#-*- coding:utf-8 -*- import time import keras import skimage import numpy as np import tensorflow as tf import matplotlib.image as img from scipy import ndimage from skimage import color, data, transform %matplotlib inline
#设置文件目录 Training = r'F:\data\fruits-360\Training' Test = r'F:\data\fruits-360\Test'
import os from natsort import natsorted #获取每类水果中的第五张图像 def load_print_img(root): print_img = [] print_label = [] #遍历水果种类目录 for i in range(len(os.listdir(root))): child1 = os.listdir(root)[i] child2 = os.listdir(os.path.join(root, child1)) #对第二层目录进行自然数排序,os.listder默认为str排序 child2 = natsorted(child2) #取出每类的第五张图像 path = os.path.join(root, child1, child2[4]) if(path.endswith('.jpg')): print_img.append(skimage.data.imread(path)) print_label.append(child1) return print_img, print_label print_img, print_label = load_print_img(Test) print(np.shape(print_img)) print(np.shape(print_label)) print(print_label) print(print_img)

import matplotlib.pyplot as plt from IPython.core.pylabtools import figsize #打印每类水果的第五张图像 def print_fruit(print_img, print_label, size) : plt.figure(figsize(size, size)) for i in range(len(print_img)): #图像输出格式为11行10列 plt.subplot(11, 10,(i+1)) #打印图像 plt.imshow(print_img[i]) #打印水果种类 plt.title(format(print_label[i])) plt.axis('off') plt.show() print_img, print_label = load_print_img(Test) #打印水果 print_fruit(print_img, print_label, 15)

import random #随机获取水果种类 def get_random_fruits(root, n_classes): #创建一个1到水果种类总数的list fruits = [] for i in range(len(os.listdir(root))): fruits.append(i) #随机获取n_classes个随机不重复的水果种类 random_fruits = random.sample(fruits, n_classes) return random_fruits
#获取随机抽取的10类水果的图像 def load(root, random_fruits): #存放图像 image_data = [] #存放标签 image_label = [] #存放图像标签码 num_label = [] #遍历水果类型 for i in range(len(random_fruits)): #第一层子目录(水果种类) child1 = os.listdir(root)[i] #第二层子目录(水果图像) child2 = os.listdir(os.path.join(root, child1)) #对第二层目录进行自然数排序,os.listder默认为str排序 child2 = natsorted(child2) #遍历水果图像 for j in range(len(child2)): #结合第一二层子目录 path = os.path.join(root, child1, child2[j]) #只读取'.jpg'文件(文件后缀是否为'.jpg') if(path.endswith('.jpg')): #把文件读取为图像存入image_data image_data.append(skimage.data.imread(path)) #储存第一层子目录文件名(即水果名) image_label.append(child1) #把第一层子目录文件名的下标作为水果类型的编码 num_label.append(i) #把水果类型编码转换为one_hot编码 num_label = keras.utils.to_categorical(num_label, len(random_fruits)) #print("图片数:{0}, 标签数:{1}".format(len(image_data), len(os.listdir(root))) #输出图片和标签数 return image_data, image_label, num_label
#裁剪图像 def crop(image_data): crop_data = [] for i in image_data: #把图像转换成32*32的格式 I_crop = skimage.transform.resize(i, (32, 32)) #把转换后的图像放入Icrop_data crop_data.append(I_crop) return crop_data
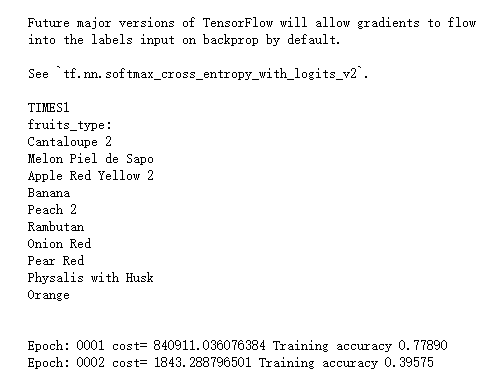
def fruits_type(random_fruits): print('fruits_type:') for i in random_fruits: print(os.listdir(Training)[i])
#定义水果种类数 n_classes = 10 #batch_size = 256 #定义块的大小 #batch_num = int(np.array(crop_img).shape[0]/batch_size) #计算取块的次数 #申请四维占位符,数据类型为float32 x = tf.placeholder(tf.float32,[None, 32, 32, 3]) #申请二维占位符,数据累型为float32 y = tf.placeholder(tf.float32,[None, n_classes]) #申请一维占位符,数据类型为float32 keep_prob = tf.placeholder(tf.float32) #epochs=2 #训练次数 #每个神经元保留的概率 dropout=0.75 #卷积核大小 k_size = 3 Weights = { "conv_w1" : tf.Variable(tf.random_normal([k_size, k_size, 3, 64]), name = 'conv_w1'), "conv_w2" : tf.Variable(tf.random_normal([k_size, k_size, 64, 128]), name = 'conv_w2'), #"conv_w3" : tf.Variable(tf.random_normal([k_size, k_size, 256, 512]), name = 'conv_w3'), "den_w1" : tf.Variable(tf.random_normal([int(32*32/4/4*128), 1024]), name = 'dev_w1'), "den_w2" : tf.Variable(tf.random_normal([1024, 512]), name = 'den_w2'), "den_w3" : tf.Variable(tf.random_normal([512, n_classes]), name = 'den_w3') } bias = { "conv_b1" : tf.Variable(tf.random_normal([64]), name = 'conv_b1'), "conv_b2" : tf.Variable(tf.random_normal([128]), name = 'conv_b2'), #"conv_b3" : tf.Variable(tf.random_normal([512]), name = 'conv_b3'), "den_b1" : tf.Variable(tf.random_normal([1024]), name = 'den_b1'), "den_b2" : tf.Variable(tf.random_normal([512]), name = 'den_b2'), "den_b3" : tf.Variable(tf.random_normal([n_classes]), name = 'den_b3') } def conv2d(x,W,b,stride=1): x=tf.nn.conv2d(x,W,strides=[1,stride,stride,1],padding="SAME") x=tf.nn.bias_add(x,b) return tf.nn.relu(x) def maxpool2d(x,stride=2): return tf.nn.max_pool(x,ksize=[1,stride,stride,1],strides=[1,stride,stride,1],padding="SAME")
