实验目的
了解Hadoop的概念和原理
学习HDFS架构原理
熟悉mapreduce框架
熟悉mapred和yarn命令
实验原理
1.hadoop和hadoop生态系统
hadoop的思想来源是Google,Google曾经面对一个问题,大量的网页怎么存储,怎么快速搜索的问题,于是三篇论文诞生了GFS、Map-Reduce、BigTable,这三篇论文的开源实现版本分别就是hadoop的hdfs、mapreduce和hbase,分别对应大数据存储、大数据分析计算、列式非关系型数据库。
hadoop本身就是一个软件,一个用java写好的软件,只要你电脑上装好了jdk,就能运行。hadoop1.0软件本身有两个模块,hdfs和mapreduce,hadoop2.0添加了一个yarn。hdfs做存储、mapreduce做计算,yarn做计算资源管理。
hadoop生态系统则是指围绕hadoop建立起的一整套开源软件,包括了做高可用的zookeeper、非关系型数据库hbase、机器学习框架mahout、数据仓库hive、日志收集工具flume、流式计算框架storm等。
2.HDFS
试想一下,每天数以亿计的访问量,产生的大量的数据,我们可以分开存储,每一台机器存储一天、或者一个小时的数据,当我们需要这些数据的时候,根据存储的规则去对应的机器找。但是这样带来的问题是销量的降低,我们还要分开在每个机器进行计算,然后再汇总计算。要是有一台机器有无限大的磁盘存储、无限大的内存,那我们可以将所有的数据都放到这台超级计算机上,计算的时候,也可以只在这一台机器进行计算,不用管数据的分布情况。但是这样的机器是很难制造出来的,成本也特别高。而hadoop就解决了这个问题。hadoop将很多廉价的服务器,连接在一起,通过事先写好的规则,进行存储服务。这样就算数据量再大,只需要hadoop管理即可,我自己并不关心这是一台机器还是很多机器。这和人才培养也是一样的,我们不可能投入很大的精力去培养一个超级英雄,而是制定规则将很多人团结起来,成本低效率高。
hdfs就是一个分布式存储系统,提供了高可靠性、高扩展性和高吞吐率的数据存储服务。
HDFS架构:
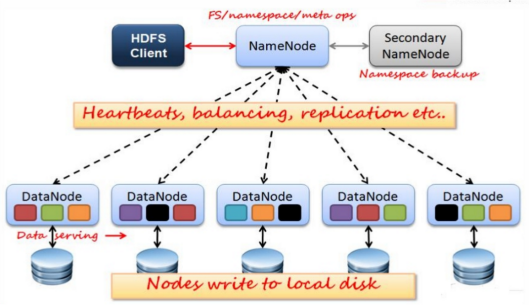
如上图,hadoop的数据都会被切成块,每个块默认是64M,如果没有64M也是一块,然后每个块会默认有三个副本,三个块存放在某些专门存数据的节点,这些节点称为datanode,而每个数据的目录的数据大小、位置以及怎么切分这些元数据,则存放在另一个节点,这个节点叫namenode。用户client只能通过namenode和hdfs交互,发送给namenode命令,假如我们给namenode发送读数据的命令,namenode根据命令找到数据的路径,得到数据的数据块,再找到每个数据块存放的datanode,如果在本地,直接读取数据,如果在远程节点,需要通过网络传输到本地,再将所有的数据块合并成文件返回。这样的话,假如namenode故障,整个数据都会丢掉,所以hadoop1.0还有一个secondary namenode,通过一定的机制隔一段时间备份一次数据。
3.mapreduce
hdfs解决了数据存储的问题,然后就是计算。数据量大的情况下,可能存在于不同节点,而mapreduce内部机制成功实现了移动计算,而不是移动数据,大大提高计算效率,但是这些机制对开发者是透明的,也就是说,开发者并不需要知道怎么写分布式程序,只要会写单机程序就可以实现分布式计算。
mapreduce框架
mapreduce是一个计算框架,概念"Map(映射)"和"Reduce(归约)",是它们的主要思想。mapreduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
mapreduce的数据类型都是(key,value)型的,map的任务是对输入的每一条数据进行处理,写出你要的业务数据,而map的数据到了reduce端的时候,每个key一样的数据,他们的value会在一个迭代器里面,reduce的任务就是处理这个迭代器。map到reduce中间的过程为shuffle,shuffle首先会根据partition规则, 将每一个map输出到一个reduce,然后根据自定义的group和sorter,对每一个reduce的数据进行分组和排序。
(1).Mapper
我们自定义的map(映射)需要继承Mapper类,如下面的代码,程序执行顺序是首先执行setup,然后对每一条数据循环遍历执行map方法,最后执行cleanup方法:
