实验目的
了解集群运行的原理
学习mapred和yarn脚本原理
学习使用Hadoop命令提交mapreduce程序
学习对mapred、yarn脚本进行基本操作
实验原理
1.hadoop的shell脚本
上一节介绍了hadoop脚本的使用,这一节介绍mapreduce和yarn的shell命令,对应的脚本为hadoop安装目录下的bin目录里面的mapred文件和yarn文件。下面分别是mapred和yarn文件的部分内容:
mapred
if [ "$COMMAND" = "job" ] ; then
CLASS=org.apache.hadoop.mapred.JobClient
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_CLIENT_OPTS"
elif [ "$COMMAND" = "queue" ] ; then
CLASS=org.apache.hadoop.mapred.JobQueueClient
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_CLIENT_OPTS"
elif [ "$COMMAND" = "pipes" ] ; then
CLASS=org.apache.hadoop.mapred.pipes.Submitter
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_CLIENT_OPTS"
elif [ "$COMMAND" = "sampler" ] ; then
CLASS=org.apache.hadoop.mapred.lib.InputSampler
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_CLIENT_OPTS"
elif [ "$COMMAND" = "classpath" ] ; then
echo -n
elif [ "$COMMAND" = "historyserver" ] ; then
CLASS=org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer
yarn
if [ "$COMMAND" = "classpath" ] ; then
echo $CLASSPATH
exit
elif [ "$COMMAND" = "rmadmin" ] ; then
CLASS='org.apache.hadoop.yarn.client.cli.RMAdminCLI'
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
elif [ "$COMMAND" = "application" ] ||
[ "$COMMAND" = "applicationattempt" ] ||
[ "$COMMAND" = "container" ]; then
CLASS=org.apache.hadoop.yarn.client.cli.ApplicationCLI
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
set -- $COMMAND $@
elif [ "$COMMAND" = "node" ] ; then
CLASS=org.apache.hadoop.yarn.client.cli.NodeCLI
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
elif [ "$COMMAND" = "resourcemanager" ] ; then
CLASSPATH=${CLASSPATH}:$YARN_CONF_DIR/rm-config/log4j.properties
CLASS='org.apache.hadoop.yarn.server.resourcemanager.ResourceManager'
YARN_OPTS="$YARN_OPTS $YARN_RESOURCEMANAGER_OPTS"
if [ "$YARN_RESOURCEMANAGER_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_RESOURCEMANAGER_HEAPSIZE""m"
fi
elif [ "$COMMAND" = "historyserver" ] ; then
echo "DEPRECATED: Use of this command to start the timeline server is deprecated." 1>&2
echo "Instead use the timelineserver command for it." 1>&2
CLASSPATH=${CLASSPATH}:$YARN_CONF_DIR/ahs-config/log4j.properties
CLASS='org.apache.hadoop.yarn.server.applicationhistoryservice.ApplicationHistoryServer'
YARN_OPTS="$YARN_OPTS $YARN_HISTORYSERVER_OPTS"
