源码:https://github.com/tripleDemo/mybatis.github.io
API:http://www.mybatis.org/mybatis-3/zh/index.html
MyBatis简介
MyBatis 本是apache的一个开源项目iBatis, 也就是淘宝使用的持久层框架。2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。
MyBatis是支持普通SQL查询,存储过程和高级映射的持久层框架,严格上说应该是一个SQL映射框架。几乎所有的JDBC代码和参数的手工设置以及结果集的处理都可以交给MyBatis完成。而这只需要简单的使用XML或注释配置就可以完成。和Hibernate相比更简单、更底层、性能更优异,因此更深入人心,更受企业的青睐。
为什么要使用MyBatis?
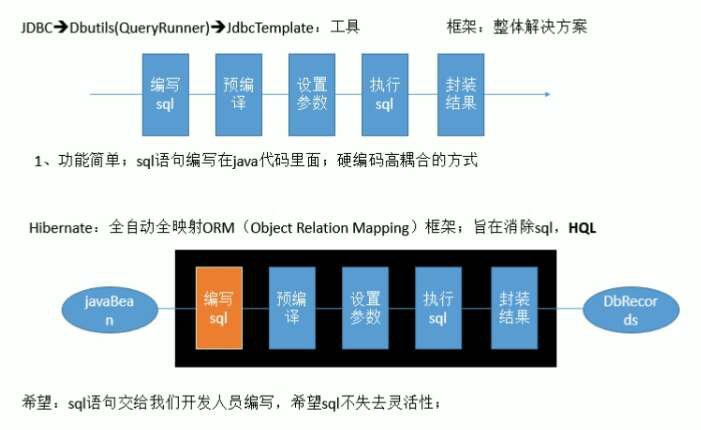
1,MyBatis是一个半自动化的持久化层框架。
2,JDBC
-- SQL夹在Java代码块里,耦合度高导致硬编码内伤
-- 维护不易且实际开发需求中sql是有变化,频繁修改的情况多见
3,Hibernate和JPA
--长难复杂SQL,对于Hibernate而言处理也不容易
--内部自动生产的SQL,不容易做特殊优化
--基于全映射的全自动框架,大量字段的POJO进行部分映射时比较困难,导致数据库性能下降
4,对开发人员而言,核心sql还是需要自己优化
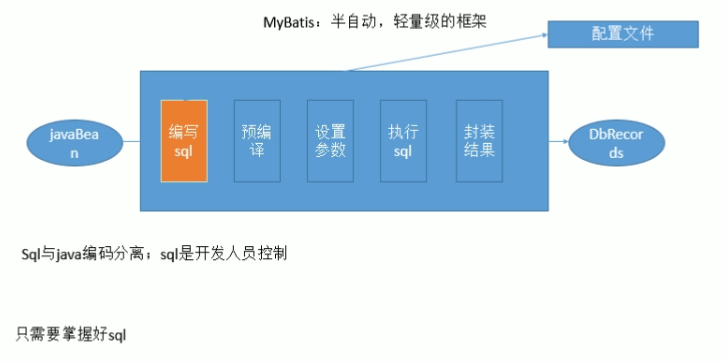
5,sql和java编码分开,功能边界清晰,一个专注业务,一个专注数据
ORM思想
对象关系映射(Object Relational Mapping,简称ORM):
是一种为了解决面向对象与关系数据库存在的互不匹配的问题的技术。简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将Java程序中的对象自动持久化到关系数据库中。
目前流行的ORM框架:
- JPA : 本身是一种ORM规范,不是ORM框架,由各大ORM框架提供实现。
- Hibernate : 之前最流行的ORM框架,设计灵巧,性能优秀,文档丰富。
- MyBatis目前最受欢迎的持久层解决方案。
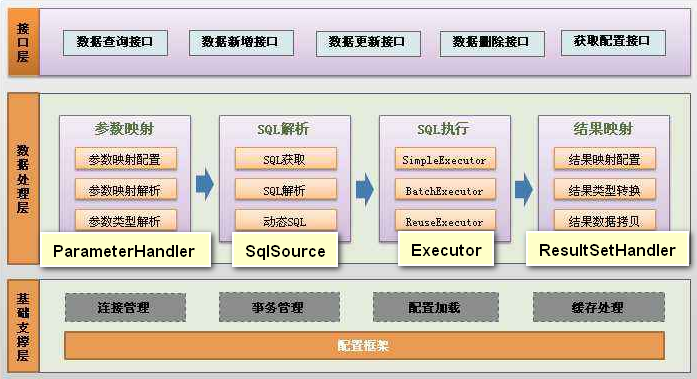
MyBatis架构图
MyBatis原理图
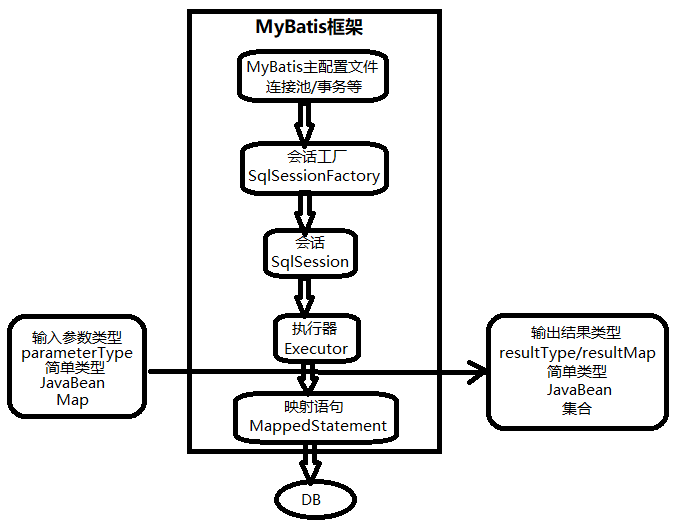
SqlSessionFactoryBuilder:根据配置信息,来创建SqlSessionFactory对象。
SqlSessionFactory:会话工厂,好比是DataSource对象,目的:创建SqlSession对象的。