static class AppMap extends Mapper<LongWritable, Text, Text, Text> {
@Override
public void setup(Context context) throws IOException {
}
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
(2).Reducer
和Mapper一样,我们自定义的reduce需要继承Reducer类,如下面的代码,程序执行顺序是首先执行setup,然后对每一个key对应的values循环遍历执行reduce方法,最后执行cleanup方法,下一节会详细解析:
static class AppReduce extends Reducer<Text, Text, Text, NullWritable> {
private ReducerChains<String[], String[]> globalChains = new ReducerChains<String[], String[]>();
@Override
public void setup(Context context) throws IOException,
InterruptedException {
}
@Override
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
}
}
(3).shuffle
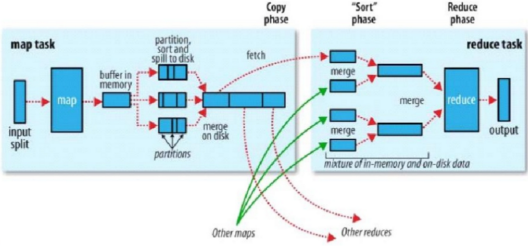
上图为hadoop官方给的shuffle示意图,所有的map输出后,首先会存在内存,或者溢写到磁盘,然后所有的数据会根据分区函数计算出每条记录应该被输入到哪个reduce,每一个reduce的所有数据会根据定义的函数进行分组、排序。shuffle过程是mapreduce的精髓所在。
4.hadoop2.x的新改变
hadoop1.0我们等一下会详细介绍。首先hdfs会用datanode和namenode,namenode由于单点故障问题,为了保证安全,还有一个secondary namenode,顾名思义就是一个备份的namenode,但是他是隔一段时间备份一次,所以并不能完全保证高可用,hadoop2.0通过zookeeper实现了真正的高可用。
hadoop1.0的mapreduce调度方式也存在单点故障问题,2.0推出了yarn做资源调度框架,yarn是一个优秀的资源调度框架,将资源抽象为container,实现最优化利用和调度。其他的程序,包括spark、storm、flink等,都可以使用yarn进行调度。
实验环境
1.操作系统
操作机1:Linux_Centos
操作机2:Windows_7
操作机1默认用户名:root,密码:123456
操作机2默认用户名:hongya,密码:123456
2.实验工具
2.Mapred
所有的Hadoop命令都通过bin/mapred脚本调用。在没有任何参数的情况下,运行mapred脚本将打印该命令描述。
使用:mapred [--config confdir] COMMAND
用户命令:
以job为例,通过job命令和MapReduce任务交互。
使用:mapred job | [GENERIC_OPTIONS] | [-submit <job-file>] | [-status <job-id>] | [-counter <job-id> <group-name> <counter-name>] | [-kill <job-id>] | [-events <job-id> <from-event-#> <#-of-events>] | [-history [all] <jobOutputDir>] | [-list [all]] | [-kill-task <task-id>] | [-fail-task <task-id>] | [-set-priority <job-id> <priority>]
参数选项
-submit job-file:提交一个job。
-status job-id:打印map任务和reduce任务完成百分比和所有JOB的计数器。
-counter job-id group-name counter-name:打印计数器的值。
-kill job-id:根据job-id杀掉指定job.
