1.什么是false sharing
在对称多处理器(SMP)系统中,每个处理器均有属于自己的本地高速缓存区。
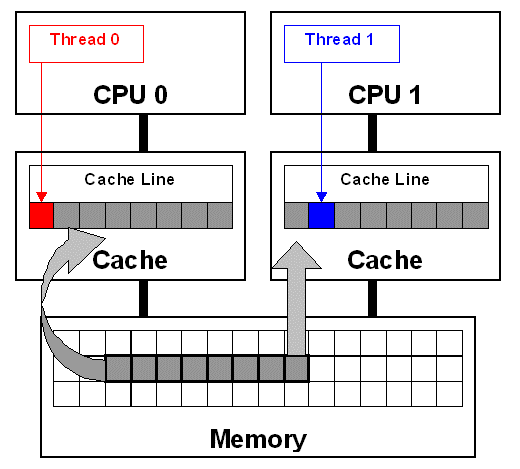
如图,CPU0和CPU1有各自的本地高速缓存区(cache)。线程0和线程1会用到不同的变量,它们在内存中彼此相邻。内存以64字节分割高速缓存行,我们假设红色变量与蓝色变量恰好分配在同一条高速缓存行中。CPU如果想要读取变量,会以高速缓存行的形式加载到本地高速缓存区中。这个例子中,CPU0和CPU1加载了同一条高速缓存行。然后线程0修改了红色变量,线程1修改了蓝色变量,这导致了CPU1中红色变量不正常,CPU0中蓝色变量不正常,从而导致高速缓存行无效,并强制内存更新以维持高速缓存的一致性。
2.(intel)如何确保多个CPU中的高速缓存的数据一致性
Intel处理器遵循MESI协议(Modified/Exclusive/Shared/Invalid,修改/独占/共享/无效)。
独占:
首次加载高速缓存行时,处理器将高速缓存行标记为”独占”访问,一旦该高速缓存行被标记为独占,后续加载可以自由使用缓存中的现有数据。
共享:
如果该处理器看到相同的高速缓存行被其它处理器加载到总线上,就会将该高速缓存行标记为”共享”访问。
修改:
如果处理器修改并保存了”共享”的高速缓存行,该缓存行将被标记为”修改”,所有其它处理器会受到一条”无效”的信息。当处理器A看到其它处理器访问标记为”修改”的相同高速缓存,A会将该高速缓存行存回内存,并将其标记为”共享”,其它处理器丢失自己的对应的高速缓存行。
无效:
处理器之间频繁协调,将”修改”的高速缓存行写入内存,然后再加载
3.解决假共享的方法
所有方法的目的都是确保引起false sharing的变量在内存中存放的位置相隔足够远,从而不会驻留在同一个高速缓存行中。
方法1: 使用编译指令强制对齐单个变量。
使用__declspec (align(64))声明变量
例: 单个变量
__declspec (align(64)) int thread1_global_variable;
__declspec (align(64)) int thread2_global_variable;
例: struct
使用int padding[n]确保struct为64或64的倍数
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; // Frequent read/write access variable
unsigned long start;
unsigned long end;
// expand to 64 bytes to avoid false-sharing
// (4 unsigned long variables + 12 padding)*4 = 64
int padding[12];
};
__declspec (align(64)) struct ThreadParams Array[10];
方法2:使用数据的线程本地拷贝来减少false sharing的频率
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; //Frequent read/write access variable
unsigned long start;
unsigned long end;
};
threadFunc(void *parameter)
{
ThreadParams *p = (ThreadParams*) parameter;
// local copy for read/write access variable
unsigned long local_v = p->v;
for(local_v = p->start; local_v < p->end; local_v++)
{
// Functional computation
}
p->v = local_v; // Update shared data structure only once
}
假设v在这个循环中每一次循环都被修改,那么,每一次修改都将触发false sharing。因此,我们使用线程本地变量local_v,所有的中间修改都在本地完成,仅在p->v = local_v;时更新数据结构
原文见:https://software.intel.com/zh-cn/articles/avoiding-and-identifying-false-sharing-among-threads