> pyppeteer 没有api手册,各种api的使用参考puppeteer手册 https://zhaoqize.github.io/puppeteer-api-zh_CN/
基本使用
尝试开始
以简单的方式开始
1 import asyncio 2 from pyppeteer import launch 3 4 async def main(url): 5 browser = await launch() 6 page = await browser.newPage() 7 res = await page.goto(url, options={'timeout': 30000}) 8 9 data = await page.content() 10 title = await page.title() 11 resp_cookies = await page.cookies() # cookie 12 resp_headers = res.headers # 响应头 13 resp_status = res.status # 响应状态 14 15 print(data) 16 print(title) 17 print(resp_headers) 18 print(resp_status) 19 20 21 if __name__ == '__main__': 22 url = "http://demo.aisec.cn/demo/aisec/" 23 asyncio.get_event_loop().run_until_complete(main(url))
launch选项
启动 Chromium 实例的方法 launch
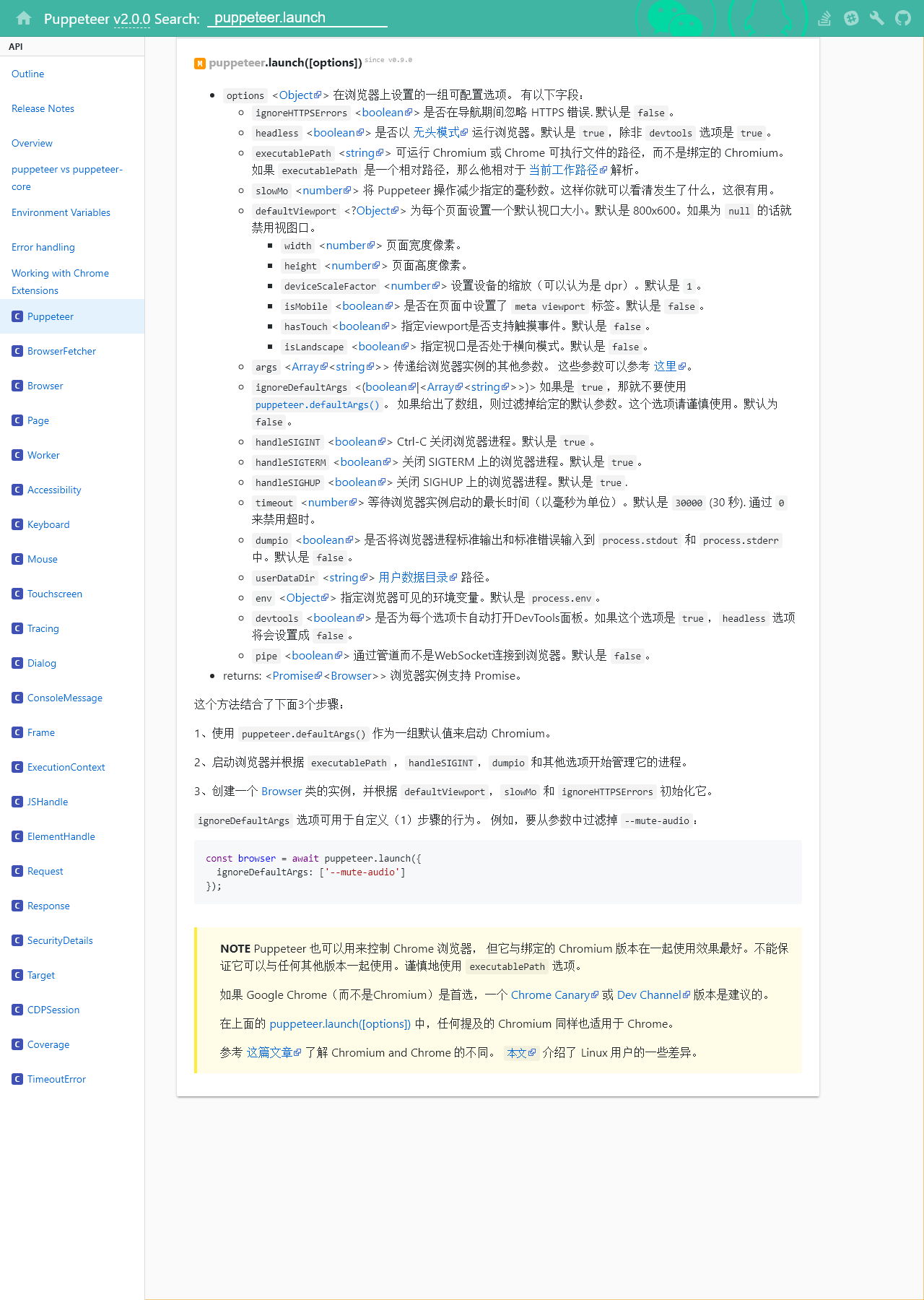
browser = await pyppeteer.launch({ 'headless': False, # 关闭无头模式 'devtools': True, # 控制界面的显示,用来调试 'executablePath': '你下载的Chromium.app/Contents/MacOS/Chromiu', 'args': [ '--disable-extensions', '--hide-scrollbars', '--disable-bundled-ppapi-flash', '--mute-audio', '--no-sandbox', # --no-sandbox 在 docker 里使用时需要加入的参数,不然会报错 '--disable-setuid-sandbox', '--disable-gpu', '--disable-xss-auditor', ], 'dumpio': True, # 解决浏览器多开卡死 })
截屏
1 async def main(url): 2 browser = await launch() 3 page = await browser.newPage() 4 await page.setViewport(viewport={'width': 1280, 'height': 1800}) 5 res = await page.goto(url, waitUntil=["networkidle0", "load", "domcontentloaded"],options={'timeout': 0}) 6 await page.screenshot({'path': 'example.png'}) 7 8 url = "https://zhaoqize.github.io/puppeteer-api-zh_CN/#?product=Puppeteer&version=v2.0.0&show=api-puppeteerlaunchoptions" 9 asyncio.get_event_loop().run_until_complete(main(url))
基本使用
pyppeteer的一些基本使用,包括网络请求,返回cookie、title、html、响应头、执行js、获取html元素等用法。
1 async def main(url): 2 browser = await launch() 3 page = await browser.newPage() 4 5 await page.setUserAgent('Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36') 6 7 # 是否启用JS,enabled设为False,则无渲染效果 8 await page.setJavaScriptEnabled(enabled=True) 9 10 # 注入 js 文件 11 CURDIR = Path(__file__).parent 12 JS_AJAX_HOOK_LIB = str(CURDIR / 'static' / 'ajaxhook.min.js') 13 await page.addScriptTag(path=JS_AJAX_HOOK_LIB) 14 15 res = await page.goto(url, waitUntil=["networkidle0", "load", "domcontentloaded"],options={'timeout': 0}) 16 17 # cookie 18 cookies = await page.cookies() 19 20 # 网站 title 21 title = await page.title() 22 23 # html 内容 24 contents = await page.content() 25 26 # 响应头 27 res_headers = res.headers 28 29 # 响应状态 30 res_status = res.status 31 32 # 等待 33 await asyncio.sleep(2) 34 35 # 滚动到页面底部 36 await page.evaluate('window.scrollBy(0, document.body.scrollHeight)') 37 38 # 在网页上执行js 脚本 39 dimensions = await page.evaluate(pageFunction='''() => { 40 return { 41 document.documentElement.clientWidth, // 