缓存的使用可以极大提升应用程序的性能,特别是数据查询方面。但是它也会带来一定的问题,最要害的问题就是数据的一致性问题,从严格意义上来说这个问题无解。如果对数据的一致性要求很高,那么就不能使用缓存。
另外一些典型的问题就是:
- 缓存穿透
- 缓存雪崩
- 缓存击穿
- 缓存预热
对于这几个问题业界也有比较流行的解决方案。我现在对这些问题还没有一个明确的概念,所以我得先熟悉一下。
缓存穿透
缓存穿透,是指查询一个数据库一定不存在的数据。正常的使用缓存流程大致是,数据查询先进行缓存查询,如果 key 不存在或者 key 已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
想象一下这个情况,如果传入的参数为 -1,会是怎样?这个 -1,就是一定不存在的对象。就会每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就会利用这个漏洞,对数据库造成压力,甚至压垮数据库。即便是采用 UUID,也是很容易找到一个不存在的 key,进行攻击。
解决方法是,采用缓存空值的方式,也就是如果从数据库中查询的对象为空,也放入缓存,只是设定的缓存过期时间较短,比如设置为 60 秒。
另一个种方法是使用 bloom filter,用所有可能的查询条件生成一个 bitmap,在进行数据库查询之前会使用这个 bitmap 进行过滤,如果不在其中则直接过滤,从而减轻数据库层面的压力。guava 中有实现 BloomFilter 算法。
缓存雪崩
缓存雪崩,是指在某一个时间段,缓存集中过期失效。
产生雪崩的原因之一,比如在写文本的时候,马上就要到双十二零点,很快就会迎来一波抢购,这波商品时间比较集中地放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。
在做电商项目的时候,一般是采取不同分类商品,缓存不同周期。在同一分类中的商品,加上一个随机因子。这样能尽可能分散缓存过期时间,而且,热门类目的商品缓存时间短一些,也能节省缓存服务的资源。
其实集中过期,倒不是非常致命,比较致命的是缓存雪崩,是缓存服务器某个节点宕机或者断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点宕机,对数据库造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
缓存击穿
缓存击穿,是指一个 key 非常热,在不停地扛着大并发,大并发集中对这一点进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在屏障上凿开了一个洞。
大多数情况下这种爆款很难对数据库服务器造成压垮性的压力。达到这个级别的公司没有几家。所以,对主打商品都是早早做好准备,让缓存永不过期。即使某些商品发酵成了爆款,也是直接设为永不过期就好了。但是热点可能随着时间的变化而变化,针对固定的数据进行特殊缓存是不能起到治本作用的,结合 LRU 算法能够较好的帮助解决这个问题。
LRU(lease recently used,最近最少使用)算法根据数据访问的历史记录在进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的记录也更高”。最常见的是用一个链表保存缓存数据,如下图:
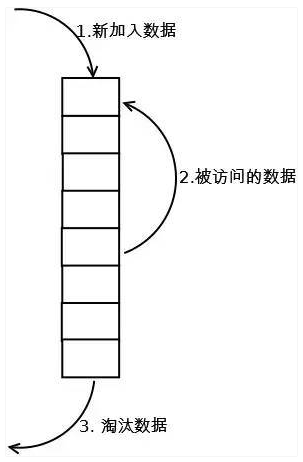
首先将新数据放入链表的头部,在进行数据插入的过程中,如果检测到链表中有数据被再次访问也就是有请求再次访问这些数据,那么就将其插入到链表的头部,因为它们相对其他数据来说可能是热点数据,具有保留时间更久的意义。
最后当链表数据放满时将底部的数据淘汰,也就是不常访问的数据。
LRU-K 算法,其实上面的算法也就是该算法的特例情况即 LRU-1,上面的算法存在较多的不合理性,在实际的应用过程中采用了该算法进行改进,例如偶然的数据影响会造成命中率降低,比如某个数据即将到达底部即将被淘汰,但由于一次的请求又放入了头部,此后再无该数据的请求,那么该数据的继续存在其实是不合理的,针对这种情况 LRU-K 算法拥有更好的解决措施,如下图:
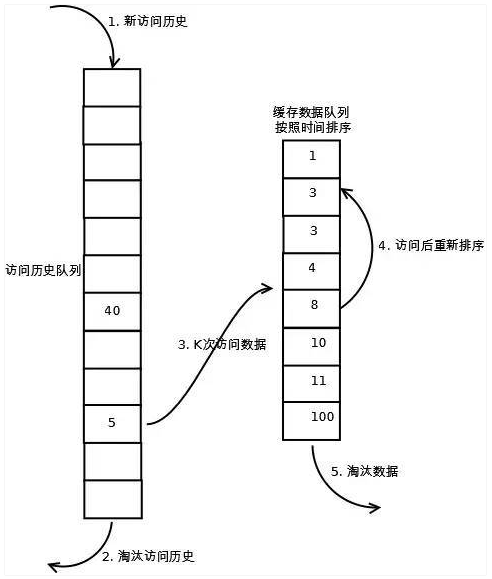
LRU-K 需要多维护一个队列或者更多,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到 K 次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K 会淘汰第 K 次访问时间距当前时间最大的数据。
第一步添加数据照样放入第一个队列的头部。如果数据在队列里访问没有达到 K 次(该数值根据具体系统的 QPS 来定)则会继续到达链表底部直至淘汰;如果该数据在队列中访问次数达到了 K 次,那么它会被加入到接下来的 2 级(具体几级结构也同样结合系统分析)链表中,按照时间顺序在 2 级链表中排列。
接下来 2 级链表中的操作与上面算法相同,链表中的数据如果再次被访问则移到头部,链表满时,底部数据淘汰。
相比 LRU,LRU-K 需要多维护一个队列,用于记录所有缓存数据被访问的历史,所以需要更多的内存空间来构建缓存,但优点也很明显,较好地降低了数据的污染率,提高了缓存的命中率,对于系统来说可以用一定的硬件成本换区系统性能也不失为一种好方法。
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询实现被预热的缓存数据。
解决思路:
- 直接写个缓存刷新页面,上线时手工操作下;
- 数据量不大,可以在项目启动的时候自动进行加载;
- 定时刷新缓存。
Reference:
https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc