redis简介
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步
redis安装
https://www.cnblogs.com/liuqingzheng/p/9831331.html
支持的五大数据类型
redis={ k1:'123', 字符串 k2:[1,2,3,4], 列表/数组 k3:{1,2,3,4} 集合,可以用来去重 k4:{name:lqz,age:12} 字典/哈希表 k5:{('lqz',18),('egon',33)} 有序集合,可以用来排序 }
特点,可以持久化(可以将数据存到可永久化保存的地方,比如硬盘);单线程单进程,并发高,理论达10w
五大数据类型的值只能存字符串,就算有些int存进去了,里面也会转成字符串
python操作redis普通连接
import redis r = redis.Redis(host='127.0.0.1',port=6379) r.set('foo','af') print(r.get('foo'))
python操作redis线程池连接
import redis pool = redis.ConnectionPool(host='127.0.0.1',port=6379) r = redis.Redis(connection_pool=pool) r.set('k1','afasf') print(r.get('k1'))
字符串操作
String操作,redis中的String在在内存中按照一个name对应一个value来存储
set()
set函数源码
def set(self, name, value, ex=None, px=None, nx=False, xx=False): """ Set the value at key ``name`` to ``value`` ``ex`` sets an expire flag on key ``name`` for ``ex`` seconds. ``px`` sets an expire flag on key ``name`` for ``px`` milliseconds. ``nx`` if set to True, set the value at key ``name`` to ``value`` only if it does not exist. ``xx`` if set to True, set the value at key ``name`` to ``value`` only if it already exists. """ pieces = [name, value] if ex is not None: pieces.append('EX') if isinstance(ex, datetime.timedelta): ex = int(ex.total_seconds()) pieces.append(ex) if px is not None: pieces.append('PX') if isinstance(px, datetime.timedelta): px = int(px.total_seconds() * 1000) pieces.append(px) if nx: pieces.append('NX') if xx: pieces.append('XX') return self.execute_command('SET', *pieces)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值(取值返回None)
r.set('k2','xxx',nx=True),就是说只新增,不能修改
r.set('k2','xxx',xx=True),就是说只修改,不能新增
get(name) 取值
setnx(name, value),相当于set自带nx=True
setex(name, time, value) time,过期时间(数字秒 或 timedelta对象)
psetex(name, time_ms, value) time_ms,过期时间(数字毫秒 或 timedelta对象
mset(*args, **kwargs) 批量设置值
例:mget({'k1': 'v1', 'k2': 'v2'})
def mset(self, mapping): """ Sets key/values based on a mapping. Mapping is a dictionary of key/value pairs. Both keys and values should be strings or types that can be cast to a string via str().
根据映射设置键/值。 映射是键/值对的字典。
键和值都应该是可以通过str()强制转换为字符串的字符串或类型。 """ items = [] for pair in iteritems(mapping): items.extend(pair) return self.execute_command('MSET', *items)
mget(keys, *args) 批量取值
如:
mget('k1', 'k2')
或
r.mget(['k3', 'k4'])
getset(name, value) 设置新值并获取原来的值
getrange(key, start, end) 获取子序列(根据字节获取,非字符)
参数:
name,Redis 的 name
start,起始位置(字节)
end,结束位置(字节)
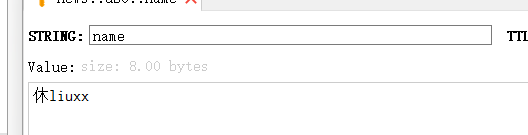
pool = redis.ConnectionPool(host='127.0.0.1',port=6379) r = redis.Redis(connection_pool=pool) print(r.getrange('name', 0, 2)) #b'xe4xbcx91'
setrange(name, offset, value) 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
setbit(name, offset, value) 对name对应值的二进制表示的位进行操作
参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
getbit(name, offset) 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key, start=None, end=None)获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
bitop(operation, dest, *keys) 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
strlen(name) 返回name对应值的字节长度(一个汉字3个字节)
incr(self, name, amount=1) name对应的值做加法运算,name对应的值和amount的参数都必须是int,当name不存在时,则创建name=amount,否则,则自增。
incrbyfloat(self, name, amount=1.0) name对应的值做加法运算,name对应的值和amount的参数都必须是float,当name不存在时,则创建name=amount,否则,则自增。
decr(self, name, amount=1) 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
参数:
# name,Redis的name
# amount,自减数(整数)
append(key, value) 就是给name对应的的值做字符串的拼接
字典(Hash)操作
hset(name, key, value) name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping) 在name对应的hash中批量设置键值对
参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'}
hget(name,key)
在name对应的hash中获取根据key获取value
hmget(name, keys, *args)在name对应的hash中获取多个key的值
参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
# 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print r.hmget('xx', 'k1', 'k2')
hgetall(name) 获取name对应hash的所有键值,一次性全取出来,如果数据量很大,不建议用
取出来是一个字典,里面放的有所有的键值对
例 print(r.hgetall('xx1'))
》》{b'xx2': b'xx3', b'xx4': b'xx3', b'ss': b'ss', b'vv': b'vv'}
hlen(name) 获取name对应的hash中键值对的个数
hkeys(name) 获取name对应的hash中所有的key的值
hvals(name) 获取name对应的hash中所有的value的值
hexists(name, key) 检查name对应的hash是否存在当前传入的key
hdel(name,*keys) 将name对应的hash中指定key的键值对删除
print(re.hdel('xxx','sex','name'))
hincrby(name, key, amount=1) 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name, key, amount=1.0) 自增name对应的hash中的指定key的值,不存在则创建key=amount
参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name, cursor=0, match=None, count=None)