页面宽度 42 height: document.documentElement.clientHeight, // 页面高度 43 deviceScaleFactor: window.devicePixelRatio, // 像素比 1.0000000149011612 44 } 45 }''', force_expr=False) # force_expr=False 执行的是函数 True 则执行表达式 46 47 """ 48 抓取内容 49 50 Page.querySelector() # 选择器 51 Page.querySelectorAll() 52 Page.xpath() # xpath 表达式 53 54 Page.J(), Page.JJ(), and Page.Jx() # 简写 55 """ 56 element = await page.querySelector(".feed-infinite-wrapper > ul>li") # 只抓取一个 57 58 # 获取所有文本内容 执行 js 59 content = await page.evaluate('(element) => element.textContent', element) 60 61 elements = await page.xpath('//div[@class="title-box"]/a') 62 63 elements = await page.querySelectorAll(".title-box a") 64 for item in elements: 65 print(await item.getProperty('textContent')) 66 # <pyppeteer.execution_context.JSHandle object at 0x000002220E7FE518> 67 68 # 获取文本 69 title_str = await (await item.getProperty('textContent')).jsonValue() 70 71 # 获取链接 72 title_link = await (await item.getProperty('href')).jsonValue() 73 74 75 # 键盘输入 76 await page.type('#identifierId', username) 77 78 # 点击下一步 79 await page.click('#identifierNext > content') 80 page.mouse # 模拟真实点击 81 82 83 await browser.close()
请求多个url
1 import asyncio 2 import pyppeteer 3 from collections import namedtuple 4 5 Response = namedtuple("rs", "title url html cookies headers history status") 6 7 8 async def get_html(url): 9 browser = await pyppeteer.launch(headless=True, args=['--no-sandbox']) 10 page = await browser.newPage() 11 res = await page.goto(url, options={'timeout': 30000}) 12 data = await page.content() 13 title = await page.title() 14 resp_cookies = await page.cookies() # cookie 15 resp_headers = res.headers # 响应头 16 resp_status = res.status # 响应状态 17 print(data) 18 print(title) 19 print(resp_headers) 20 print(resp_status) 21 return title 22 23 24 if __name__ == '__main__': 25 url_list = ["https://www.toutiao.com/", 26 "http://jandan.net/ooxx/page-8#comments", 27 "https://www.12306.cn/index/" 28 ] 29 task = [get_html(url) for url in url_list] 30 31 loop = asyncio.get_event_loop() 32 results = loop.run_until_complete(asyncio.gather(*task)) 33 for res in results: 34 print(res)
模拟输入
1 # 模拟输入 账号密码 {'delay': rand_int()} 为输入时间 2 await page.type('#TPL_username_1', "sadfasdfasdf") 3 await page.type('#TPL_password_1', "123456789", ) 4 5 await page.waitFor(1000) 6 await page.click("#J_SubmitStatic")
爬取京东商城
一个使用案例,出自别人的博客。
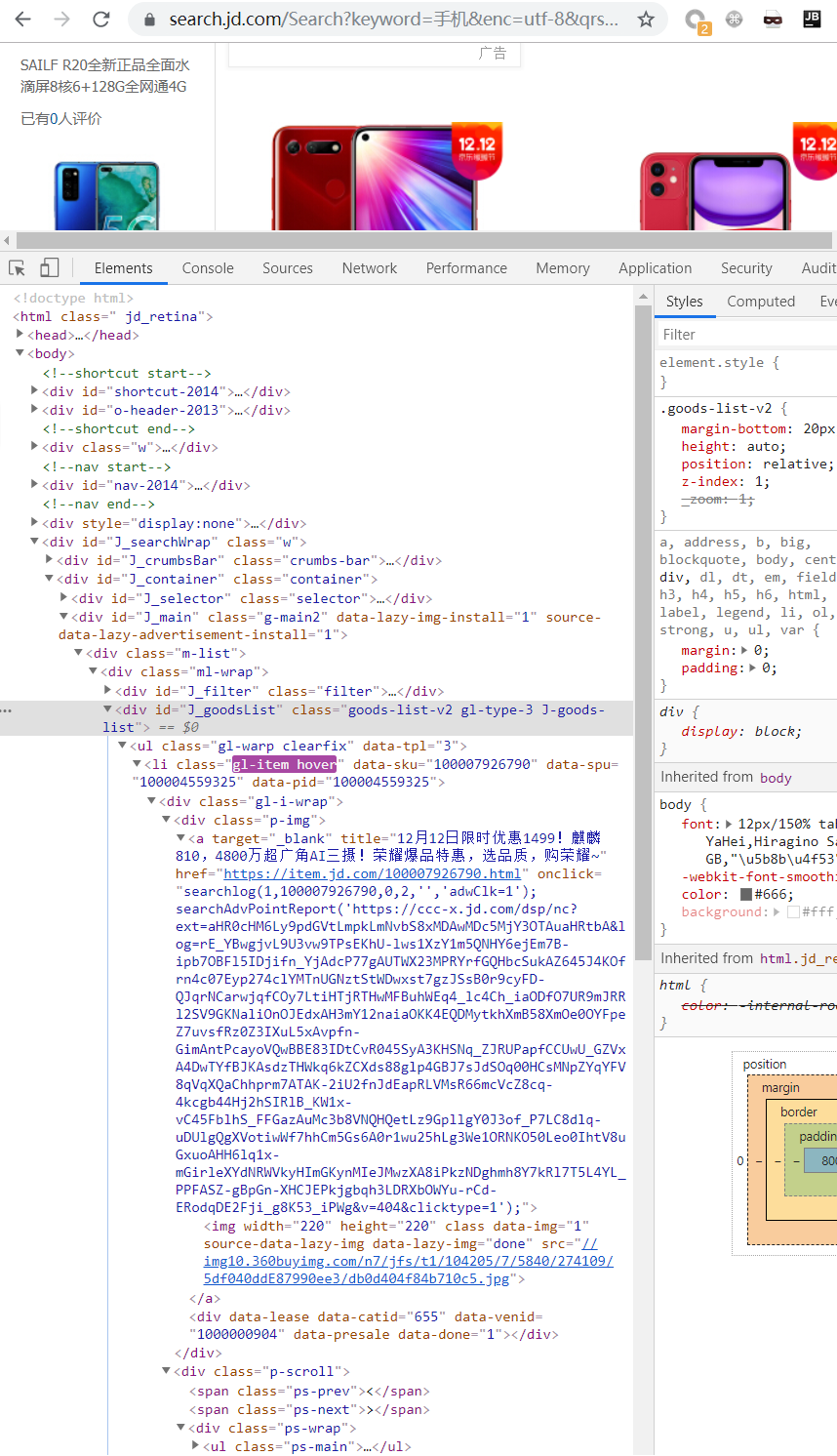
1 import requests 2 from bs4 import BeautifulSoup 3 from pyppeteer import launch 4 import asyncio 5 6 7 def screen_size(): 8 """使用tkinter获取屏幕大小""" 9 import tkinter 10 tk = tkinter.Tk() 11 width = tk.winfo_screenwidth() 12 height = tk.winfo_screenheight() 13 tk.quit() 14 return width, height 15 16 async def main(url): 17 browser = await launch({'args': ['--no-sandbox'], }) 18 page = await browser.newPage() 19 width, height = screen_size() 20 await page.setViewport(viewport={"width": width, "height": height}) 21 await page.setJavaScriptEnabled(enabled=True) 22 await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 Edge/16.16299') 23 await page.goto(url) 24 await page.evaluate('window.scrollBy(0, document.body.scrollHeight)') 25 26 await asyncio.sleep(1) 27 28 # content = await page.content() 29 li_list = await page.xpath('//*[@id="J_goodsList"]/ul/li') 30 31 # print(li_list) 32 item_list = [] 33 for li in li_list: 34 a = await li.xpath('.//div[@class="p-img"]/a') 35 detail_url = await (await a[0].getProperty("href")).jsonValue() 36 promo_words = await (await a[0].getProperty("title")).jsonValue() 37 a_ = await li.xpath('.//div[@class="p-commit"]/strong/a') 38 p_commit = await (await a_[0].getProperty("textContent")).jsonValue() 39 i = await li.xpath('./div/div[3]/strong/i') 40 price = await (await i[0].getProperty("textContent")).jsonValue() 41 em = await li.xpath('./div/div[4]/a/em') 42 title = await (await em[0].getProperty("textContent")).jsonValue() 43 item = { 44 "title": title, 45 "detail_url": detail_url, 46 "promo_words": promo_words, 47 'p_commit': p_commit, 48 'price': price 49 } 50 item_list.append(item) 51 # print(item) 52 # break 53 # print(content) 54 55 await page_close(browser) 56 return item_list 57 58 59 async def page_close(browser): 60 for _page in await browser.pages(): 61 await _page.close() 62 await browser.close() 63 64 65 msg = "手机" 66 url = "https://search.jd.com/Search?keyword={}&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq={}&cid2=653&cid3=655&page={}" 67 68 task_list = [] 69 for i in range(1, 6): 70 page = i * 2 - 1 71 url = url.format(msg, msg, page) 72 task_list.append(main(url)) 73 74 loop = asyncio.get_event_loop() 75 results = loop.run_until_complete(asyncio.gather(*task_list)) 76 # print(results, len(results)) 77 for i in results: 78 print(i, len(i)) 79 80 # soup = BeautifulSoup(content, 'lxml') 81 # div = soup.find('div', id='J_goodsList') 82 # for i, li in enumerate(div.find_all('li', class_='gl-item')): 83 # if li.select('.p-img a'): 84 # print(li.select('.p-img a')[0]['href'], i) 85 # print(li.select('.p-price i')[0].get_text(), i) 86 # print(li.select('.p-name em')[0].text, i) 87 # else: 88 # print("#" * 200) 89 # print(li)
xss验证
1 import asyncio 2 from pyppeteer import launch 3 payload = '<script>xianzhi(3.1415926535)</script>' 4 url = "http://192.168.81.132/vuls/sqli/?id=1'>{payload}".format(payload=payload) 5 def xss_auditor(url, message): 6 if message == 3.1415926535: 7 print('xss_auditor_found:', payload) 8 print(url) 9 10 async def main(): 11 browser = await launch(headless=False, args=['--disable-xss-auditor']) 12 page = await browser.newPage() 13 await page.exposeFunction( 14 'xianzhi', lambda message: xss_auditor(url, message) 15 ) 16 await page.goto(url) 17 await page.close() 18 19 asyncio.get_event_loop().run_until_complete(main())
