数组
ndarray是一系列同类型数据的集合,索引以 0 下标开始,每个元素在内存中占有相同存储大小的区域。
数组对象的常用属性
ndim, shape, size, dtype, itemsize, nbytes, data, flags, real, imag
ndarray.ndim # 数组坐标轴的数量,一维数组的坐标轴为0,二维的坐标轴为0和1;秩,即轴的数量或维度的数量
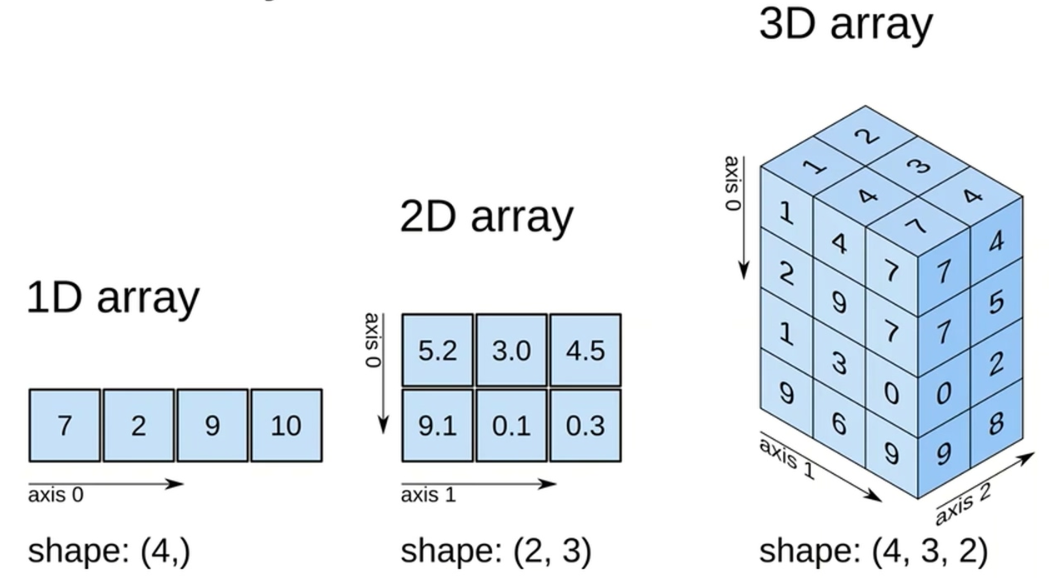
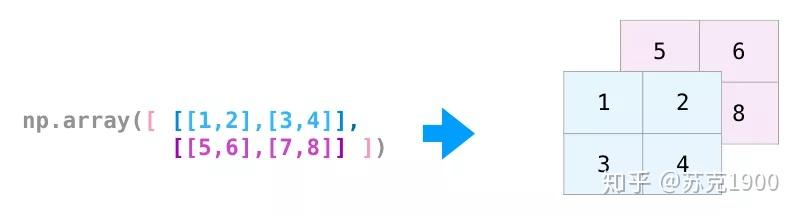
轴的数字就是数组中括号的顺序,第一个中括号为0轴....。np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]]),有3个中括号,所以有0轴[,1轴[[,2轴[[[。每一个中括号相当于一个盒子,里面装着对应的元素。
ndarray.shape #数组的维度,n行m列的矩阵维度为(n,m),shape的长度就是ndim,ndarray.shape[0]获得行数,ndarray.shape[1]获得列数;
ndarray.size # 数组的元素个数,n行m列矩阵的元素个数 n * m,.shape 中 n*m 的值
ndarray.dtype #数组元素的数据类型,NumPy提供的数据类型:numpy.int32, numpy.int16, and numpy.float64
ndarray.dtype.name #数组元素的数据类型名称
ndarray.itemsize #数组中每个元素字节大小,float64的itemsize为8 (=64/8), complex32的itemsize为4 (=32/8),等效:ndarray.dtype.itemsize
ndarray.nbytes # 数组中元素个数 * itemsize
ndarray.data # <memory at 0x ..> 数组的真实内存地址
ndarray.real # ndarray元素的实部
ndarray.imag # ndarray元素的虚部
ndarray.flags # ndarray 对象的内存信息
C_CONTIGUOUS (C) #数据是在一个单一的C风格的连续段中
F_CONTIGUOUS (F) #数据是在一个单一的Fortran风格的连续段中
OWNDATA (O) #数组拥有它所使用的内存或从另一个对象中借用它
WRITEABLE (W) #数据区域可以被写入,将该值设置为 False,则数据为只读
ALIGNED (A) #数据和所有元素都适当地对齐到硬件上
UPDATEIFCOPY (U) #这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新


import numpy as np a = np.array([[1,2,3],[4,5,6]]) print(a) ''' [[1 2 3] [4 5 6]] ''' print(a.ndim) # 2 print (a.shape) # (2, 3) print(len(a.shape)) # 2 print(a.shape[0]) # 2 print(a.shape[1]) # 3 print(a.size) # 6 print(a.dtype) # int32 print(a.itemsize) # 4 print(a.nbytes) # 24 print(a.data) # <memory at 0x00000000088FFF28> print(a.real) ''' [[1 2 3] [4 5 6]] ''' print(a.imag) ''' [[0 0 0] [0 0 0]] ''' print(a.flags) ''' C_CONTIGUOUS : True F_CONTIGUOUS : False OWNDATA : True WRITEABLE : True ALIGNED : True WRITEBACKIFCOPY : False UPDATEIFCOPY : False '''
数组对象内置的统计方法
max, min, mean, sum, cumsum, std, var, argmax, argmin
ndarray.max() # 数组中的最大值;ndarray.max(axis=0)列中的最大值,ndarray.max(axis=1)行中的最大值
ndarray.min() # 数组中的最小值
ndarray.mean() # 数组元素的算术平均
ndarray.sum() # 数组元素之和
ndarray.cumsum() # 数组元素的累加和
ndarray.std() # 数组元素的标准差
ndarray.var() # 数组元素的方差
ndarray.argmax() # 数组中最大值的下标,np.argmax([1,2,6,3,2])返回的是2
ndarray.argmin() # 数组中最小值的下标,np.argmin([1,2,6,3,2])返回的是0