SqlSession:会话,不是HttpSession。好比是Connection对象,该接口中提供了增删改查的方法。和Connection一样,是线程不安全的,每次使用都应该开启一个新的SqlSession对象,不能作为成员变量。用完之后,必须正常关闭资源。
Connection conn = DataSource对象.geiConnection();
SqlSession session = factory.openSession();
MyBatis的配置文件
一、MyBatis全局配置文件/主配置文件。
起名:不固定,但是一般起名要见名知意,---> mybatis-config.xml
路径:classpath的根路径
参数:mybatis文档的----XML配置这一个章节。
内容:
- 全局的配置信息
- 属性配置信息
- 插件配置信息
- 配置环境信息(连接池+事务)
- 关联映射文件
二、MyBatis映射文件/Mapper文件。
起名:不固定,但是一般起名要见名知意,--->XxxMapper.xml,是哪一个对象的映射文件,如EmployeeMapper.xml
路径:Mapper文件应该放到Mapper接口的路径,先姑且放在domain的位置(临时)
参数:mybatis文档的----XML映射文件这一个章节。
内容:
- 编写增删改查的SQL,把SQL存放到insert|update|delete|select元素中去。
- 结果集映射:解决表中的列和对象中属性不匹配的问题。
- 缓存配置。
日志
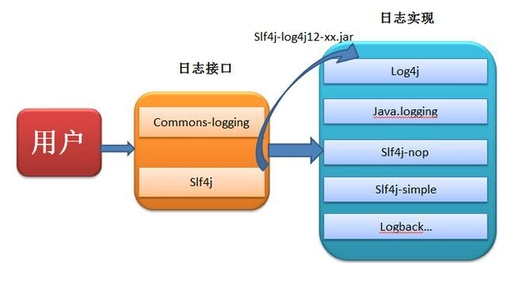
日志江湖
JDK-Logging:JDK1.4版本以后开始提供的一个自带的日志库实現,太简单,不支持占位符显示,拓展性差,使用很少。
Commons-logging: Apache提供的日志规范,需要用户可以选择第三方的日志组件作为具体实现,本身会通过动态查找的机制找出真正日志的实现库。
Log4j: Apache下功能非常丰富的日志库实现,功能强大,可以把日志输出到控制台、文件中,是出現比较早且最受欢迎日志组件。并且Log4问以允许自定义日志格式和日志等级,帮助开发人员全方位的掌控日志信息。
Log4j2:是Log4j的升级,基本上把Log4版本的核心全部重构,而且基于Log4j做了很多优化和升级。
SLF4j:好比是 Commons-logging是日志门面,本身并无日志的实現,制定了日志的规范,使用时得拷贝整合包。
这里有个小故事,当年 Apache说服Log4j以及其他的日志框架按照 Commons-Logging的标准来编写,但是由于Commons- Logging的类加载有点问题,实现起来不友好。因此Lg4j的作者就创作了SLF4j,也因就与 Commons-Logging二分天下。
Logback:由Lo94j创始人设计的另一个开源日志组件,也是作为Log4的替代者出现的
速度和效率都比LoG4]高,而且官方是建议和SLF4j一起使用, Logback、sf4j、Log4j都是出自罔一个人,所以默认对SLF4〕无缝结合。
日志框架
为什么要用日志?
- 比起System.out.println,日志框架可以把日志的输出和代码分离;
- 日志框架可以方便的定义日志的输出环境,控制台,文件,数据库;
- 日志框架可以方便的定义日志的输出格式和输出级别;
日志级别
ERROR > WARN > INFO > DEBUG > TRACE
(如果设置级别为INFO,则优先级高于等于INFO级别如INFO,WARN,ERROR的日志信息将可以被输出,小于该级别的如DEBUG和TRACE将不会被输出。)
总结:日志级别越低,输出的日志越详细
OGNL表达式
OGNL是Object-Graph Navigation Language的缩写,对象-图形导航语言。可以存取对象的属性和调用对象的方法,通过OGNL的表达式迭代出整个对象的结构图。
OGNL语法:#{ }
如果当前上下文对象是JavaBean对象,#{属性名称}
如果当前上下文对象是Map对象,#{key}。
如果当前上下文对象是简单类型对象(基本类型+String),直接取出参数值,而和花括号中的名称没关系。
MyBatis的#和$
使用#:
Preparing: select id,username,password from client where username = ? and password = ?
Parameters: tom(String), 1111(String)
使用$:
Preparing: select id,username,password from client where username = tom and password = 1111
Parameters:
#和$符号的异同:
相同:都可以通过#和$来获取对象中的信息。
不同:
使用#出传递的参数会先转换成占位符?,再通过设置占位符参数的方式来设置值(通通会给值使用单引号引起来)。
使用$传递的参数,直接把解析出来的数据作为SQL语句的一部分。
推论:
#:好比使用的PrepareStatement,不会导致SQL注入问题,相比比较安全。
$:好比使用的Statement,可能会导致SQL注入问题,相对不安全。
如何选择:
- 如果需要设置占位符参数的地方,全部使用#,也就是SQL之后可以使用?的情况。
- 如果我们写的内容应该作为SQL的一部分,此时应该使用$。比如要排序,分组查询。
动态SQL
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似。(具体看文档)
where、set、trim
where元素:判断查询条件是否有where关键字,如果没有,则在第一个查询条件之前插入一个where。如果发现查询条件以and或者or开头,也会把第一个查询条件钱的and/or替换成where。
set元素和where类似,根据set中的sql动态地去掉最后的一个逗号。并在最前面加上一个set关键字,set元素没有内容,自动忽略set语句。
trim是更为强大的格式化SQL的标签:
<trim prefix=”” prefixOverrides=”” suffix=”” suffixOverrides=””>
<!-- trim包含的动态的SQL -->
</trim>
trim元嚢代表对包含的内容的格式化方式:
前提:如果trim元素包含内容返回了一个字符串:
prefix-在这个字符串之前插入prefx屠性值。
prefixOverrides-井且字符串的内容以prefixOverrides中的内容开头(可以包含管道符号)那么使用prefix属性值替換内容的开头。
suffix-在这个字符串之后插入suffix属性值。
suffixOverrides-并且字符串的内容以suffixOverrides中的内容結尾(可以包含管道符号),那么使用suffix属性値替換内容的结尾。
使用where等价于:
<trim preffix= ”where” prefixOverrides"and | or"></trim>
使用set等价于:
<trim prefix=”set” suffixOverrides=”,”></trim>
foreach
<delete id="batchDelete">
delete from employee where id in
<!--foreach元素:
collection属性:表示对哪一个集合或数组做迭代
如果参数是数组类型,此时Map的key为array,
如果参数是List类型,此时Map的key为list,
可以在参数上使用Param注解,规定死Map中key是什么。
open属性:在迭代集合之前,拼接什么符号。
close属性:在迭代集合之后,拼接什么符号。
separator属性:在迭代元素时,每一个元素之间使用什么符号分割开来。
item属性:被迭代的每一个元素的变量
index属性:迭代的索引
-->
<foreach collection="ids" open="(" close=")" separator="," item="id">
#{id}
</foreach>
</delete>
<insert id="batchSave">
insert into employee (name,sn,salary) values
<foreach collection="emps" separator="," item="e">
(#{e.name},#{e.sn},#{e.salary})
</foreach>
</insert>
对象关系设计
面向对象设计思想,是一种非常符合人们对现实的思维方式,做开发的时候,会创建很多类,同时也会创建出很多对象。需要对象之间的协作,对象之间的关系也就产生了。
泛化关系(generalization):
其实就是继承关系,比如类和类之间、接口和接口之间,使用extends表示。
在UML中,继承通常是使用空心三角+实线来表示。
实现关系(realization):
其实就是实现关系,存在于类和接口之间,使用implements表示。
在UML中,实现关系通常是使用空心三角+虚线来表示。
依赖关系(dependent):
表示一个A类依赖于另一个B类的定义,如果A对象离开了B对象,A对象就不能正常编译,则A对象依赖B对象(A类中使用到了B对象)。
在UML中,依赖通常是使用虚线箭头表示。
关联关系(association):
A对象依赖B对象,并且把B作为A的一个成员变里,则A和B存在关联关系。
在UML中依赖通常使用实线箭头表示。
按照多重性分:
1) .一对一:一个A对象属于一个B对象,一个B对象属于一个A对象。
2) .一对多:一个A对象包含多个B对象,
3) .多对一:多个A对象尾于一个B对象.并且每个A对象只能属于一个B对象。
4) .多对多:一个A对象属于多个B对象,一个B对象属于多个A对象。
按照导航性分:如果通过A对象中的某一个属性可以访问到B对象 ,则说A可以导航到B。
1).单向:只能从A通过属性导航到B , B不能导航到A,
2).双向A可以通过屬性导航到B , B也可以通过屬性导航到A。
判断方法:
1,判断都是从对象的实例上面来看的。
2,判断关系必须确定对属性,
3,判断关系必须确定具体需求。
聚合关系(aggregation):
是一种”弱拥有”关系,表示为has-a,表示整体和个体的关系,整体和个体之间可以相互独立存在,一定是有两个模块来分别管理整体和个体,如果A和B是聚合关系,它们并不是一个独立的整体,A和B的生命周期可以是不同的,通常B也会是作为A的成员变量存在。
在UML中,聚合通常是使用空心菱形+实线箭头来表示。
组合关系(composition):
是一种强聚合关系,是一种”强拥有”关系,表示contains-a。整体和个体不能独立存在,一定是在一个模块中间同时管理整体和个体,生命周期必须相同级联。
级联(cascade):把主对象的操作遍历的在每一个对象上面执行相同的操作。
在UML中,组合通常是使用实心菱形+实线箭头来表示。
对象之间的关系设计
对于继承、实现这两种关系比较简单,他们体现的是一种类与类、或者类与接口间的纵向关系。
其他的四者关系则体现的是类与类。或者类与接口间的引用、横向关系,这几种关系都是语义级别的,所以从代码层面并不能完全区分各种关系。
从后几种关系所表现的强弱程度来看,依次为:组合>聚合>关联>依赖。
在面向对象的设计过程中,能采取强度较大的关系,决不能采取强度小的关系。
N+1问题:
假如每一个员工的部门ID是不同的,查询所有的员工信息,此时就会发生N+1条SQL语句。
1:select * from employee
N:select * from department where id = ?