启发式爬虫
启发式爬虫要实现捕获ajax请求、遍历表单、触发事件。
捕获 ajax 链接
启用请求拦截器await page.setRequestInterception(True),会激活 request.abort,request.continue 和 request.respond 方法,每个请求都将停止,这样可以拦截ajax请求。
page.on('request', get_ajax)遇到request请求时触发。
1 import asyncio 2 from pyppeteer import launch 3 4 async def get_ajax(req): 5 6 res = {"method":req.method,"url":req.url,"data": "" if req.postData == None else req.postData} 7 print(res) 8 await req.continue_() 9 10 async def main(url): 11 browser = await launch() 12 page = await browser.newPage() 13 14 await page.setRequestInterception(True) 15 page.on('request', get_ajax) 16 17 res = await page.goto(url)

绕过webdriver检测
1 async def page_evaluate(self, page): 2 '''window.navigator.webdriver=false''' 3 4 await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) }''') # 以下为插入中间js,将淘宝会为了检测浏览器而调用的js修改其结果。 5 await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''') 6 await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''') 7 await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''') 8 9 async def main(self): 10 browser = await launch() 11 page = await browser.newPage() 12 13 await self.page_evaluate(page)
处理弹框
更多处理方法可以在puppeteer手册中查找
1 async def dialog_control(self, dialog): 2 await dialog.accept() 3 4 async def main(self): 5 browser = await launch() 6 page = await browser.newPage() 7 page.on('dialog', self.dialog_control)
用匿名函数表达
1 page.on('dialog', lambda dialog: dialog.accept())
过滤掉img、css等请求
1 async def goto(page, url): 2 '''请求加载是否完成,无网都需要处理 3 ''' 4 while True: 5 try: 6 await page.goto(url, { 7 'timeout': 0, 8 'waitUntil': 'networkidle0' 9 }) 10 break 11 except (pyppeteer.errors.NetworkError, 12 pyppeteer.errors.PageError) as ex: 13 # 无网络 'net::ERR_INTERNET_DISCONNECTED','net::ERR_TUNNEL_CONNECTION_FAILED' 14 if 'net::' in str(ex): 15 await asyncio.sleep(10) 16 else: 17 raise 18 19 async def request_check(self, req): 20 '''filter requests 21 Disable image loading 22 ''' 23 if req.resourceType in ["image", "media", "eventsource", "websocket", "stylesheet", "font"]: 24 await req.abort() 25 elif "logout" in req.url or "delete" in req.url or "signout" in req.url: 26 await req.abort() 27 else: 28 await req.continue_() 29 30 async def main(self): 31 browser = await launch() 32 page = await browser.newPage() 33 await page.setRequestInterception(True) 34 page.on('request', self.request_check)
获取表单
通过运行js获取表单,先在浏览器中测试通过后再转入脚本运行。
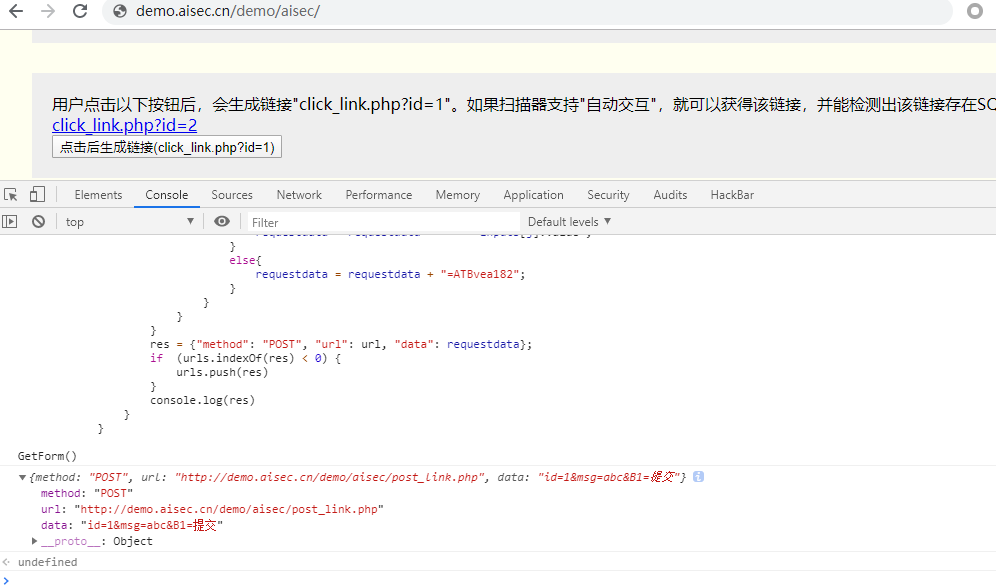