#max, min, mean, sum, cumsum, std, var, argmax, argmin import numpy as np a = np.array([[1, 2, 3], [4, 5, 6], [7, 8 ,9]]) print(a.max()) # 9 print(a.max(axis=0)) # [7 8 9] print(a.max(axis=1)) # [3 6 9] print(a.min()) # 1 print(a.mean()) # 5.0 print(a.sum()) # 45 print(a.cumsum()) # [ 1 3 6 10 15 21 28 36 45] print(a.cumsum(axis=0)) ''' [[ 1 2 3] [ 5 7 9] [12 15 18]] ''' print(a.cumsum(axis=1)) ''' [[ 1 3 6] [ 4 9 15] [ 7 15 24]] ''' print(a.std()) # 2.581988897471611 print(a.var()) # 6.666666666666667 print(a.argmax()) # 8 print(a.argmin()) # 0


创建数组
array, asarray, arange, eye, identity, full, full_like, zeros, zeros_like, ones, ones_like, empty, empty_like, linspace, numpy.random.RandomState.rand, numpy.random.RandomState.randn, fromfunction, fromfile
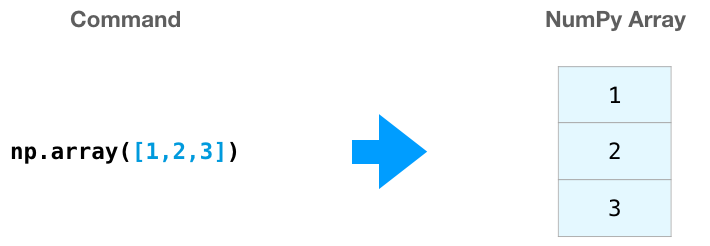
numpy.array() # 将输入数据(列表、元祖、数组或其他系列类型) 转换为ndarray; numpy推断dtype或自己指定。
numpy.asarray() # 将输入转换为ndarray,如果输入就是ndarray则不进行复制
numpy.arange() # 类似内置的range,但返回的是ndarray数组而不是列表
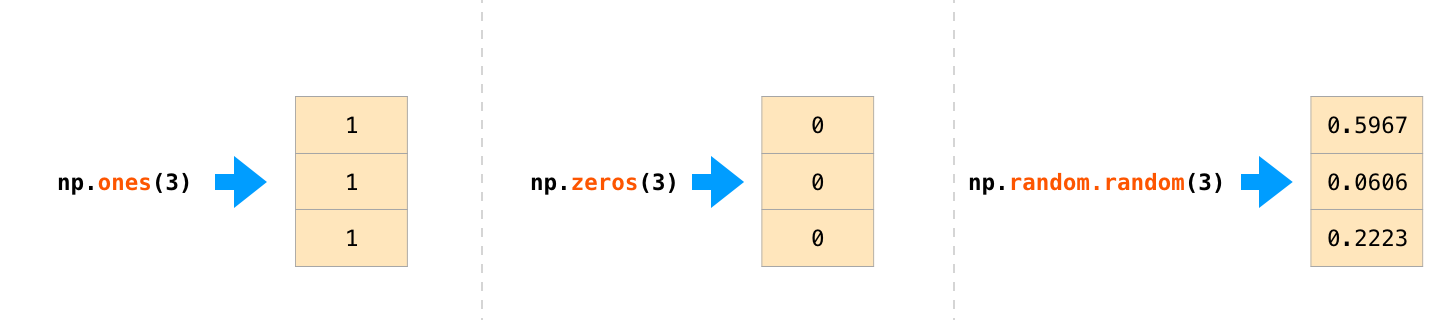
numpy.ones() # 根据指定的形态和dtype创建一个全1的数组。
numpy.ones_like() # 接受另一个数组的参数,并根据其形状和type创建全1数组
numpy.zero() # 创建0数组
numpy.zero_like()
numpy.empty() # 创建空数组,只分配空间,不作初始化
numpy.empty_like()
numpy.eye() # 创建单位矩阵, numpy.eye(3,3) 创建3行3列的单位矩阵
numpy.identity() # 创建单位矩阵,numpy.identity(3)创建3行3列的单位矩阵
numpy.full() # 创建以固定值填充的矩阵
创建数组
numpy.empty()
numpy.zeros()
numpy.ones()
numpy.full()
numpy.eye()
numpy.identity()
np.zeros( (3,4) ) #3行4列的零矩阵 ''' array([[ 0., 0., 0., 0.], [ 0., 0., 0., 0.], [ 0., 0., 0., 0.]]) ''' np.ones( (2,3,4), dtype = np.int16 ) ''' array([[[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]], [[ 1, 1, 1, 1], [ 1, 1, 1, 1], [ 1, 1, 1, 1]]], dtype=int16) ''' np.empty( (2,3) ) ''' array([[ 3.73603959e-262, 6.02658058e-154, 6.55490914e-260], [ 5.30498948e-313, 3.14673309e-307, 1.00000000e+000]]) ''' np.eye(3,3) # 创建3行3列的单位矩阵 np.identity(3) ''' array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.]]) ''' np.full((2,3),5) # 2行3列的矩阵,每个元素用5填充 ''' array([[5, 5, 5], [5, 5, 5]]) '''
从数值范围创建数组
numpy.arange(start, stop, step, dtype=None) # 生成包含起点但不包含终点的等间隔一维等差数组
numpy.linspace(start, stop, num=50, endpoint=True, restep=False, dtype=None) # 生产包含起点和终点的等差数列
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None) # 生成等比数列
start — 区间起始值为base的start次方,强制参数。
stop — 区间终止值为base的stop次方(是否取得到,需要设定参数endpoint),强制参数。
num — 等分的个数。按照对数,即start和stop值进行等分。默认值为50,可选参数。