此时导致N+1问题的原因在使用额外的SQL语句去查询的。
解决方案:使用多表查询(JOIN)一条SQL语句搞定。
处理多表查询的结果集:内联映射。
对象关联的查询:
方式一:额外SQL(分步查询),一般需要进入另一个页面显示更详细信息的时候使用
方式二:内联映射(多表查询)
延迟加载(lazy load):懒加载
为了避免一些无所谓的性能开销而提出的一个概念。
定义:在真正需要使用到数据的时候,才去执行SQL去查询数据。
<!-- 全局配置-->
<settings>
<!-- 日志技术 -->
<setting name="logImpl" value="LOG4J"/>
<!-- 开启延迟加载功能 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 设置不要积极地去查询关联对象(在 3.4.1 及之前的版本默认值为 true) -->
<setting name="aggressiveLazyLoading" value="false"/>
<!-- 延迟加载触发的方法 -->
<setting name="lazyLoadTriggerMethods" value="clone"/>
</settings>
配置选择
在开发中,
针对单属性对象,使用association元素,通常直接使用多表查询操作,也就是使用内联查询。
针对集合属性对象,使用collection元素,通常使用延迟加载,也就是额外SQL处理。
缓存机制
缓存(Cache):可以使应用更快地获取数据,避免和数据库数据做频繁的交互操作,尤其是在查询操作比较频繁的时候,当缓存命中率比较高的时候,缓存的优势就很明显。一般读远远大于写操作的数据适合放到缓存中。
原理:Map
- 查询的时候先从缓存中去查询数据
A:找到,就离开返回
B:找不到,GOTO2
- 去查询数据库
A:把查询的数据放进缓存中,供下次使用
B:返回数据
MyBatis的缓存:
- 一级缓存,也称之为本地缓存,默认已经开启,不能关闭,性能提升比较差。一级缓存好比在SqlSession中存在一个Map,用来缓存查询出来的对象,对性能的提升是有限的,每一次操作我们都使用新的SqlSession对象,SqlSession之间不共享一级缓存。
- 二级缓存,也称之为查询缓存,需要手动开启和配置,也可以使用第三方的缓存技术如EhCache,Redis等。
Mapper级别,作用域是mapper文件的同一个namespace。二级缓存应该和namespace绑定在一起。
(在MyBatis中实现缓存只需要实现Cache接口就可以了,MyBatis已经提供了一个自带的缓存技术。)
使用二级缓存:
- 在全局配置文件中,启用二级缓存。
<!- 启用二级缓存,缺省已经启用 -->
<setting name="cacheEnabled" value="true"/>
- 在mapper文件中,使用cache元素,把namespace和缓存相绑定
<cache/>
- 把放入二级缓存对象实现序列化接口
public class Teacher implements java.io.Serializable {}
二级缓存配置细节:
当启用二级缓存之后,
- mapper文件中所有的select元素都会使用到缓存。
- 在大多数情况下,针对于列表查询,设置为不缓存,只有SQL和参数相同的时候,才会使用到缓存。useCache="false"
- 一般的,只会对get方法做查询缓存。
- 默认情况下,insert,delete,update操作都会去刷新缓存,但是对象插入操作却没有必要。flushCache="false"
EhCache
EhCache是一种广泛使用的开源Java分布式缓存。快速、简单、多种缓存策略、缓存数据有内存和硬盘两级。缓存数据会在JVM重启的过程中写入硬盘,支持多缓存管理器实例一级一个实例的多个缓存区域。
依赖:
ehcache-core-2.6.11.jar
mybatis-ehcache-1.1.0.jar
slf4j-api-1.7.25.jar
slf4j-log4j12-1.7.25.jar