if [ "$YARN_HISTORYSERVER_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_HISTORYSERVER_HEAPSIZE""m"
fi
elif [ "$COMMAND" = "timelineserver" ] ; then
CLASSPATH=${CLASSPATH}:$YARN_CONF_DIR/timelineserver-config/log4j.properties
CLASS='org.apache.hadoop.yarn.server.applicationhistoryservice.ApplicationHistoryServer'
YARN_OPTS="$YARN_OPTS $YARN_TIMELINESERVER_OPTS"
if [ "$YARN_TIMELINESERVER_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_TIMELINESERVER_HEAPSIZE""m"
fi
elif [ "$COMMAND" = "nodemanager" ] ; then
CLASSPATH=${CLASSPATH}:$YARN_CONF_DIR/nm-config/log4j.properties
CLASS='org.apache.hadoop.yarn.server.nodemanager.NodeManager'
YARN_OPTS="$YARN_OPTS -server $YARN_NODEMANAGER_OPTS"
if [ "$YARN_NODEMANAGER_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_NODEMANAGER_HEAPSIZE""m"
fi
elif [ "$COMMAND" = "proxyserver" ] ; then
CLASS='org.apache.hadoop.yarn.server.webproxy.WebAppProxyServer'
YARN_OPTS="$YARN_OPTS $YARN_PROXYSERVER_OPTS"
if [ "$YARN_PROXYSERVER_HEAPSIZE" != "" ]; then
JAVA_HEAP_MAX="-Xmx""$YARN_PROXYSERVER_HEAPSIZE""m"
fi
elif [ "$COMMAND" = "version" ] ; then
CLASS=org.apache.hadoop.util.VersionInfo
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
elif [ "$COMMAND" = "jar" ] ; then
CLASS=org.apache.hadoop.util.RunJar
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
elif [ "$COMMAND" = "logs" ] ; then
CLASS=org.apache.hadoop.yarn.client.cli.LogsCLI
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
elif [ "$COMMAND" = "daemonlog" ] ; then
CLASS=org.apache.hadoop.log.LogLevel
YARN_OPTS="$YARN_OPTS $YARN_CLIENT_OPTS"
else
CLASS=$COMMAND
fi
可以看出无论是mapred还是yarn,都是根据命令参数的不同,调用不同的java类,启动对应的进程进行处理。我们要想深入了解原理,其实最简单有用的就是查看这些java类的代码。
2.在集群上运行
目前,程序已经可以在少量测试数据上正确运行。实验中我们以Hadoop自带的程序为例进行简单的运行。
1.打包作业
本地作业运行器使用单JVM运行一个作业,只要作业需要的所有类都在类路径(classpath)上,那么作业就能正常执行。
在分布式的环境中,情况稍微复杂一点。开始的时候作业的类必须打包成一个作业JAR文件并发送到集群。Hadoop通过搜索驱动程序的类路径自动找到该作业JAR文件,该文件路径包含JobConf或Job上的setJarByClass()方法中设置的类。另一种方法:如果想通过文件路径设置一个指定的JAR文件,可以使用setJar()方法。JAR文件的路径可以是本地的,也可以是hdfs文件路径。
1)客户端的类路径
有Hadoop jar <jar>设置的用户客户端类路径包括以下几个组成部分:
作业的JAR文件
作业JAR文件的lib目录中的所有JAR文件以及classes目录(如果定义)
HADOP_CLASSPH定义的类路径(如果已经设置)
这解释了如果用户在没有作业JAR(hadoop CLASSNAME)情况下使用本地作业运行器时,为什么必须设置HADOOP_CLASSPH来指明依赖类和库。
2)任务的类路径
在集群上(包括伪分布式模式),map和reduce任务在各自的JVM上运行,他们的类路径不受HADOOP_CLASSPH控制。HADOOP_CLASSPH是一项客户端设置,并只针对驱动程序的JVM的类路径进行设置。
反之,用户任务的类路径有以下几个部分组成:
作业的JAR文件
