楔子
Python和C、C++之间一个最重要的差异就是Python是解释型,而C、C++是编译型。如果开发Python程序,那么在修改代码之后可以立刻运行,而C、C++则需要一个编译步骤。而编译一个规模比较大的C、C++程序,那么可能会花费我们几个小时甚至几天的时间;而使用Python则可以让我们进行更敏捷的开发,从而更具有生产效率。
而Cython同C、C++类似,在源代码运行之前也需要一个编译的步骤,不过这个编译可以是隐式的,也可以是显式的。而自动编译Cython的一个很棒的特性就是它使用起来和纯Python是差不多的(补充:编译之后得到的是pyd,这个可以直接当成py文件进行import),无论是显式还是隐式,我们都可以将Python的一部分(计算密集)使用Cython重写,因此Cython的编译需求可以达到最小化。
在这一篇博客中,我们将会介绍编译Cython代码的几种方式,并结合Python使用。因为我们说Cython是为Python提供扩展模块,最终还是要通过Python解释器来调用的。
而编译Cython有以下几个选择:
Cython代码可以在IPython解释器中进行编译,并交互式运行。Cython代码可以在导入的时候自动编译。Cython代码可以通过类似于Python的disutils模块的编译工具进行独立编译。(补充:就是我们上面一直说的编译成pyd,Cython代码的后缀是pyx,我们会单独先编译成pyd,然后交给Python进行导入。)Cython代码可以被继承到标准的编译系统,例如:make、CMake、SCons
这些选择可以让我们在几个特定的场景应用Cython,从一端的快速交互式探索到另一端的快速构建。
注意:虽然编译Cython代码的方式有很多种,但是没有必要全部了解,可以选择性阅读。
无论是哪一种编译方式,从传递Cython代码到生成Python可以导入和使用的扩展模块都需要经历两个步骤。在我们讨论每种编译方式的细节之前,了解一下在Pipeline中发生了什么是很有帮助的。
Cython编译的Pipeline
因为Cython是Python的超集,所以Python解释器无法直接导入Cython的代码并运行,那么如何才能将Cython代码变成Python解释器可以识别的有效代码呢?答案是通过Cython编译Pipeline。
Pipeline的职责就是将Cython代码转换成Python解释器可以直接导入并使用的Python扩展模块。这个Pipeline可以在不受用户干预的情况下自动运行(使Cython感觉像Python一样),也可以在需要更多控制时由用户显式的运行。
我们说Cython代码Python解释器无法直接运行,但是Cython也支持纯Python模式,在引入Cython代码中的声明时还能保证原来Python代码在语法上的有效性。只不过这里我们不会介绍这种方式,有兴趣可以自己去了解。
Pipeline由两步组成:第一步是由cython编译器负责将Cython转换成经过优化并且依赖当前平台的C、C++代码;第二步是使用标准的C、C++编译器将第一步得到的C、C++代码进行编译并生成标准的共享库,并且这个共享库是依赖特定的平台的。如果是在Linux或者Mac OS,那么得到的是扩展名为.so的共享库文件,如果是在Windows平台,那么得到的是扩展名为.pyd结尾的扩展模块(扩展模块pyd本质上是一个DLL文件,因此也称之为动态链接库)。不管是什么平台,最终得到的是一个成熟的Python扩展模块,它是可以直接被Python解释器进行import的。
而工具在管理这几个步骤所面临的复杂性,我们都会在这一篇博客的结尾进行描述。尽管在编译Pipeline运行的时候我们很少去关注究竟发生了什么,但是将这些过程记在脑海总归是好的。
Cython编译器是一种
源到源的编译器,并且生成的扩展模块也是经过高度优化的,因此Cython生成的C代码比手写的C代码运行的要快并不是一件稀奇的事情。如果可以的话,在写Cython代码的同时,你也可以手动写一个实现相同功能的C版本的代码出来,不出意外的话,Cython运行的速度会比手写的C版本代码的运行速度要快,至少在同级别的代码Cython不会慢。因为Cython生成的C代码是经过高度精炼,所以大部分情况下比手写所使用的算法更优。而且Cython生成的C代码支持所以的通用C编译器,生成的扩展模块同时支持许多不同的Python版本。
安装并测试
现在我们知道在编译Pipeline中有两个步骤,而实现这两个步骤需要我们确保机器上有C、C++编译器以及Cython编译器,不同的平台有不同的选择。
C、C++编译器
Linux和Mac OS无需多说,因为它们都自带gcc。至于Windows,可以下载一个Visual Studio,但是那个玩意会比较大,个人建议可以直接下载一个MinGW并设置到环境变量中,至于下载方式可以去https://sourceforge.net/projects/mingw/files/进行下载。
安装Cython
安装Cython的话,可以直接通过pip install cython即可。因此我们看到cython编译器只是Python的一个第三方包,因此运行Cython代码同样要借助Python解释器。
测试是否安装成功
在终端中输入cython -V,看看是否会提示cython的版本,如果正常显示,那么证明安装成功。
或者写代码查看
from Cython import __version__
print(__version__) # 0.29.14
如果代码正常执行,那么证明安装成功。
标准方式:使用disutils
Python有一个标准库disutils,可以用来构建、打包、分发Python工程。而其中一个对我们有用的特性就是它可以将C源码编译成扩展模块,并且这个模块是自带的、考虑了平台、架构、python版本等因素,因此我们在任意地方使用disutils都可以得到扩展模块。