endpoint — 若为True(默认),则可以取到区间终止值;否则取不到。可选参数。
base — 基底。
numpy.geomspace(start, stop, num=50, endpoint=True, dtype=None, axis=0) # 生成均匀分布的对数数列(几何级数数列)
import numpy as np e = np.random.random((2,2)) # 创建2 * 2的随机数矩阵 print(e) ''' 随机生成类似的矩阵 [[0.69674237 0.49045796] [0.94549268 0.34180246]] ''' print(np.arange(10)) # [0 1 2 3 4 5 6 7 8 9] print(np.arange(2, 10)) # [2 3 4 5 6 7 8 9] print(np.arange(2, 3 , 0.1)) # [2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9] print(np.linspace(1., 4., 6)) # 在1和4之间生成6个等差数列 [1. 1.6 2.2 2.8 3.4 4. ] print(np.logspace(0, 9, 10, base = 2 )) # 以2为底,幂次方从0到9生成10个元素 [ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.] print(np.geomspace(2, 16, 4,)) # 在2和16之间生成4个几何级数 [ 2. 4. 8. 16.] ''' 原理: d=(stop/start)**(1/(n-1)) start ,start*d,start*d*d,start*d*d*d,… np.geomspace(2,16,4) # array([ 2., 4., 8., 16.]) d=(16/2)**(1/3) # 2 a0,a1,a2,a3=2,2*d,2*d*d,2*d*d*d # (2, 4.0, 8.0, 16.0) '''
从已有的数据创建数组
numpy.asarray()
numpy.frombuffer()
numpy.fromiter()
numpy.empty_like()
numpy.zeros_like()
numpy.ones_like()
numpy.full_like()
创建指定数据类型数组,数组数据类型转换
import numpy as np print ('将列表数据转为数组') data = [[1, 2, 3], [4, 5, 6]] a = np.array(data) print(type(data)) # class 'list'> print(type(a)) # <class 'numpy.ndarray'> print(a) ''' [[1 2 3] [4 5 6]] ''' print ('生成指定数据类型数组') arr = np.array([1, 2, 3], dtype = np.float64) #生成数据类型为float64的ndarray数组 print(arr) # [1. 2. 3.] print ('使用astype复制数组并转换数据类型') int_arr = np.array([1, 2, 3, 4, 5]) float_arr = int_arr.astype(np.float) print(int_arr) # [1 2 3 4 5] print (int_arr.dtype) # int32 print(float_arr) # [1. 2. 3. 4. 5.] print (float_arr.dtype) #float64 print ('使用astype将float转换为int时小数部分被舍弃') float_arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1]) int_arr = float_arr.astype(dtype = np.int) print (int_arr) #[ 3 -1 -2 0 12 10] print ('使用astype把字符串转换为数组,如果失败抛出异常。') str_arr = np.array(['1.25', '-9.6', '.42'], dtype = np.string_) float_arr = str_arr.astype(np.float) print (float_arr) # [ 1.25 -9.6 0.42] print ('astype使用其它数组的数据类型作为参数') int_arr = np.arange(10) float_arr = np.array([.23, 0.270, .357, 0.44, 0.5], dtype = np.float64) print (int_arr.astype(dtype = float_arr.dtype)) # [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] print (int_arr[0], int_arr[1] ) # 0 1,astype做了复制,数组本身不变。