-events job-id from-event-# #-of-events:打印给力访问内jobtracker接受到的事件细节。
-history [all]jobOutputDir:打印JOB的细节,失败和杀掉原因的细节。更多的关于一个作业的细节比如:成功的任务和每个任务尝试等信息可以通过指定[all]选项查看。
-list [all] :打印当前正在运行的JOB,如果加了all,则打印所有的JOB。
-kill-task task-id:Kill任务,杀掉的任务不记录失败重试的数量。
-fail-task task-id:Fail任务,杀掉的任务不记录失败重试的数量。默认任务的尝试次数是4次超过四次则不尝试。那么如果使用fail-task命令fail同一个任务四次,这个任务将不会继续尝试,而且会导致整个JOB失败。
-set-priority job-id priority:改变JOB的优先级。允许的优先级有:VERY_HIGH, HIGH, NORMAL, LOW, VERY_LOW
3.Yarn
yarn命令由bin/yarn下面的脚本调用。不带任何参数运行yarn脚本会打印所有命令的描述。
用法:yarn [--config confdir] COMMAND
YARN有一个参数解析框架,采用解析泛型参数以及运行类。

表A:
用户命令:
对于Hadoop集群用户很有用的命令:(以application为例进行说明)
用法: yarn application [options]
-appStates <States>:使用-list命令,基于应用程序的状态来过滤应用程序。如果应用程序的状态有多个,用逗号分隔。 有效的应用程序状态包含如下: ALL, NEW, NEW_SAVING, SUBMITTED, ACCEPTED, RUNNING, FINISHED, FAILED, KILLED。
-appTypes <Types>:使用-list命令,基于应用程序类型来过滤应用程序。如果应用程序的类型有多个,用逗号分隔。
-list:从RM返回的应用程序列表,使用-appTypes参数,支持基于应用程序类型的过滤,使用-appStates参数,支持对应用程序状态的过滤。
-kill <ApplicationId>:kill掉指定的应用程序。
-status <ApplicationId>:打印应用程序的状态。
步骤1:使用xshell连接
1.1实验中已经准备好了hadoop的集群,使用xshell登陆到虚拟机(IP以实验为准),输入相应的用户名和密码进入操作机2(win_7),点击xshell,新建会话standalone,见下图。
图1
1.2点击“用户身份验证”,输入操作机1的用户名和密码,点击确定。会话建立成功。
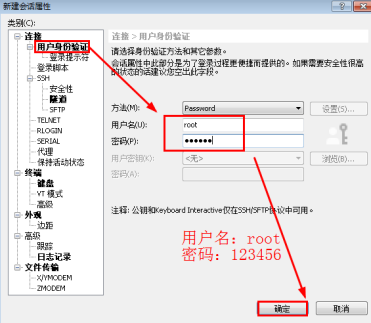
图2
1.3选中新建立的会话,点击连接,可以看到连接成功。
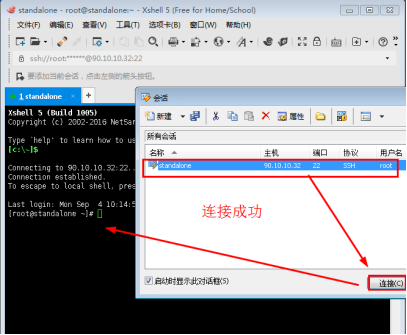
图3
步骤2:添加映射,配置秘钥