1 async def get_urls(page): 2 res = await page.evaluate('''() => { 3 var urls = []; 4 //get form 5 function GetForm() { 6 var f = document.forms; 7 for (var i = 0; i < f.length; i++) { 8 url = f[i].action; 9 //input 10 var inputs = f[i].getElementsByTagName('*'); 11 var requestdata = ""; 12 var len = inputs.length; 13 14 for (var j = 0; j < len; j++) { 15 if(inputs[j].hasAttributes("*")== true){ 16 if (j < len - 1) { 17 if(inputs[j].hasAttributes("name") && inputs[j].name !=undefined && inputs[j].name !=""){ 18 requestdata = requestdata + inputs[j].name 19 } 20 else{ 21 continue 22 } 23 if(inputs[j].hasAttributes("value") && inputs[j].value !="" && inputs[j].value !=undefined){ 24 requestdata = requestdata + "=" + inputs[j].value + "&"; 25 } 26 else{ 27 requestdata = requestdata + "=123123&"; 28 } 29 } 30 if (j == len - 1) { 31 if(inputs[j].hasAttributes("name") && inputs[j].name !=undefined && inputs[j].name !=""){ 32 requestdata = requestdata + inputs[j].name 33 } 34 else{ 35 continue 36 } 37 if(inputs[j].hasAttributes("value") && inputs[j].value !="" && inputs[j].value !=undefined){ 38 requestdata = requestdata + "=" + inputs[j].value ; 39 } 40 else{ 41 requestdata = requestdata + "=123123"; 42 } 43 } 44 } 45 } 46 res = {"method": "POST", "url": url, "data": requestdata}; 47 if (urls.indexOf(res) < 0) { 48 urls.push(res) 49 } 50 } 51 } 52 GetForm() 53 return urls; 54 }''') 55 return res
获取 href
还是现在浏览器中测试成功后再加入脚本
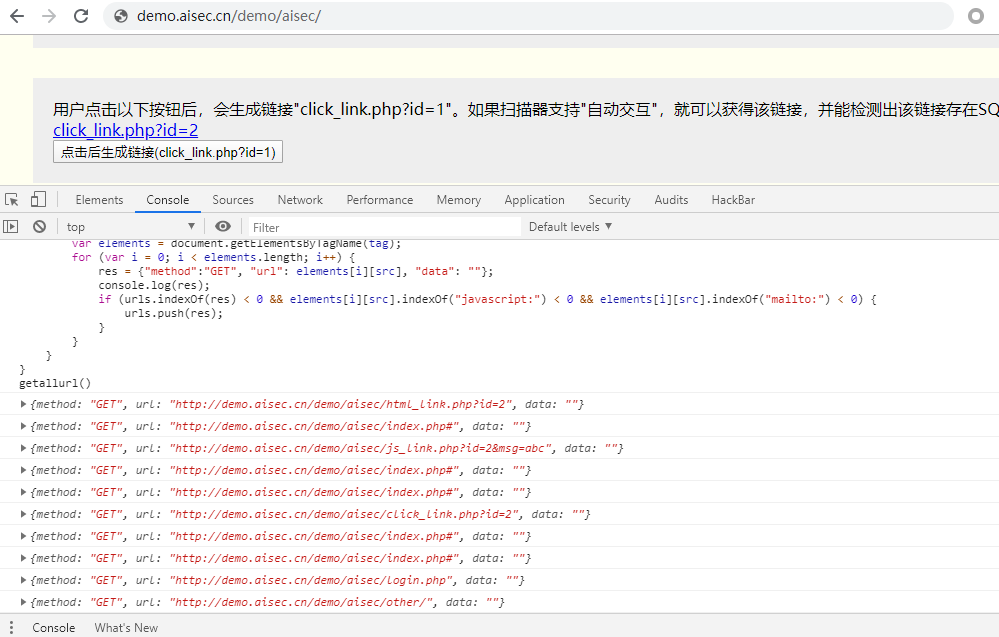
1 () => { 2 var urls = []; 3 //get href 4 function getallurl() { 5 tag_dict = {'a': 'href','link': 'href','area': 'href','img': 'src','embed': 'src','video': 'src','audio': 'src'} 6 for(var tag in tag_dict){ 7 var src = tag_dict[tag]; 8 var elements = document.getElementsByTagName(tag); 9 for (var i = 0; i < elements.length; i++) { 10 res = {"method":"GET", "url": elements[i][src], "data": ""}; 11 if (urls.indexOf(res) < 0 && elements[i][src].indexOf("javascript:") < 0 && elements[i][src].indexOf("mailto:") < 0) { 12 urls.push(res); 13 } 14 } 15 } 16 } 17 18 getallurl(); 19 return urls; 20 }
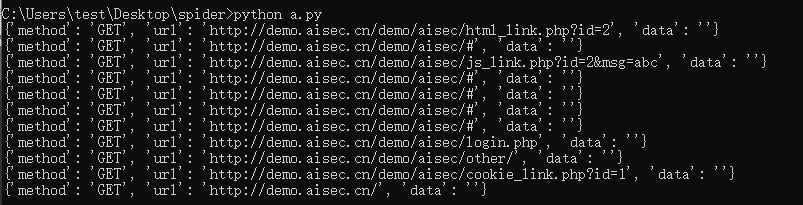
更多js调用参考https://github.com/wilson9x1/crawler_phantomjs
捕获onevent
1 function getonevents() { 2 // eval all on event 3 var nodes = document.all; 4 for(var i=0;i<nodes.length;i++){ 5 var attrs = nodes[i].attributes; 6 for(var j=0;j<attrs.length;j++){ 7 attr_name = attrs[j].nodeName; 8 attr_value = attrs[j].nodeValue.replace(/return.*;/g,''); 9 if(attr_name.substr(0,2) == "on"){ 10 if (onevents.indexOf(attr_value) < 0) { 11 onevents.push(attr_value); 12 } 13 } 14 if(attr_name == "href"){ 15 javascript_code = attr_value.match("javascript:(.*)") 16 if (javascript_code) { 17 if (onevents.indexOf(attr_value) < 0) { 18 onevents.push(attr_value); 19 } 20 } 21 } 22 } 23 } 24 }
最终运行效果:

1 #!/usr/bin/env python3 2 import asyncio 3 import hashlib 4 from pyppeteer import launch 5 from collections import OrderedDict 6 7 ''' 8 pyppeteer/connection.py 9 self._ws = websockets.client.connect( 10 # self._url, max_size=None, loop=self._loop) 11 self._url, max_size=None, loop=self._loop, ping_interval=None, ping_timeout=None) 12 ''' 13 14 class DynamicCrawler(object): 15 ''' Dynamic Crawler 16 crawler ajax onclick tags 17 ''' 18 19 def __init__(self, target): 20 super(DynamicCrawler, self).__init__() 21 self.urls = [] 22 self.target = target 23 self.timeout = 50000 24 self.browser_setting = { 25 'headless': False, 26 'devtools': True, # Console 27 # 'executablePath': 'Chromium.app/Contents/MacOS/Chromiu', 28 'ignoreHTTPSErrors': True, 29 # 'slowMo':100, 30 'args': [ 31 '--disable-extensions', 32 '--hide-scrollbars', 33 '--disable-bundled-ppapi-flash', 34 '--mute-audio', 35 '--no-sandbox', 36 '--disable-setuid-sandbox', 37 '--disable-gpu', 38 '--disable-xss-auditor', 39 ], 40 'dumpio': True, 41 } 42 43 44 async def request_check(self, req): 45 '''filter requests 46 Disable image loading 47 ''' 48 49 res = {"method":req.method,"url":req.url,"data": "" if req.postData == None else req.postData} 50 res.update({"hash":self.get_hash(str(res))}) 51 self.urls.append(res) 52 if req.resourceType in ["image", "media", "eventsource", "websocket", "stylesheet", "font"]: 53 # if req.resourceType in ["image", "media", "websocket"]: 54 await req.abort() 55 elif "logout" in req.url or "delete" in req.url or "signout" in req.url: 56 await req.abort() 57 else: 58 await req.continue_() 59 60 61 async def frame_nav(self, frameTo): 62 res = {"method":"Frame","url":frameTo.url} 63 res.update({"hash":self.get_hash(str(res))}) 64 self.urls.append(res) 65 66 67 async def page_evaluate(self, page): 68 '''window.navigator.webdriver=false''' 69 70 await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => undefined } }) }''') # 以下为插入中间js,将淘宝会为了检测浏览器而调用的js修改其结果。 71 await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''') 72 await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''') 73 await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''') 74 75 76 async def get_urls(self, page): 77 res = await page.evaluate('''() => { 78 var urls = []; 79 var onevents = []; 80 var onclickstrs = []; 81 //get form 82 function GetForm() { 83 var f = document.forms; 84 for (var i = 0; i < f.length; i++) { 85 url = f[i].action; 86 //input 87 var inputs = f[i].getElementsByTagName('*'); 88 var requestdata = ""; 89 var len = inputs.length; 90 91 for (var j = 0; j < len; j++) { 92 if(inputs[j].hasAttributes("*")== true){ 93 if (j < len - 1) { 94 if(inputs[j].hasAttributes("name") && inputs[j].name !=undefined && inputs[j].name !=""){ 95 requestdata = requestdata + inputs[j].name 96 } 97 else{ 98 continue 99 } 100 if(inputs[j].hasAttributes("value") && inputs[j].value !