作业JAR文件的lib目录中包含的所有JAR文件以及classes目录(如果存在的话)
使用-libjars选项或DistributedCache的addFileToClassPath()方法或Job添加到分布式缓存的所有文件
3)打包依赖
给定这些不同的方法来用控制客户端和类路径上的内容,也有相应的操作处理作业的库依赖:
将库解包和重新打包进作业JAR
将作业JAR的lib目录中库打包
保持库与做作业JAR分开,并通过HADOOP_CLASSPH将它们添加到客户端的类路径,通过-libjars将它们添加到任务的类路径
从创建的角度来看,最后用分布式缓存的选项是最简单的,因为依赖不需要在作业的JAR中重新创建。同时,使用分布式缓存意味着在集群上更少的JAR文件转移,因为文件可能缓存在任务间的一个节点上了。
4)任务类路径的优先权
用户的JAR文件被添加到客户端类路径和任务类路径的最后,如果Hadoop使用的库版本和用户代码使用的不同或不相容,在某些情况下可能会引发和Hadoop内置库的依赖冲突。有时需要控制任务类路径的次序。这样用户的类就会被先提取出来。在客户端,可以通过设置环境变量HADOOP_USER_CLASSPH_FIRST为true,强制使Hadoop将用户的类路径优先放置在搜索顺序中。
2.启动作业
为了启动作业,我们需要运行驱动程序,使用-conf选项来指定想要运行作业的集群(同样也可以使用-fs和-jt选项)。
Job上的waitForCompletion()方法启动作业并检查进展情况。如果有任何变化,就输出一行map和reduce进度总结。具体见步骤3.2输出结果。
实验环境
1.操作系统
服务器:Linux_Centos
操作机:Windows_7
服务器默认用户名:root,密码:123456
操作机默认用户名:hongya,密码:123456
2.实验工具
1.Xshell

Xshell是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及Microsoft Windows 平台的TELNET 协议。Xshell 通过互联网到远程主机的安全连接以及它创新性的设计和特色帮助用户在复杂的网络环境中享受他们的工作。
Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的。实验中我们用到XShell5,其新增功能有:
1.有效保护信息安全性;Xshell支持各种安全功能,如SSH1/SSH2协议,密码,和DSA和RSA公开密钥的用户认证方法,并加密所有流量的各种加密算法。重要的是要保持用户的数据安全与内置Xshell安全功能,因为像Telnet和Rlogin这样的传统连接协议很容易让用户的网络流量受到任何有网络知识的人的窃取。Xshell将帮助用户保护数据免受黑客攻击。
2.最好的终端用户体验;终端用户需要经常在任何给定的时间中运用多个终端会话,以及与不同主机比较终端输出或者给不同主机发送同一组命令。Xshell则可以解决这些问题。此外还有方便用户的功能,如标签环境,广泛拆分窗口,同步输入和会话管理,用户可以节省时间做其他的工作。
3.代替不安全的Telnet客户端;Xshell支持VT100,VT220,VT320,Xterm,Linux,Scoansi和ANSI终端仿真和提供各种终端外观选项取代传统的Telnet客户端。
4. Xshell在单一屏幕实现多语言;Xshell中的UTF-8在同类终端软件中是第一个运用的。用Xshell,可以将多种语言显示在一个屏幕上,无需切换不同的语言编码。越来越多的企业需要用到UTF-8格式的数据库和应用程序,有一个支持UTF-8编码终端模拟器的需求在不断增加。Xshell可以帮助用户处理多语言环境。 5. 支持安全连接的TCP/IP应用的X11和任意;在SSH隧道机制中,Xshell支持端口转发功能,无需修改任何程序,它可以使所有的TCP/IP应用程序共享一个安全的连接。
2.Mapred
所有的Hadoop命令都通过bin/mapred脚本调用。在没有任何参数的情况下,运行mapred脚本将打印该命令描述。
使用:mapred [--config confdir] COMMAND
用户命令:以job为例,通过job命令和MapReduce任务交互。
使用:mapred job | [GENERIC_OPTIONS] | [-submit <job-file>] | [-status <job-id>] | [-counter <job-id> <group-name> <counter-name>] | [-kill <job-id>] | [-events <job-id> <from-event-#> <#-of-events>] | [-history [all] <jobOutputDir>] | [-list [all]] | [-kill-task <task-id>] | [-fail-task <task-id>] | [-set-priority <job-id> <priority>]
参数选项:
-submit job-file:提交一个job.
-status job-id:打印map任务和reduce任务完成百分比和所有JOB的计数器。
-counter job-id group-name counter-name:打印计数器的值。
-kill job-id:根据job-id杀掉指定job.
