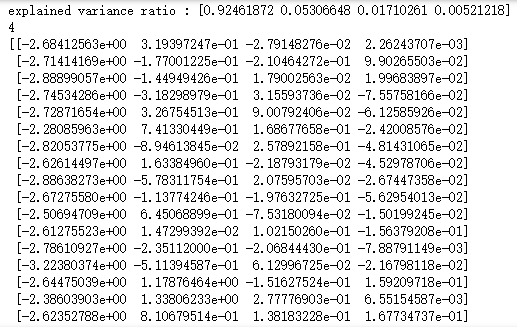
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,decomposition def load_data(): ''' 加载用于降维的数据 ''' # 使用 scikit-learn 自带的 iris 数据集 iris=datasets.load_iris() return iris.data,iris.target #超大规模数据集降维IncrementalPCA模型 def test_IncrementalPCA(*data): X,y=data # 使用默认的 n_components pca=decomposition.IncrementalPCA(n_components=None,batch_size=10) pca.partial_fit(X) aa = pca.transform(X) print('explained variance ratio : %s'% str(pca.explained_variance_ratio_)) print(pca.n_components_) print(aa) # 产生用于降维的数据集 X,y=load_data() # 调用 test_IncrementalPCA test_IncrementalPCA(X,y)