="" && inputs[j].value !=undefined){ 101 requestdata = requestdata + "=" + inputs[j].value + "&"; 102 } 103 else{ 104 requestdata = requestdata + "=ATBvea182&"; 105 } 106 } 107 if (j == len - 1) { 108 if(inputs[j].hasAttributes("name") && inputs[j].name !=undefined && inputs[j].name !=""){ 109 requestdata = requestdata + inputs[j].name 110 } 111 else{ 112 continue 113 } 114 if(inputs[j].hasAttributes("value") && inputs[j].value !="" && inputs[j].value !=undefined){ 115 requestdata = requestdata + "=" + inputs[j].value ; 116 } 117 else{ 118 requestdata = requestdata + "=ATBvea182"; 119 } 120 } 121 } 122 } 123 res = {"method": "POST", "url": url, "data": requestdata}; 124 if (urls.indexOf(res) < 0) { 125 urls.push(res) 126 } 127 } 128 } 129 130 // get all href 131 function getallurl() { 132 GetForm(); 133 tag_dict = {'a': 'href','link': 'href','area': 'href','img': 'src','embed': 'src','video': 'src','audio': 'src'} 134 for(var tag in tag_dict){ 135 var src = tag_dict[tag]; 136 var elements = document.getElementsByTagName(tag); 137 for (var i = 0; i < elements.length; i++) { 138 res = {"method":"GET", "url": elements[i][src], "data": ""}; 139 if (urls.indexOf(res) < 0 && elements[i][src].indexOf("javascript:") < 0 && elements[i][src].indexOf("mailto:") < 0) { 140 urls.push(res); 141 } 142 } 143 } 144 } 145 146 //get onevent 147 function getonevents() { 148 // eval all on event 149 var nodes = document.all; 150 for(var i=0;i<nodes.length;i++){ 151 var attrs = nodes[i].attributes; 152 for(var j=0;j<attrs.length;j++){ 153 attr_name = attrs[j].nodeName; 154 attr_value = attrs[j].nodeValue.replace(/return.*/g,'').replace(/return.*;/g,''); 155 if(attr_name.substr(0,2) == "on"){ 156 if (onevents.indexOf(attr_value) < 0) { 157 onevents.push(attr_value); 158 } 159 } 160 if(attr_name == "href"){ 161 javascript_code = attr_value.match("javascript:(.*)") 162 if (javascript_code) { 163 if (onevents.indexOf(attr_value) < 0) { 164 onevents.push(attr_value); 165 } 166 } 167 } 168 } 169 } 170 } 171 172 function doloop(i) { 173 getallurl(); 174 getonevents(); 175 if (onevents.length ==0) { 176 return; 177 } 178 if (i == (onevents.length - 1)) { 179 try { 180 eval(onevents[i]); 181 }catch(err) { 182 return; 183 } 184 getallurl(); 185 } 186 else { 187 try { 188 eval(onevents[i]); 189 i = i + 1; //1 190 doloop(i); 191 }catch(err) { 192 i = i + 1; //1 193 doloop(i); 194 } 195 } 196 } 197 198 function main() { 199 doloop(0); 200 } 201 main(); 202 return urls; 203 }''') 204 return res 205 206 207 def duplicate(self, datas): 208 ''' Data deduplication 209 ''' 210 b = OrderedDict() 211 for item in datas: 212 b.setdefault(item['hash'],{**item,}) 213 b = list(b.values()) 214 return b 215 216 217 def