-events job-id from-event-# #-of-events:打印给力访问内jobtracker接受到的事件细节。
-history [all]jobOutputDir:打印JOB的细节,失败和杀掉原因的细节。更多的关于一个作业的细节比如:成功的任务和每个任务尝试等信息可以通过指定[all]选项查看。
-list [all] :打印当前正在运行的JOB,如果加了all,则打印所有的JOB。
-kill-task task-id:Kill任务,杀掉的任务不记录失败重试的数量。
-fail-task task-id:Fail任务,杀掉的任务不记录失败重试的数量。默认任务的尝试次数是4次超过四次则不尝试。那么如果使用fail-task命令fail同一个任务四次,这个任务将不会继续尝试,而且会导致整个JOB失败。
-set-priority job-id priority:改变JOB的优先级。允许的优先级有:VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW
3.Yarn
yarn命令由bin/yarn下面的脚本调用。不带任何参数运行yarn脚本会打印所有命令的描述。
用法: yarn [--config confdir] COMMAND
YARN有一个参数解析框架,采用解析泛型参数以及运行类。


用户命令:
对于Hadoop集群用户很有用的命令:(以application为例进行说明)
使用: yarn application [options]
-appStates <States>:使用-list命令,基于应用程序的状态来过滤应用程序。如果应用程序的状态有多个,用逗号分隔。 有效的应用程序状态包含如下: ALL, NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED。
-appTypes <Types>:使用-list命令,基于应用程序类型来过滤应用程序。如果应用程序的类型有多个,用逗号分隔。
-list:从RM返回的应用程序列表,使用-appTypes参数,支持基于应用程序类型的过滤,使用-appStates参数,支持对应用程序状态的过滤。
-kill <ApplicationId>:kill掉指定的应用程序。
-status <ApplicationId>:打印应用程序的状态。
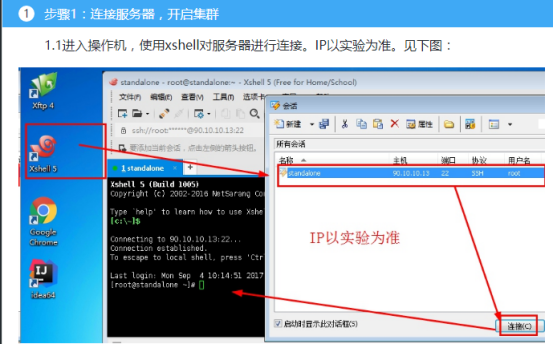
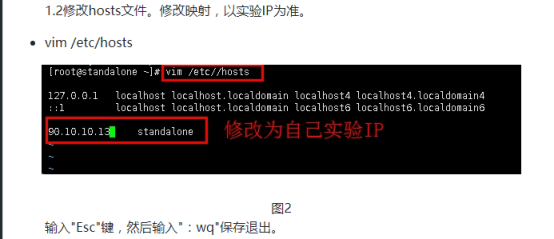