数组的维度变换
ndarray.shape, reshape, resize, ravel, flatten, T, transpose, concatenate, vstack, row_stack, hstack, column_stack, dstack, split, hsplit, vsplit, dsplit, repeat, tile
ndarray.reshape(shape, order='C') # 不改变当前数组,依shape生成。同 numpy.reshape(a, newshape, order='C') # order默认为‘C’:类C的索引顺序,按行读取;‘F’是类Fortan索引顺序,按列读取。
ndarry.resize(shape) # 改变当前数组,依shape生成 ,print(ndarray.resize())为None,resize直接改变了数组维度,所以应该输出数组,而不是操作
numpy.ravel(a, order='C') # 返回一个连续的扁平数组。
ndarray.flatten(order='C') # 对数组进行降维,返回折叠后的一位数组
numpy.transpose(a, axes=None) # 反转坐标轴,并返回反转后的数组;
ndarrary.T # 将数组转置
numpy.swapaxes(a, axis1, axis2) # 互换数组的两个轴
numpy.moveaxis(a, source, destination) # 将数组的轴移到新位置,source是坐标轴数字
numpy.rollaxis(a, axis, start=0) # 回滚给定轴到指定位置。
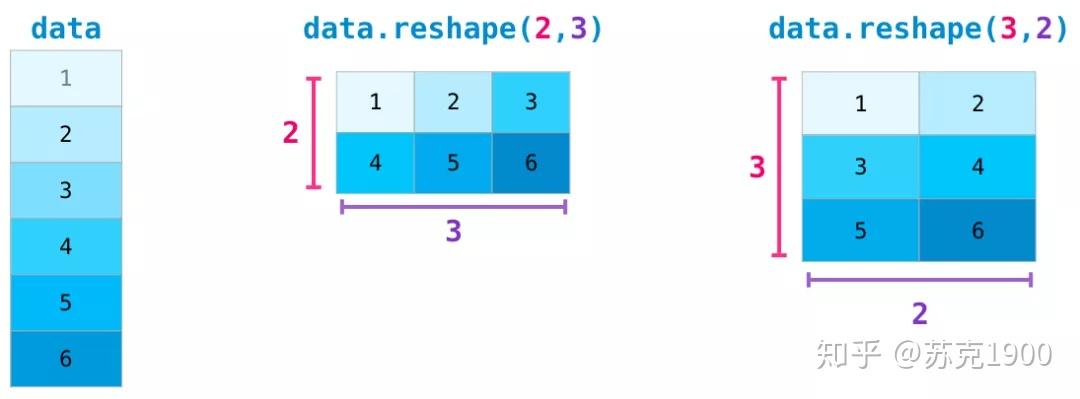
import numpy as np arr = np.arange(12) print(arr) # [ 0 1 2 3 4 5 6 7 8 9 10 11] print(arr.shape) # (12,) print(arr.reshape(3 , 4)) # 同 print(np.reshape(arr,(3 , 4))) ,order默认为类C的索引顺序,按行读取 ''' [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] ''' print(arr.reshape((3 , 4), order='F')) # 类Fortan的索引顺序, ''' [ 0 3 6 9] [ 1 4 7 10] [ 2 5 8 11]] ''' print(arr.resize(3, 4)) # None,resize直接改变了数组维度,所以应该输出数组,而不是操作本身 print(arr) # resize后被改变了 ''' [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] ''' print(arr.reshape((2,2,3))) ''' [[[ 0 1 2] [ 3 4 5]] [[ 6 7 8] [ 9 10 11]]] '''
import numpy as np x = np.array([[1, 2, 3], [4, 5, 6]]) print(np.ravel(x)) # [1 2 3 4 5 6] print(np.ravel(x, order='F')) # [1 4 2 5 3 6] print(x) ''' [[1 2 3] [4 5 6]] ''' print(x.flatten()) # [1 2 3 4 5 6] print(x.flatten(order='F')) # [1 4 2 5 3 6] print(x.T) ''' [[1 4] [2 5] [3 6]] ''' print(np.transpose(x)) ''' [[1 4] [2 5] [3 6]] '''
import numpy as np x = np.arange(24).reshape(2, 3, 4) print(x) ''' [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] ''' print(x.flatten()) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] print(np.transpose(x,(0, 2, 1))) # (0, 2, 1)是轴,2层4行3列,4行3列的值是对1轴和2轴反转后得到。