注意:上面disutils只是帮我们完成了Pipeline的第二步,那第一步呢?第一步则是需要cython来完成。
举个栗子
以我们之前说的斐波那契数列为例子
# fib.pyx
def fib(n):
"""这是一个扩展模块"""
cdef int i
cdef double a=0.0, b=1.0
for i in range(n):
a, b = a + b, a
return a
然后我们对其进行编译
from distutils.core import setup
from Cython.Build import cythonize
# 我们看到构建扩展模块通过distutils.core下的setup
# 但是我们说distutils只能完成第二步,第一步要由Cython完成
# 所以使用cythonize("fib.pyx")
setup(ext_modules=cythonize("fib.pyx"))
# cythonize("fib.pyx")负责将Cython代码转成C代码
# 然后根据C代码生成扩展模块,我们可以传入单个文件,也可以是多个文件组成的列表
# 或者一个glob模式,会匹配满足模式的所有Cython文件
这个文件叫做1.py,这里只是做了准备,但是还没有进行编译。我们需要终端执行python 1.py build进行编译。
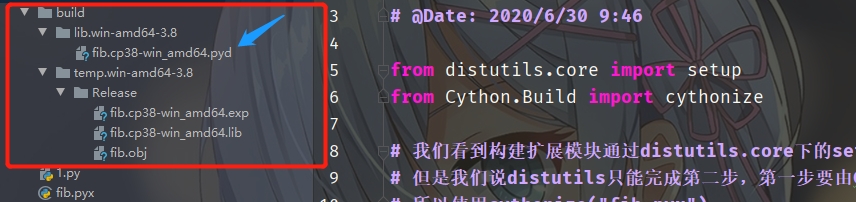
在我们执行命令之后,当前目录会多出一个build目录,里面的结构如下。重点是那个fib.cp38-win_amd64.pyd文件,该文件就是根据fib.pyx生成的扩展模块,至于其它的可以直接删掉了。
import fib
# 我们看到该pyd文件直接就被导入了,至于中间的cp38-win_amd64指的是对应的解释器版本、操作系统等信息
# 可以不用管,甚至你删掉只保留fib.pyd也是可以的。
print(fib) # <module 'fib' from 'C:\Users\satori\Desktop\三无少女\fib.cp38-win_amd64.pyd'>
try:
# 我们在里面定义了一个fib函数,在fib.pyx里面定义的对象在编译成扩展模块之后可以直接使用
print(fib.fib("xx"))
except Exception:
import traceback
print(traceback.format_exc())
"""
Traceback (most recent call last):
File "C:/Users/satori/Desktop/三无少女/2.py", line 10, in <module>
print(fib.fib("xx"))
File "fib.pyx", line 4, in fib.fib
def fib(int n):
TypeError: an integer is required
"""
# 因为我们定义的是fib(int n), 所以传入的不是整型,直接报错
print(fib.fib(20)) # 6765.0
# 我们的注释
print(fib.fib.__doc__) # 这是一个扩展模块
我们在Linux上再测试一下,代码以及编译方式都不需要改变,并且生成的动态库的位置也不变。
>>> import fib
>>> fib
<module 'fib' from '/root/fib.cpython-36m-x86_64-linux-gnu.so'>
>>> exit()
我们看到依旧是可以导入的,只不过Linux上是.so的形式,Windows上是.pyd。
cythonize()会返回一个列表,里面是disutils扩展对象,setup函数知道如何转换成Python扩展模块。cythonize函数还有其它一些参数,可以自己看一下,里面有详细的注释,当然我们后面也会用到。
除此之外我们还可以嵌入C、C++的代码,我们来看一下。
// cfib.h
double cfib(int n); // 定义一个函数声明
//cfib.c
double cfib(int n) {
int i;
double a=0.0, b=1.0, tmp;
for (i=0; i<n; ++i) {
tmp = a; a = a + b; b = tmp;
}
return a;
} // 函数体的实现
然后是pyx文件
# 通过cdef extern from导入头文件,写上里面的函数
cdef extern from "cfib.h":
double cfib(int n)
# 然后python可以直接调用
def fib_with_c(n):
"""调用C编写斐波那契数列"""
return cfib(n)
最后是编译
from distutils.core import setup, Extension
from Cython.Build import cythonize
# 我们看到之前是直接往cythonize里面传入一个文件名即可
# 但是现在我们传入了一个扩展对象,通过扩展对象的方式可以实现更多功能
ext = Extension(name="wrapper_fib", sources=["fib.pyx", "cfib.c"])
setup(ext_modules=cythonize(ext))
然后我们来调用一下
Python 3.6.8 (default, Aug 7 2019, 17:28:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import wrapper_fib
>>> wrapper_fib
<module 'wrapper_fib' from '/root/wrapper_fib.cpython-36m-x86_64-linux-gnu.so'>
>>> wrapper_fib.fib_with_c(20)