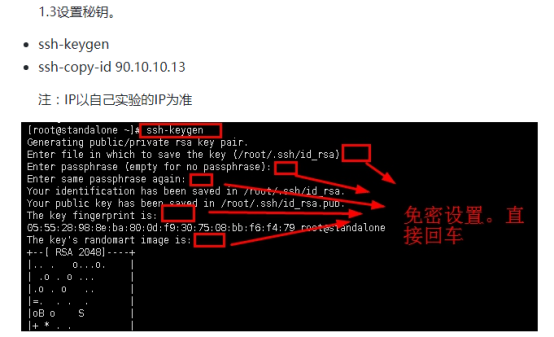
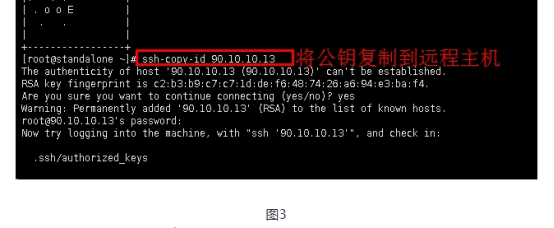
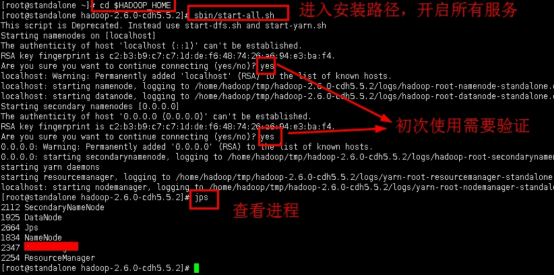
1.4开启Hadoop集群,查看进程。
进入安装包目录
cd $HADOOP_HOME
开启所有服务
sbin/start-all.sh
查看进程
jps
1.5关闭防火墙,同步时间。
service iptables stop
单个服务器,也可不用时间同步
date -s 10:00
date

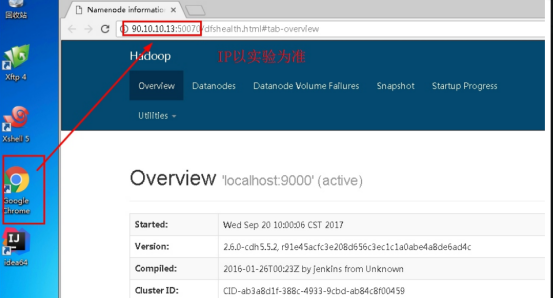
1.6打开浏览器,查看集群是否启动成功。
输入URL(IP以实验为准):90.10.10.13:50070
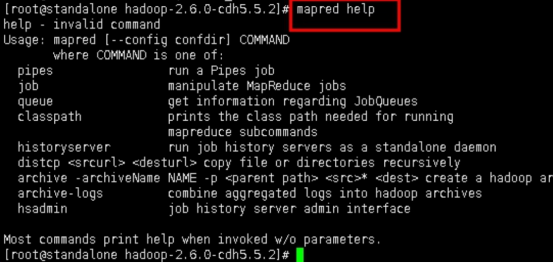
步骤2:使用help命令查看帮助
2.1当第一次使用命令的时候,直接敲commond help,会有命令提示。使用help命令查看相关命令信息。
mapred help
2.2我们会发现mapred脚本的选项很少,例如对于job选项,我们继续看帮助。
mapred job
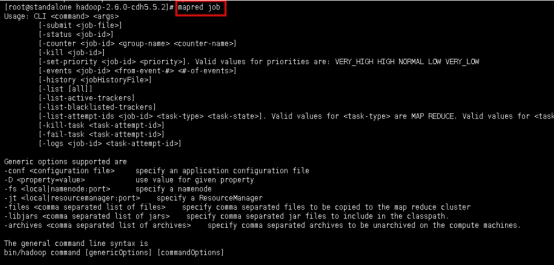
这时会发现可选参数也不多,用的较多的是submit、kill、logs、list等。
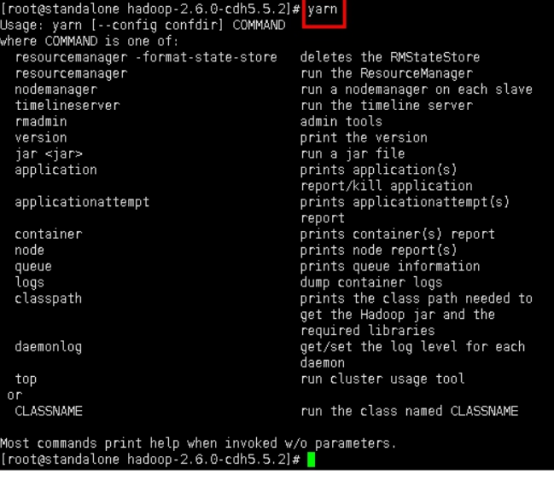
2.3对于yarn也是一样查看帮助,直接输入yarn即可。
yarn
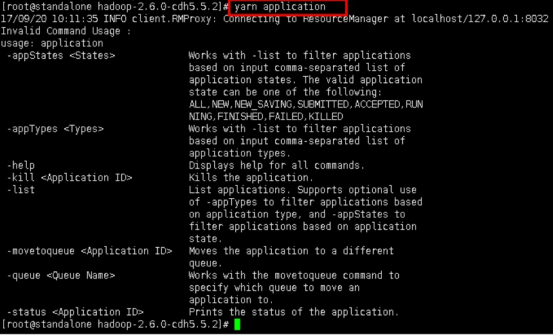
2.4再进一步查看application的参数。
yarn application
步骤3:了解简单的命令使用
由于我们还没学习写mapreduce或者storm、flink等程序,所以本次实验很多内容只能简单介绍。学习到相应的课程后,我们写的程序也需要通过今天学习的命令进行提交,查看,监控等。
3.1将本地文件上传到hdfs。
cd ~
ls
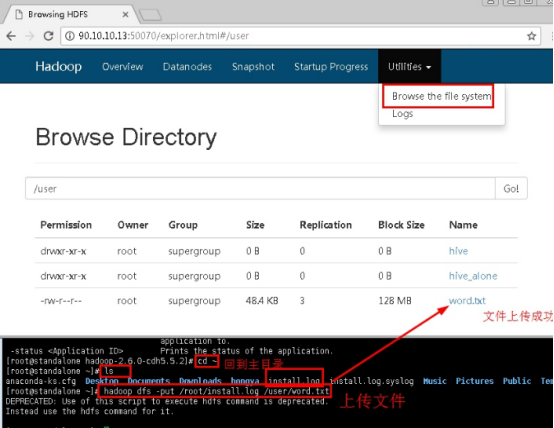
将root目录下的install.log上传hdfs的/user目录下,并重命名为word.txt。
hadoop dfs -put /root/install.log /user/word.txt