同print(np.moveaxis(x, 1, -1)) ''' ''' [[[ 0 4 8] [ 1 5 9] [ 2 6 10] [ 3 7 11]] [[12 16 20] [13 17 21] [14 18 22] [15 19 23]]] ''' ''' print(np.arange(24).reshape(2, 4, 3)) # 2层,4行3列 ''' [[[ 0 1 2] [ 3 4 5] [ 6 7 8] [ 9 10 11]] [[12 13 14] [15 16 17] [18 19 20] [21 22 23]]] ''' print(np.transpose(x,(1, 0, 2))) ''' [[[ 0 1 2 3] [12 13 14 15]] [[ 4 5 6 7] [16 17 18 19]] [[ 8 9 10 11] [20 21 22 23]]] ''' y = np.zeros((3, 4, 5)) print(y) ''' [[[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]]] ''' print(np.moveaxis(y, 0, -1).shape) # (4, 5, 3) print(np.moveaxis(y, 0, -1)) ''' [[[0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.]] [[0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.] [0. 0. 0.]]] ''' print(np.moveaxis(y, -1, 0).shape) # (5, 3, 4) print(np.moveaxis(y, -1, 0)) ''' [[[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]] [[0. 0. 0. 0.] [0. 0. 0. 0.] [0. 0. 0. 0.]]] ''' a = np.ones((3, 4, 5, 6)) print(np.rollaxis(a, 3, 1).shape) # (3, 6, 4, 5) print(np.rollaxis(a, 2).shape) # (5, 3, 4, 6) print(np.rollaxis(a, 1, 4).shape) # (3, 5, 6, 4)
数组合并
numpy.concatenate((a1, a2, ...), axis=0, out=None) # 沿着一条轴连接一组(多个)数组。除了与axis对应的轴之外,其它轴必须有相同的形状。
numpy.stack(arrays, axis=0, out=None) # 数组根据给定轴展开后排好队,然后堆叠起来
numpy.column_stack(tup) # 按列连接多个一维数组
numpy.row_stack(tup) #
numpy.dstack(tup) #
numpy.hstack(tup) # 水平(按列顺序)把数组堆叠起来
numpy.vstack(tup) # 垂直(按行顺序)把数组堆叠起来
numpy.block(arrays) #
import numpy as np u = np.array([[1, 2], [3, 4]]) v = np.array([[5, 6]]) print(np.concatenate((u, v), axis=0)) print(np.concatenate((u, v.T), axis=1)) print(np.concatenate((u, v), axis=None)) print(np.concatenate((u, v))) ''' print(np.concatenate((u, v), axis=0)) [[1 2] [3 4] [5 6]] print(np.concatenate((u, v.T), axis=1)) [[1 2 5] [3 4 6]] print(np.concatenate((u, v), axis=None)) [1 2 3 4 5 6] print(np.concatenate((u, v))) # axis默认参数0 [[1 2] [3 4] [5 6]] ''' x = np.array([[[1,2,3],[4,5,6]],[[21,22,23],[24,25,26]]]) y = np.array([[[7,8,9],[10,11,12]],[[27,28,29],[30,31,32]]]) print(np.stack((x,y),axis=0)) # 打开第一层盒子堆叠起来 [[1,2,3],[4,5,6]],[[21,22,23],[24,25,26]] print(np.stack((x,y),axis=1)) # 打开第二层盒子,按照对应顺序叠起来 [1,2,3],[4,5,6] 对应 [7,8,9],[10对应 [7,8,9],11,12] print(np.stack((x,y),axis=2)) # 打开第三层盒子,按照对应顺序叠起来 [1,2,3] 对应 [7,8,9] print(x.ndim) # 3 print(x.shape) # (2, 2, 3) ''' axis=0 [[[[ 1 2 3] [ 4 5 6]] [[21 22 23] [24 25 26]]] [[[ 7 8 9] [10 11 12]] [[27 28 29] [30 31 32]]]] axis=1 [[[[ 1 2 3] [ 4 5 6]] [[ 7 8 9] [10 11 12]]] [[[21 22 23] [24 25 26]] [[27 28 29] [30 31 32]]]] axis=2 [[[[ 1 2 3] [ 7 8 9]] [[ 4 5 6] [10 11 12]]] [[[21 22 23] [27 28 29]] [[24 25 26] [30 31 32]]]] ''' a=[[1],[2],[3]] b=[[1],[2],[3]] c=[[1],[2],[3]] d=[[1],[2],[3]] print(np.hstack((a,b,c,d))) ''' [[1 1 1 1] [2 2 2 2] [3 3 3 3]] ''' print(np.vstack((a,b,c,d))) ''' [[1] [2] [3] [1] [2] [3] [1] [2] [3] [1] [2] [3]] '''
