什么是SEO?
官方解释:
SEO是指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排名需求,在搜索引擎中提高关键词排名,
从而把精准用户带到网站,获得免费流量,产生直接销售或品牌推广
SEO 搜索引擎优化在用户输入关键字时,能够让自己的排名更靠前。有白帽SEO和黑帽SEO,黑帽是代欺诈性的。
大白话:SEO是对搜索引擎进行优化,方便网络爬虫抓取
网络爬虫:又被称为网页蜘蛛,网络机器人,在FOAF社区中间,常被称为网页追逐者,是一种按照一定规则自动抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫
白帽SEO:合理优化网站,提高用户体验,合理与其它网站互联,从而使站点在搜索引擎排名提升
黑帽SEO:采用搜索引擎禁止的方式优化网站(比如,关键字堆砌、隐藏文本、链接欺骗、镜像网站、伪装)一般俗称SEO作弊
白帽SEO和黑帽SEO的特点以及区别:https://www.simcf.cc/2339.html/
需要掌握的几个利于SEO的方法
①:网站 title,description,keywords的设置
根据产品业务,概括出核心标题,描述,关键字的内容,每个页面尽量都不一样。若每个页面都完全相同 ,搜索引擎会持怀疑态度,觉得你有作弊嫌疑。
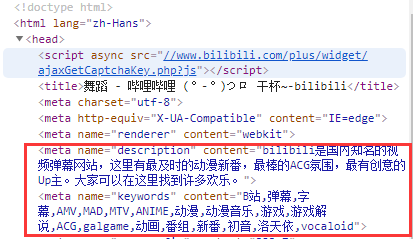
注:此外,还有 meta 的 canonical 设置,一个网站还可通过多个 url 访问,canonical 就是用来告诉搜索引擎,
这么多个 url 中最有价值最重要的一个 url,一般是网站的首页。

②:图片img标签必须加上alt属性,并注明图片的含义

③:h1~h6标签合理使用
h1 标签一个页面只能出现 1 次,h2 标签一般作为二级标题或者文章的小标题。最合理的使用是 h1~h6 按顺序层层嵌套下去,不可以断层或反序
此外,h1 标签可以用在 logo 上,但要确保一个网页只有一个 h1 标签。
④:给a标签也加上title属性,并且要设置nofollow属性
nofollow属性是告诉爬虫,该页面上的所有连接都不需要追踪
之前我写过一篇博客介绍该属性的作用和怎样使用,详情见:https://www.cnblogs.com/tu-0718/p/9215002.html
⑤:增加网站的404页面
利于用户体验,最主要是防止蜘蛛爬虫的丢失。但有一点要注意,不要设置自动跳转到首页,
会被搜索引擎认为是在作弊,你在 404 页面设置一个引导链接让用户自己点就可以。
⑥:建立 robots.txt 文件
robots 文件是搜索引擎登录网站第一个访问的文件,robots 可以设置允许被访问的搜索引擎,
最主要还是设置允许 Allow 和不允许 Disallow 访问的目录和文件,
少写 Disallow,多写 Allow,用意是引导爬虫抓取网站的信息。另外, 在 robots 文件底部指明网站 sitemap 文件的目录,
爬虫读取其中的 sitemap 路径,接着抓取其中相链接的网页。提高网站的收录量。
⑦:网站结构优化
这是一个专门针对SEO的教程网站,感觉还错 http://www.searcheo.cn/post/seo.html