记录,仅仅记录前面的Gap
Recordlock锁(锁数据,不锁Gap)
所以其实 Next-KeyLocks=Gap锁+ Recordlock锁
- 什么情况下会造成死锁
所谓死锁<DeadLock>: 是指两个或两个以上的进程在执行过程中,
因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.
此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等竺的进程称为死锁进程.
由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象死锁。
一种情形,此时执行程序中两个或多个线程发生永久堵塞(等待),每个线程都在等待被其他线程占用并堵塞了的资源。
例如,如果线程A锁住了记录1并等待记录2,而线程B锁住了记录2并等待记录1,这样两个线程就发生了死锁现象。
表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB.
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序
- 在一个支持MVCC并发控制的系统中,哪些读操作是快照读?哪些操作又是当前读呢?以MySQL InnoDB为例:
-
快照读:简单的select操作,属于快照读,不加锁。(当然,也有例外,下面会分析)
-
select * from table where ?;
-
-
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
-
select * from table where ? lock in share mode;
-
select * from table where ? for update;
-
insert into table values (…);
-
update table set ? where ?;
-
delete from table where ?;
所有以上的语句,都属于当前读,读取记录的最新版本。并且,读取之后,还需要保证其他并发事务不能修改当前记录,对读取记录加锁。其中,除了第一条语句,对读取记录加S锁 (共享锁)外,其他的操作,都加的是X锁 (排它锁)。
-
https://www.cnblogs.com/zejin2008/p/5262751.html
数据库中的事务了解吗?事务的四大特性?
数据库事务是数据库运行中的逻辑工作单位,单个逻辑工作单元所执行的一系列操作,要么都执行,要么都不执行。例如银行取款事务分为2个步骤(1)存折减款(2)提取现金,2个步骤必须同时完成或者都不完成。
数据库事务的四大特性(ACID):
(1) 原子性(Atomicity):
事务的原子性指的是,事务中包含的程序作为数据库的逻辑工作单位,它所做的对数据修改操作要么全部执行,要么完全不执行。这种特性称为原子性。
(2)一致性(Consistency) :
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。这种特性称为事务的一致性。假如数据库的状态满足所有的完整性约束,就说该数据库是一致的。
(3)分离性(Isolation):
分离性指并发的事务是相互隔离的。即一个事务内部的操作及正在操作的数据必须封锁起来,不被其它企图进行修改的事务看到。假如并发交叉执行的事务没有任何控制,操纵相同的共享对象的多个并发事务的执行可能引起异常情况。
(4)持久性(Durability):
持久性意味着当系统或介质发生故障时,确保已提交事务的更新不能丢失。即一旦一个事务提交,DBMS保证它对数据库中数据的改变应该是永久性的,即对已提交事务的更新能恢复。持久性通过数据库备份和恢复来保证。
如何理解数据库的范式?
https://blog.csdn.net/zymx14/article/details/69789326
第一范式(1NF):确保每一列的原子性
如果每一列都是不可再分的最小数据单元,则满足第一范式。
第二范式:非键字段必须依赖于键字段
如果一个关系满足1NF,并且除了主键以外的其它列,都依赖与该主键,则满足二范式(2NF),第二范式要求每个表只描述一件事。
第三范式:在1NF基础上,除了主键以外的其它列都不传递依赖于主键列,或者说: 任何非主属性不依赖于其它非主属性
(在2NF基础上消除传递依赖)
数据库的乐观锁和悲观锁
乐观锁:乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。
实现:乐观锁不是数据库自带的,需要我们自己去实现。比如更新记录时检查当前记录version字段值是否与数据库中记录当前version一致。
悲观锁:悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作。
实现:悲观锁是由数据库自己实现了的,使用Repeatable Read的隔离级别,然后执行相应的SQL语句即可。
MySQL的共享锁和排他锁?
共享锁:共享锁又称读锁,是读取操作创建的锁。如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
使用:SELECT ... LOCK IN SHARE MODE;
排他锁:排他锁又称写锁,如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
使用:SELECT ... FOR UPDATE;