MyBatis Generator
MyBatis Generator简称MBG,是一个专门为iBatis、MyBatis框架使用者提供的代码生成器,可以快速的根据表生成对应的模型对象、Mapper接口、Mapper文件,甚至生成QBC风格查询对象。MBG支持基本的增删改查操作,也支持QBC风格的条件查询,但是复杂的查询还是需要我们写SQL完成。
文档地址:http://www.mybatis.org/generator/
工程地址:https://github.com/mybatis/generator/releases
MyBatis Generator的使用:
- 拷贝jar包: mybatis-generator-core-1.3.7.jar
- 提供一个MBG的配置generatorConfig.xml,包含了生成代码和配置的参数
- 运行MBG
方式一:使用Java代码运行(代码不需要大家写,直接用)
Java代码:
public class Generator {
public static void main(String[] args) throws Exception {
//MBG执行过程中的警告信息
List<String> warnings = new ArrayList<>();
//生成代码重复时,是否覆盖源代码
boolean override = false;
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream("generatorConfig.xml");
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(in);
DefaultShellCallback callback = new DefaultShellCallback(override);
//创建MBG
MyBatisGenerator mbg = new MyBatisGenerator(config, callback, warnings);
mbg.generate(null);
//输出警告信息
for(String warn : warnings) {
System.out.println(warn);
}
}
}
方式二:使用Maven插件运行
QBC
QBC风格:Query By Criteria,一种查询方式,比较面向对象的,看不到任何的SQL语句。
主要由Criteria,Example组成,使用面向对象的方式去拼写查询条件,一般的适用于简单查询。(案例见源码)
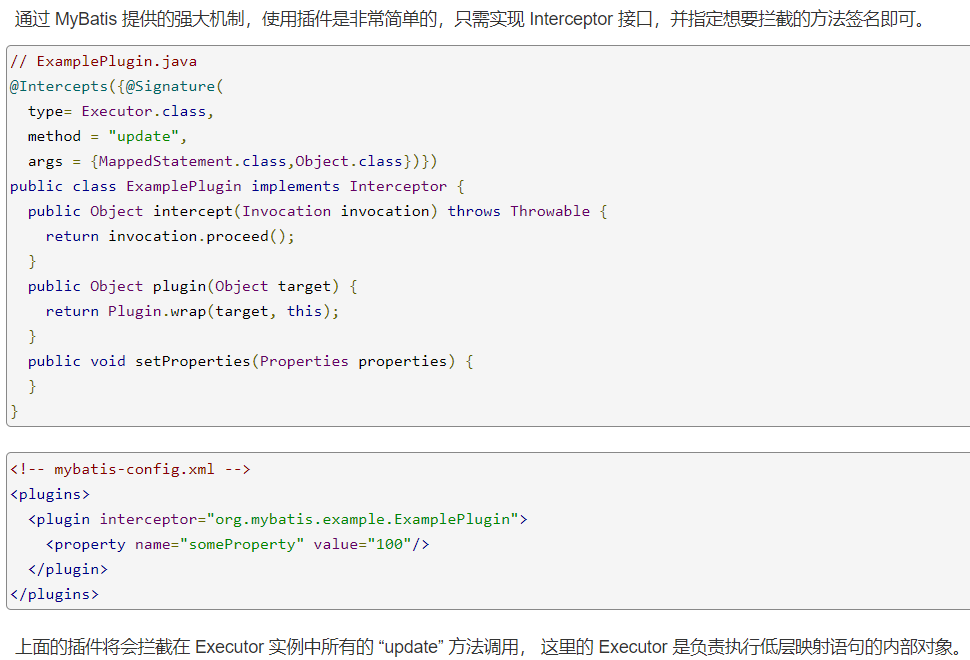
MyBatis的插件原理
MyBatis在四大组件对象的创建过程中,都会有插件进行调用执行。我们可以利用动态机制对目标对象实施拦截增强操作,也就是在目标对象执行目标方法之前进行拦截增强的效果。MyBatis允许在已映射语句执行过程中的某一个时机来进行拦截增强,我们把这种机制称之为插件,其实就是动态代理。
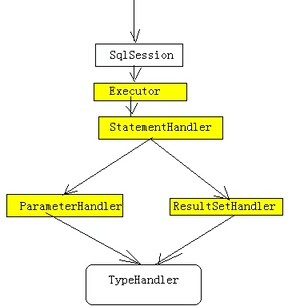
MyBatis 允许使用插件来拦截的方法调用包括:
Executor (update,query,flushStatements,commit,rollback,getTransaction,close,isClosed)
ParameterHandler (getParameterObject,setParameters)
ResultSetHandler (handleResultSets, handleOutputParameters)
StatementHandler (prepare,parameterize,batch,update,query)
PageHelper插件
API:https://github.com/pagehelper/Mybatis-PageHelper/blob/master/wikis/en/HowToUse.md
PageHelper是MyBatis的分页插件,开源,不少的企业都在使用该插件