get_hash(self, content): 218 md = hashlib.md5() 219 md.update(content.encode('utf-8')) 220 return md.hexdigest()[:5] 221 222 223 async def main(self): 224 browser = await launch(self.browser_setting) 225 # browser = await launch() 226 page = await browser.newPage() 227 228 await self.page_evaluate(page) 229 230 await page.setUserAgent('Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36') 231 232 await page.setJavaScriptEnabled(True) 233 # 禁止加载图片接口 234 await page.setRequestInterception(True) 235 page.on('request', self.request_check) 236 237 page.on('framenavigated', self.frame_nav) 238 # 处理弹框 239 page.on('dialog', lambda dialog: dialog.accept()) 240 241 req = await page.goto(self.target, waitUntil=["networkidle0", "load", "domcontentloaded"], options={'timeout': self.timeout}) 242 cookies = await page.cookies() 243 244 title = await page.title() 245 # html 内容 246 contents = await page.content() 247 248 # 响应头 249 res_headers = req.headers 250 251 # 响应状态 252 res_status = req.status 253 254 getUrls = await self.get_urls(page) 255 for res in getUrls: 256 res.update({"hash":self.get_hash(str(res))}) 257 self.urls.append(res) 258 259 print (title) 260 print (cookies) 261 # print (res_headers) 262 263 for i in self.duplicate(self.urls): 264 print(i) 265 266 await page.close() 267 await browser.close() 268 269 270 def run(self): 271 asyncio.get_event_loop().run_until_complete(self.main()) 272 273 274 275 # a = DynamicCrawler("http://demo.aisec.cn/demo/aisec/") 276 a = DynamicCrawler("http://192.168.81.132/vuls/config/setup.php") 277 278 a.run()
在docker里使用
在 window10 里开发很流程,部署到 windows server 上,可能由于配置比较差或其他原因,网站渲染很慢。
可以放在容器里,效果明显。注意点是上面提到了的关闭沙盒模式,需要下一些浏览器的依赖,还有就是最好先把浏览器下好,做到镜像里,这样
就不会在容器里一个一个下了。
FROM python:slim WORKDIR /usr/src/app RUN apt-get update && apt-get install -y gconf-service libasound2 libatk1.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget RUN apt-get install -y vim COPY requirements.txt ./ RUN pip install --no-cache-dir -r requirements.txt RUN python -c "import pyppeteer;pyppeteer.chromium_downloader.download_chromium();" COPY . . VOLUME /data
References
[Puppeteer api手册] (https://zhaoqize.github.io/puppeteer-api-zh_CN/)
[Pyppeteer 使用笔记] (https://www.cnblogs.com/zhang-zi-yi/p/10820813.html)
[pyppeteer使用总结] (https://www.dust8.com/2018/06/03/pyppeteer使用总结/)
[pyppeteer最为核心类Page的接口方法(下)] (https://zhuanlan.zhihu.com/p/64170269)
[WEB2.0启发式爬虫实战_猪猪侠] (https://github.com/ring04h/papers/blob/master/WEB2.0启发式爬虫实战-猪猪侠-20180616.pdf)
[phantomjs爬虫] (https://github.com/wilson9x1/crawler_phantomjs)
[基于PhantomJS的动态爬虫引擎] (http://byd.dropsec.xyz/2019/05/21/基于PhantomJS的动态爬虫引擎/)
[漏扫动态爬虫实践] (https://0kee.360.cn/blog/漏扫动态爬虫实践/)
[启发式爬虫] (https://www.dazhuanlan.com/2019/11/15/5dcdb39c33fc8/)
[AISec漏洞扫描器测试平台] (http://demo.aisec.cn/demo/aisec/)