3.2提交程序,提交mapreduce程序的命令为hadoop jar <jar-file> <args>,我们以hadoop自带的wordcount为例。
hadoop jar /home/hadoop/tmp/hadoop-2.6.0-cdh5.5.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.5.2.jar wordcount /user/word.txt /user/test/
后面两个目录是hdfs的目录,第一个目录是存在的,第二个是命令运行之后自创建的,必须不存在。
注意:在程序开启时,需要使用命令监听其ID等信息,这是同步进行的。如果程序启动完成,再去查看,我们则得不到任何信息。可以先将命令输入好,之后再一起执行。先看实验步骤3.3和3.4、3.5。
如果此次程序启动完成了,再次启动会报错。因为实验中"/user/test/"已经建立。可以使用命令删除此文件然后再次启动程序;也可以将上传位置改为"/user/test1/"(上传位置不同了,就不会造成冲突),然后启动命令。
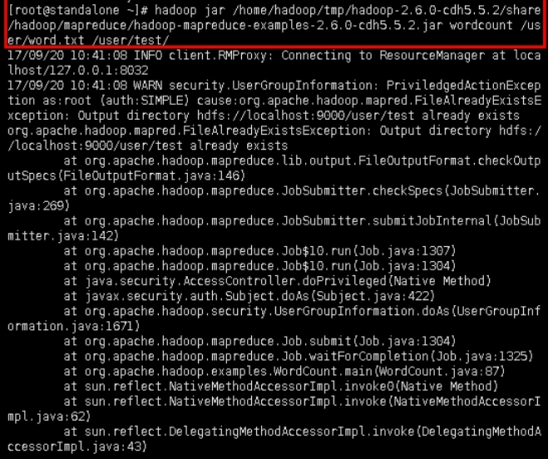
这里的jar包是hadoop自带的,可能最后的版本号不一样,hadoop jar命令后面的内容分别代表jar文件目录、程序名(或者主类)、输入目录、输出目录。输出包括很多有用的信息。在作业开始之前,打印作业ID;如果需要在日志文件中或通过mapred job命令查询弄个作业,必须要有ID信息。作业完成后统计信息被打印出来。这对于确认作业是否完成时很有用的。
3.3在程序结束之前使用mapred命令查看程序.如下图复制一个xshell窗口。

结果会显示mapred程序的相关信息,包括运行状态、提交用户、application master等。
3.5在程序结束之前使用yarn命令查看程序。
yarn application -list

MapReduce作业ID有YARN资源管理器创建的yarn应用ID生成。一个应用ID的格式包含两部分:资源管理器(不是应用)开始时间和唯一标识此应用的由资源管理器的增量计算器。
结果中ID为:application_1505872841517_0004的应用是资源管理器运行的第四个应用(0004;应用ID从1开始计数),时间戳1505872841517表示资源管理器开始时间。计数器的数字前面由0开始,以便于ID在目录列表中进行排序。然而,计数器达到10000时,不能重新设置,会导致应用ID更长。
将应用ID的application前缀替换为job前缀即可得到相应的作业ID。