数组拆分
numpy.split(ary, indices_or_sections, axis=0)
numpy.array_split(ary, indices_or_sections, axis=0)
numpy.dsplit(ary, indices_or_sections)
numpy.hsplit(ary, indices_or_sections)
numpy.vsplit(ary, indices_or_sections)
#数组的拆分 np.split np.hsplit np.vsplit import numpy as np x = [1, 2, 3, 99, 99, 3, 2, 1] x1, x2, x3 = np.split(x, [3, 5]) print(x1, x2, x3) # [1 2 3] [99 99] [3 2 1] grid = np.arange(16).reshape((4, 4)) upper, lower = np.vsplit(grid, [2]) left, right = np.hsplit(grid, [2]) print(grid) print(upper) print(lower) print(left) print(right) ''' #grid array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15]]) #upper [[0 1 2 3] [4 5 6 7]] #lower [[ 8 9 10 11] [12 13 14 15]] #left [[ 0 1] [ 4 5] [ 8 9] [12 13]] #right [[ 2 3] [ 6 7] [10 11] [14 15]] '''
数组的类型变换
数据类型的转换 :a.astype(new_type): eg, a.astype (np.float)
数组向列表的转换: a.tolist()
数组的索引和切片
'tobytes',
'tofile',
'tolist',
'tostring',
索引和切片
数组切片是原始数组的视图,不是复制品,如果要得到切片的副本,应该使用copy()方法
切片的基本语法 ndarray[startindex:endindex:stepsize],startindex为起始下标,endindex为结束下标(不包括j),stepsize为步长(默认为1)
import numpy as np a = np.array([[1,2,3,4,5,6,7],[8,9,10,11,12,13,14]]) print(a) ''' [[ 1 2 3 4 5 6 7] [ 8 9 10 11 12 13 14]] ''' print(a[1, 5]) # 取值 13 print(a[0, :]) # 取行 array([1, 2, 3, 4, 5, 6, 7]) print(a[:, 2]) # 取列 array([ 3, 10]) print(a[0, 1:-1:2]) # array([2, 4, 6]) print(a[0, ::2]) # [1 3 5 7] print(a[1 ,1]) # 9 print(a[1][1]) # 9 同print(a[1 ,1]),但运行速度更慢 print(a[1, [1, 2]]) # [ 9 10] 第2行的第1、2列元素 print(a[:2, [0, 1]]) # 前2行的第0、1列元素 ''' [[1 2] [8 9]] ''' a[1, 5] = 20 a[:, 2] = [30, 40] print(a) ''' [[ 1 2 30 4 5 6 7] [ 8 9 40 11 12 20 14]] ''' print(a[:2]) # 前两行 ''' [[ 1 2 3 4 5 6 7] [ 8 9 10 11 12 13 14]] ''' print(a[:2, :]) # 同 print(ndarr[:2]) print(a[:2,]) # 同 print(ndarr[:2]) print(a[:2, :2]) # 前两行的前两列 ''' [[1 2] [8 9]] ''' print(a[::2, -2]) # [6] 步长为2的行的倒数第二列
布尔索引
运算符 对应的通用函数
== np.equal
!= np.not_equal
< np.less
<= np.less_equal
> np.greater
>= np.greater_equal
统计记录的个数
如果需要统计布尔数组中True记录的个数,可以使用 np.count_nonzero 函数:
np.count_nonzero(x < 6) # 有多少值小于6?