def conv_net(inputs, W, b, dropout): ## convolution layer 1 ## 输入32*32*3的数据,输出16*16*64的数据 conv1 = conv2d(x, W["conv_w1"], b["conv_b1"]) conv1 = maxpool2d(conv1, 2) tf.summary.histogram('ConvLayer1/Weights', W["conv_w1"]) tf.summary.histogram('ConvLayer1/bias', b["conv_b1"]) ## convolution layer2 ## 输入16*16*64的数据,输出8*8*128的数据 conv2 = conv2d(conv1, W["conv_w2"], b["conv_b2"]) conv2 = maxpool2d(conv2, 2) tf.summary.histogram('ConvLayer2/Weights', W["conv_w2"]) tf.summary.histogram('ConvLayer2/bias', b["conv_b2"]) ## convolution layer3 #conv3 = conv2d(conv2, W["conv_w3"], b["conv_b3"]) #conv3 = maxpool2d(conv3, 2) #tf.summary.histogram('ConvLayer3/Weights', W["conv_w3"]) #tf.summary.histogram('ConvLayer3/bias', b["conv_b3"]) ## flatten ## 把数据拉伸为长度为8*8*128的一维数据 flatten = tf.reshape(conv2,[-1, W["den_w1"].get_shape().as_list()[0]]) ## dense layer1 ## 输入8192*1的数据,输出1024*1的数据 den1 = tf.add(tf.matmul(flatten, W["den_w1"]), b["den_b1"]) den1 = tf.nn.relu(den1) den1 = tf.nn.dropout(den1, dropout) tf.summary.histogram('DenLayer1/Weights', W["den_w1"]) tf.summary.histogram('DenLayer1/bias', b["den_b1"]) ## dense layer2 ## 1024*1的数据,输出512*1的数据 den2 = tf.add(tf.matmul(den1, W["den_w2"]), b["den_b2"]) den2 = tf.nn.relu(den2) den2 = tf.nn.dropout(den2, dropout) tf.summary.histogram('DenLayer2/Weights', W["den_w2"]) tf.summary.histogram('DenLayer2/bias', b["den_b2"]) ## out ## 512*1的数据,输出n_classes*1的数据 out = tf.add(tf.matmul(den2, W["den_w3"]), b["den_b3"]) tf.summary.histogram('DenLayer3/Weights', W["den_w3"]) tf.summary.histogram('DenLayer3/bias', b["den_b3"]) return out
pred=conv_net(x,Weights,bias,keep_prob) cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)) tf.summary.histogram('loss', cost) optimizer=tf.train.AdamOptimizer(0.01).minimize(cost) correct_pred=tf.equal(tf.argmax(pred,1),tf.argmax(y,1)) accuracy=tf.reduce_mean(tf.cast(correct_pred,tf.float32)) merged=tf.summary.merge_all() def train_and_test(train_x, train_y, test_x, test_y, epochs, batch_size, times = 1) : # 初始化全局变量 init=tf.global_variables_initializer() start_time = time.time() with tf.Session() as sess: sess.run(init) # 把需要可视化的参数写入可视化文件 writer=tf.summary.FileWriter('F:\data\fruits-360\tensorboard\Fruit_graph' + str(times), sess.graph) for i in range(epochs): batch_num = int(np.array(train_x).shape[0]/batch_size) sum_cost = 0 sum_acc = 0 for j in range(batch_num): batch_x = get_data(train_x, batch_size, j) batch_y = get_data(train_y, batch_size, j) sess.run(optimizer, feed_dict={x:batch_x,y:batch_y,keep_prob:0.75}) loss,acc = sess.run([cost,accuracy],feed_dict={x:batch_x,y:batch_y,keep_prob: 1.}) sum_cost += loss sum_acc += acc result=sess.run(merged,feed_dict={x:batch_x, y:batch_y, keep_prob:0.75}) writer.add_summary(result, i) arg_cost = sum_cost/batch_num arg_acc = sum_acc/batch_num print("Epoch:", '%04d' % (i+1),"cost=", "{:.9f}".format(arg_cost),"Training accuracy","{:.5f}".format(arg_acc)) end_time = time.time() print('Optimization Completed') print('Testing Accuracy:',sess.run(accuracy,feed_dict={x:test_x, y:test_y,keep_prob: 1})) print('Total processing time:',end_time - start_time) for i in range(10): random_fruits = get_random_fruits(Training, n_classes) img_data, img_label, num_label = load(Training, random_fruits) crop_img = crop(img_data) test_data, test_label, test_num_label = load(Test, random_fruits) crop_test = crop(test_data) print("TIMES"+str(i+1)) fruits_type(random_fruits) print(" ") train_and_test(crop_img, num_label, crop_test, test_num_label, 20, 26, (i+1)) print(" ")