2.1为了能正常使用hadoop集群,要执行以下三步命令,首先编辑文件/etc/hosts,添加映射。
命令:vi /etc/hosts
添加内容:90.10.10.32 standalone
添加完毕后,按“ESC”键退出编辑模式,再输入“wq”保存退出
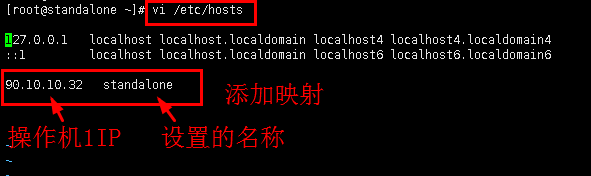
图4
2.2配置秘钥。
命令(输入后,连续回车):ssh-keygen
命令(主机映射名(或主机ip)为示例映射名(或IP)):ssh-copy-id 90.10.10.32

图5
2.3开启集群命令。(出现选项是,输入yes确认)
命令:cd $HADOOP_HOME
命令:sbin/start-all.sh
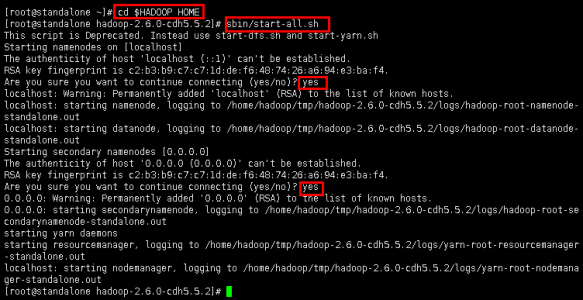
图6
2.4查看进程。
命令:jps
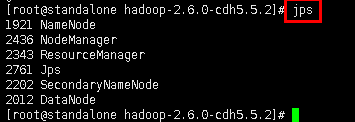
图7
步骤3:查看hdfs文件
3.1操作机2中,点击打开浏览器,访问操作机1(此处为操作机1的IP),可以看到其已经搭建了一个集群,见下图:
访问URL:90.10.10.32:50070
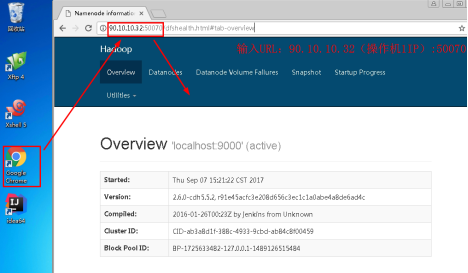
图8
3.2点击最右边的utilities|Browse the file system,可以浏览文件系统。
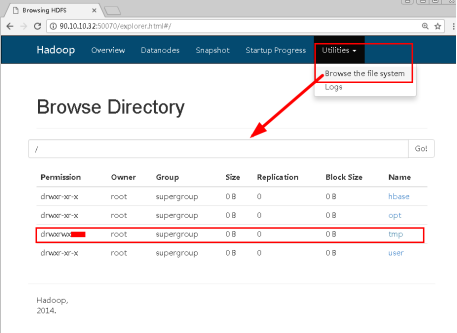
图9
3.3随便选择一个文件,查看其Block信息,如果大于64M,就会有多余一个Block。实验中以/opt/soft/apache-hive-1.2.1-bin中hive-hbase-handler-1.2.1.jar为例,查看其信息。

图10
步骤4:熟悉Hadoop参数mapred命令
4.1操作机2中,进入xshell工具,回到主目录,然后输入命令查看mapred帮助。
回到主目录:cd ~
查看帮助:mapred
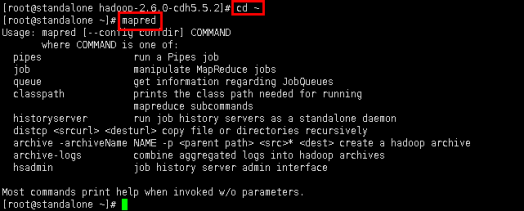
图11
4.2上图中可以看到mapred的命令格式和选择项,我们选择查看其job命令的用法。
命令:mapred job
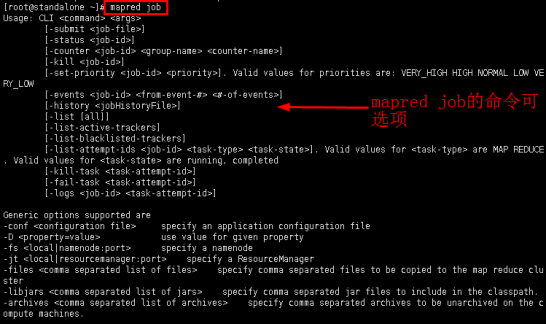
图12
4.3查看集群的运行的所有程序.
命令:mapred job -list
可以看到当前集群没有提交mapreduce任务

图13
步骤5:熟悉yarn(管理系统 )命令
5.1同理,在xshell输入yarn回车,查看yarn的命令使用规则。
命令:yarn

图14
5.2根据提示测试上面的命令,进行测试,如果我们想知的yarn application的用法,直接输入这个命令,提示就会出来:
命令:yarn application
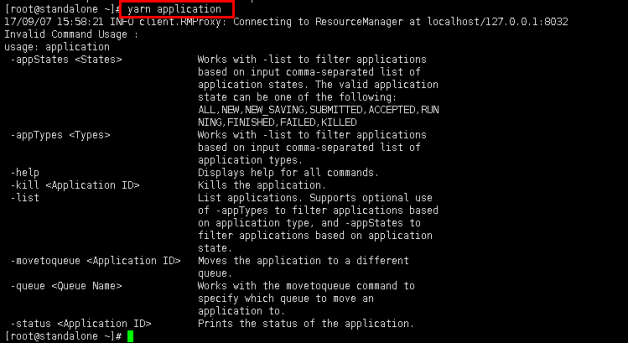
图15
5.3查看所有的任务
命令:yarn application -list
看到当前的yarn集群没有提交任务。

图16