np.sum(x < 6) # False会被解释成0, True会被解释成1:
np.sum(x < 6, axis=1) # 每行有多少值小于6? sum()的好处是,和其他NumPy聚合函数一样,这个求和也可以沿着行或列进行
np.any(x > 8) # 有没有值大于8? 如要快速检查任意或者所有这些值是否为True ,可以用np.any() 或 np.all()
np.all(x < 8, axis=1) # 是否每行的所有值都小于8?
np.all(x < 10) # 是否所有值都小于10?
逐位逻辑运算符(bitwise logic operator) & | ^ ~
运算符 对应通用函数
& np.bitwise_and
| np.bitwise_or
^ np.bitwise_xor
~ np.bitwise_not
np.sum((inches > 0.5) & (inches < 1))
使用布尔数组作为掩码,通过该掩码选择数据的子数据集
rainy = (inches > 0) # 为所有下雨天创建一个掩码
summer = (np.arange(365) - 172 < 90) & (np.arange(365) - 172 > 0) # 构建一个包含整个夏季日期的掩码(6月21日是第172天)
print("Median precip on non-summer rainy days (inches):", np.median(inches[rainy & ~summer]))
基于某些准则抽取、修改、计数或对一个数组中的值进行其他操作时,掩码非常有用。
例如统计数组中有多少值大于某一个给定值,或者删除所有超出阀值的异常值。
花式索引
花哨索引(fancy indexing)能够快速灵活获取和修改复杂数组的子数据集。
花哨索引传递的是索引数组,而不是单个标量。
花哨索引结果的形状与索引数组的形状一致,而不是与被索引数组的形状一致。
import numpy as np grid = np.arange(10) #[0 1 2 3 4 5 6 7 8 9] ind1 = [3, 7, 4] grid[ind1] # [3 7 4] # 花式索引 ind2 = np.array([[3, 7], [3, 4]]) grid[ind2] ''' [[3 7] [3 4]] ''' x = np.arange(16).reshape((4, 4)) print(x[2, [2, 0, 1]]) # 组合索引 print(x[1:, [2, 0, 1]]) ''' # x [[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11] [12 13 14 15]] # x[2, [2, 0, 1]] [10 8 9] # x[1:, [2, 0, 1]] [[ 6 4 5] [10 8 9] [14 12 13]] '''
通用函数
all, any, apply_along_axis, argmax, argmin, argsort, average, bincount, ceil, clip, conj, corrcoef, cov, cross, cumprod, cumsum, diff, dot, floor, inner, inv, lexsort, max, maximum, mean, median, min, minimum, nonzero, outer, prod, re, round, sort, std, sum, trace, transpose, var, vdot, vectorize, where
NumPy数组计算非常快关键是利用了向量化操作,向量化操作的两种实现方式:
1 用NumPy的通用函数(ufunc),提高数组元素重复计算的效率,NumPy中的向量操作是通过通用函数实现的。
2 利用NumPy的广播功能
数组运算
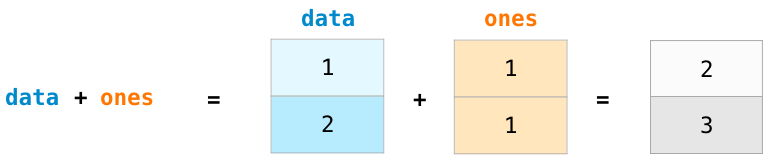
加减乘除


数组乘以数值

数组索引

数组的计算:广播
广播可以简单理解为用于不同大小数组的二进制通用函数(加、减、乘等)的一组规则。
广播的规则
NumPy的广播遵循一组严格的规则,设定这组规则是为了决定两个数组间的操作。
• 规则 1:如果两个数组的维度数不相同,那么小维度数组的形状将会在最左边补1。
• 规则 2:如果两个数组的形状在任何一个维度上都不匹配,那么数组的形状会沿着维度为1的维度扩展以匹配另外一个数组的形状。
• 规则 3:如果两个数组的形状在任何一个维度上都不匹配并且没有任何一个维度等于1,那么会引发异常。

矩阵
创建矩阵
直接创建:
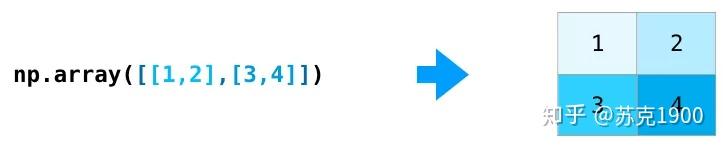
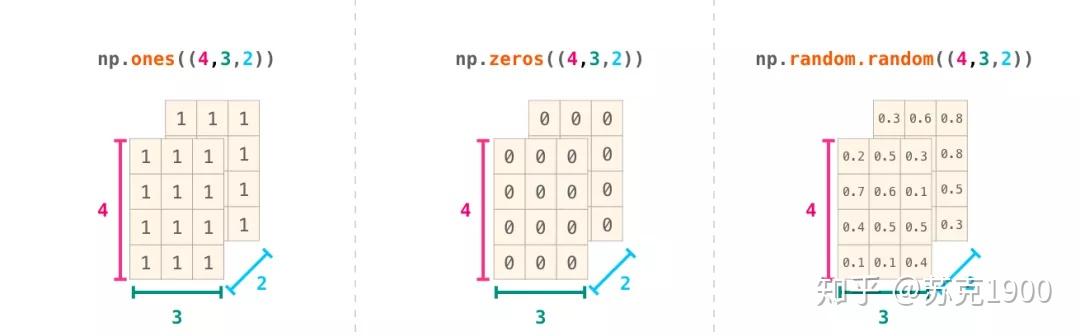
使用 np.ones()、np.zeros() 等方法:

这样就很容易理解括号里 (3,2) 的含义。
矩阵运算
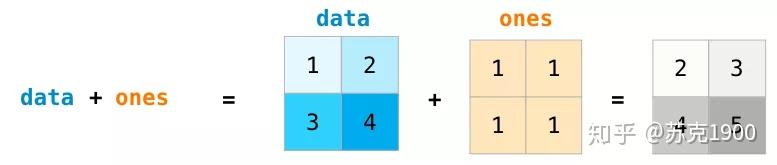

矩阵点积
矩阵点积跟线性代数基本一样,有些抽象,借助示意图能很好理解:

进一步拆分解释:

矩阵索引
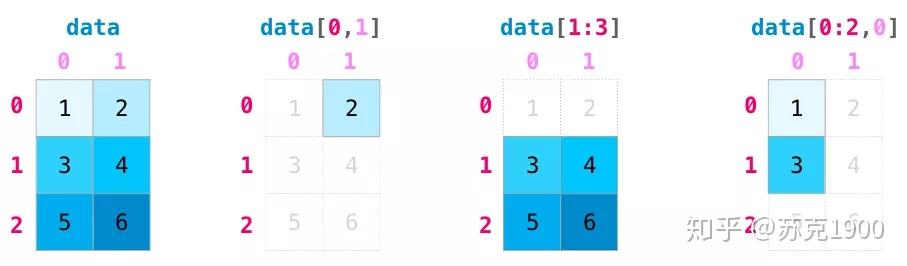
矩阵聚合
求最值

按行 / 列聚合

矩阵转置

矩阵重塑
reshape() 用法:
高维数组
Numpy 不仅可以处理上述的一维数组和二维矩阵,还可以处理任意 N 维的数组,方法也大同小异。
创建多维数组
掌握了以上基础后,我们可以做个小练习,计算均方误差 MSE:
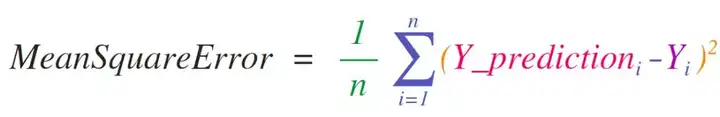
可以看到有减法、平方、求和等运算:
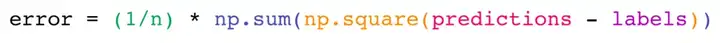
分别假设相应的预测值和真实值:




Functions and Methods Overview
Here is a list of some useful NumPy functions and methods names ordered in categories. See Routines for the full list.
- Array Creation
-
arange,array,copy,empty,empty_like,eye,fromfile,fromfunction,identity,linspace,logspace,mgrid,ogrid,ones,ones_like, r,zeros,zeros_like - Conversions
- Manipulations
-
array_split,column_stack,concatenate,diagonal,dsplit,dstack,hsplit,hstack,ndarray.item,newaxis,ravel,repeat,reshape,resize,squeeze,swapaxes,take,transpose,vsplit,vstack - Questions
- Ordering
- Operations
-
choose,compress,cumprod,cumsum,inner,ndarray.fill,imag,prod,put,putmask,real,sum - Basic Statistics
- Basic Linear Algebra
-
cross,dot,outer,linalg.svd,vdot