6765.0
>>> wrapper_fib.fib_with_c.__doc__
'调用C编写斐波那契数列'
>>>
我们看到成功调用C编写的斐波那契数列,这里我们使用了一种新的创建扩展模块的方法,我们来总结一下。
- 如果是单个pyx文件的话,那么直接通过cythonize("xxx.pyx")即可。
- 如果pyx文件还引入了C文件,那么通过
cythonize(Extension(name="xx", source=["", ""]))的方式即可。name是编译之后的扩展模块的名字,sources是你要编译的源文件,我们这里是一个pyx文件一个C文件。建议后续都使用第二种方式,可定制性更强,而且我们之前使用的
cythonize("fib.pyx")完全可以用cythonize(Extension("fib", ["fib.pyx"]))进行替代。
那么问题来了,如果我们引入了一个已经写好的动态库该怎么办呢?因为不是文本文件的形式,这个时候就需要通过Extension的其它参数(library_dirs、libraries)指定了。具体可以查看相关注释,非常详细,这里就不说了。
通过IPython动态交互Cython
使用distutils编译Cython代码可以让我们控制每一步的执行过程,当时也意味着我们在使用之前必须要先经过独立的编译,不涉及到交互式。而python的一大特性就是交互式,比如IPython,所以需要想个法子让Cython也支持交互式,而实现的办法就是使用魔法命令。
# 我们在jupyter上运行,执行上面代码便会加载Cython的一些魔法函数
In [1]: %load_ext cython
# 然后神奇的一幕出现了,加上一个魔法命令,就可以直接写Cython代码
In [2]: %%cython
...: def fib(int n):
...: """这是一个Cython函数,在IPython上编写"""
...: cdef int i
...: cdef double a = 0.0, b = 1.0
...: for i in range(n):
...: a, b = a + b, a
...: return a
# 测试用时,只花了82.6ns
In [6]: %timeit fib(50)
82.6 ns ± 0.677 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
使用pyximport即时编译
因为Cython是是以Python为中心的,我们说它依赖于Python解释器。所以我们也希望,在使用Cython源文件的时候就像使用常规的、动态的、可导入的Python源文件一样。
try:
import fib
except ImportError as e:
print(e) # No module named 'fib'
Python解释器在执行import语句的时候,是不会去找后缀为.pyx的文件的,因此即使当前存在一个fib.pyx也是无效的。而我们如果希望Python把pyx文件当成普通的py文件看待的话,则需要导入一个模块,调用该模块的install函数。然后会修改import语句,使其可以识别pyx扩展模块,并且通过编译Pipeline自动编译。
# fib.pyx
def foo(int a, int b):
return a + b
# 2.py
import pyximport
# 这里指定language_level=3,则表示针对的是py3,默认是2,表示针对py2
# 当然即使不指定也不会报错,只是导入的时候会弹出警告让人很不舒服。
# 另外,如果不指定话,生成的扩展模块会同时兼容Python2和Python3,但是现在基本上都只用Python3了
# 另外我们在编译扩展模块的时候,在cythonize也可以指定这个参数,不然也会弹出警告。我们后面还会说
pyximport.install(language_level=3)
import fib
print(fib.foo(11, 22)) # 33
正如我们上面演示的那样,使用pyximport可以省去distutils这一步骤。另外,Cython源文件不会立刻编译,只有当被导入的时候才会编译,并且即便Cython源文件被修改了,pyximport也会自动检测,当重新执行的时候也会再度重新编译。
但是这样有一个弊端就是,我们说pyx文件并不是导入就能用的,而是在导入之后还有一个编译成扩展模块的步骤,只不过这一步骤不需要我们手动来做了。所以它依赖你当前有一个cython编译器以及合适的C编译器,而我们一开始的在pyx中引入C的代码是在Linux上演示的,因为Windows上由于我gcc的原因总是失败。所以这种导入放式,对你当前的环境有要求,而这些环境是不受控制的,没准哪天就编译失败了。因此最保险的方式还是使用我们之前说的distutils,先编译成扩展模块(.pyd或者.so),然后再放在生产模式中使用。
总结
目前我们介绍了如何将pyx文件编译成扩展模块,方法我们再说一下:
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = Extension(
name="wrapper_fib", # 生成的扩展模块的名字
sources=["fib.pyx"], # 源文件,可以是多个
)
setup(ext_modules=cythonize(ext, language_level=3)) # 指定Python3
至于如何编写Cython代码,我们将会在下一篇博客中介绍。
至于如何编写Cython代码,我们将会在下一篇博客中介绍。关于编译这一块介绍的不够详细,而且我是一边学一边写博客的,就当是看学习笔记了吧。而且里面有一些个人觉得不是很常用,毕竟笔者不是C系的,所以像什么CMake啥的就没提。我们的重点是学习Cython代码的编写上,下一篇博客见。