增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
例:
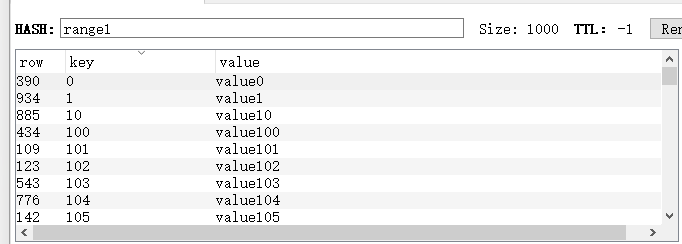
# for i in range(1000):
# r.hset('range1',i,'value%s'%i)
print(r.hscan('range1', 0, count=100))
def hscan(self, name, cursor=0, match=None, count=None): """ Incrementally return key/value slices in a hash. Also return a cursor indicating the scan position. ``match`` allows for filtering the keys by pattern ``count`` allows for hint the minimum number of returns """ pieces = [name, cursor] if match is not None: pieces.extend([Token.get_token('MATCH'), match]) if count is not None: pieces.extend([Token.get_token('COUNT'), count]) return self.execute_command('HSCAN', *pieces)
hscan_iter(name, match=None, count=None) 利用yield封装hscan创建生成器,实现分批去redis中获取数据
参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
如:
# for item in r.hscan_iter('xx'):
# print (item)
def hscan_iter(self, name, match=None, count=None): """ Make an iterator using the HSCAN command so that the client doesn't need to remember the cursor position. ``match`` allows for filtering the keys by pattern ``count`` allows for hint the minimum number of returns """ cursor = '0' while cursor != 0: cursor, data = self.hscan(name, cursor=cursor, match=match, count=count) for item in data.items(): yield item
列表操作
List操作,redis中的List在在内存中按照一个name对应一个List来存储
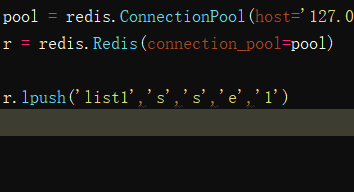

lpush(name,*values)在name对应的list中添加元素,每个新的元素都添加到列表的最左边
如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
# 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
# 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)name对应的list元素的个数
linsert(name, where, refvalue, value))在name对应的列表的某一个值前或后插入一个新值
参数:
# name,redis的name
# where,BEFORE或AFTER(小写也可以)
# refvalue,标杆值,即:在它前后插入数据(如果存在多个标杆值,以找到的第一个为准)
# value,要插入的数据
r.lset(name, index, value) 对name对应的list中的某一个索引位置重新赋值
参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name, value, num) 在name对应的list中删除指定的值
参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name) 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
更多:
# rpop(name) 表示从右向左操作
lindex(name, index)在name对应的列表中根据索引获取列表元素
lrange(name, start, end)在name对应的列表分片获取数据
参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置 print(re.lrange('aa',0,re.llen('aa')))
ltrim(name, start, end)在name对应的列表中移除没有在start-end索引之间的值
参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置(大于列表长度,则代表不移除任何)
rpoplpush(src, dst)从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys, timeout)将多个列表排列,按照从左到右去pop对应列表的元素
参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
# r.brpop(keys, timeout),从右向左获取数据
爬虫实现简单分布式:多个url放到列表里,往里不停放URL,程序循环取值,但是只能一台机器运行取值,可以把url放到redis中,多台机器从redis中取值,爬取数据,实现简单分布式
brpoplpush(src, dst, timeout=0)从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
import redis conn=redis.Redis(host='127.0.0.1',port=6379) # conn.lpush('test',*[1,2,3,4,45,5,6,7,7,8,43,5,6,768,89,9,65,4,23,54,6757,8,68]) # conn.flushall() def scan_list(name,count=2): index=0 while True: data_list=conn.lrange(name,index,count+index-1) if not data_list: return index+=count for item in data_list: yield item print(conn.lrange('test',0,100)) for item in scan_list('test',5): print('---') print(item)
其它操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern='*')

# 根据模型获取redis的name
# 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time)
# 为某个redis的某个name设置超时时间
rename(src, dst)
# 对redis的name重命名为
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
# 同字符串操作,用于增量迭代获取key
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.Redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
pipe.multi()
pipe.set('name', 'alex')
pipe.set('role', 'sb')#要么同时执行成功,要么同时失败
pipe.execute()
django中使用redis
方式一:
在utils文件夹下新建一个py文件(就像之前建序列化类,频率类一样),在里面建一个连接池
import redis POOL = redis.ConnectionPool(host='127.0.0.1', port=6379,password='1234',max_connections=1000)
#没密码password不用写
视图类中使用
import redis from django.shortcuts import render,HttpResponse from utils.redis_pool import POOL def index(request): conn = redis.Redis(connection_pool=POOL) conn.hset('kkk','age',18) return HttpResponse('设置成功') def order(request): conn = redis.Redis(connection_pool=POOL) conn.hget('kkk','age') return HttpResponse('获取成功')
方式二
使用django-redis模块
setting里配置:
# redis配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100}
# "PASSWORD": "123",
}
}
}
视图函数:
from django_redis import get_redis_connection
conn = get_redis_connection('default')
print(conn.hgetall('xxx'))