楔子
下面我们来介绍一个处理图像的高性能模块,叫做opencv,这个opencv可以对图像做各种处理,甚至还可以处理视频,比我们之前介绍的PIL模块还要强大。这里我们使用的语言为python,所以请保证使用的机器上有python环境,而最好保证版本不低于3.6,我这里使用的是python 3.8。有了python,还要有相应的模块,直接pip install opencv-python即可。下面演示一个小例子:
import cv2
# 函数imread表示读取一张图片,里面随便输入一张图片的路径
src = cv2.imread("image/sora.png")
cv2.imshow("sora", src)
cv2.waitKey(0)

如果能将图片展示出来,证明安装没有问题。上面的方法暂时不用关心,我们后面会介绍。
图像的读取与保存
什么是图像
首先我们要介绍一下什么是图像,图像的本质就是一个三维的数组,第一维表示图片的每一行、第二维表示图片的每一列,第三维表示像素点的RGB、也就是一个长度为3的数组(如果是普通的彩色图片)。我们经常说一张图片是1920 x 1080的,其实代表的含义就是这张图片每一行有1920个像素点(长为1920),每一列有1080个像素点(高为1080),共有1920 * 1080个像素点,每一个像素点是一个RGB(假设是彩色图片),会显示出一种颜色,那么1920 * 1080个具有各自颜色的像素点就拼凑成了一张人类能看到的图像。另外对于一张1920 x 1080的图片,转化成三维数组之后,如果我想拿到右下角的像素点对应的RGB(那个长度为3的数组)的话,通过索引去查找就应该是[1079, 1919],因为索引是从0开始的。注意:不是[1919, 1079],这样的话就反了。因为对于三维数组,我们肯定是要先确定第一维、再确定第二维,第一维表示图片有多少行像素,第二维表示图片有多少列像素。而对于1920 x 1080的图片来讲,指的就是这张图片有1080行,1920列,而我们对于三维数组是先确定第一个维度(图片的行),后确定第二个维度(图片的列),所以是[1079, 1919]。这一点务必切记,因为这和我们人类的思维理解是相反的,所以啰嗦的有点多。
import cv2
src = cv2.imread("image/sora.png")
# 我们看到,使用imread将图片读取进来之后,那么得到的就是一个numpy中的数组
print(type(src)) # <class 'numpy.ndarray'>
# 打印显示维度是3
print(src.ndim) # 3
# 由于我这是一张彩色图片,那么得到的形状就是(468, 712, 3)
# 表示图片有468行,712列,每一个点是一个RGB
# 那么按照我们平常的说法,这张图片就应该是 712 x 468,表示长是712,高是468
print(src.shape) # (468, 712, 3)
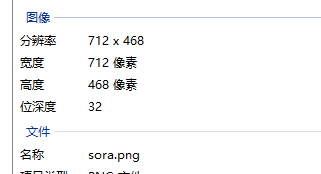
事实证明确实如此,只不过Windows用的是宽度和高度,而我们用的是长度和高度,但是都差不多啦。而且我们看到使用cv2将图片读取进来之后,就是numpy的一个三维ndarray,因此这个cv2和numpy是无缝对接的,所以说真的非常强大。
图像的三维数组
import cv2
src = cv2.imread("image/sora.png")
print(src.shape) # (468, 712, 3)
# src.size表示共有多个元素
# 像素的话,共有468 * 712个,但是每个像素又是一个长度为3的数组,所以像素再乘上3,就是我们这里图片对应数组的元素个数啦,也就是size
print(src.size, 468 * 712 * 3) # 999648 999648
# 我们看到类型是uint8,uint8表示无符号8位整型,所以范围是0~255
# 而每一个像素点的范围也是0~255
print(src.dtype) # uint8
# 实际上,就像我们刚才说的,这个src就是numpy中的一个三维array
# 如果熟悉numpy的话,那么操作会很简单,比如说我们可以把前100行全部描黑
# 那么就把前100行的每个像素都换成[0, 0, 0]即可
src[0: 100, :] = [0, 0, 0] # 注意这里是第一个维度
# 如果不熟悉numpy的话,那么建议去看一下numpy的用法,这是一个很强大的库,算是python中数据处理、乃至机器学习领域的万物之源
# 显示图片
cv2.imshow("sora", src)
cv2.waitKey(0)

import cv2
src = cv2.imread("image/sora.png")
# 我们刚才描黑了前100行,那如果我想描黑前100列呢?
# 那么就把前100列的每个像素都换成[0, 0, 0]即可
# 通过操作src就能操作这张图片的所有像素点
src[:, 0: 100] = [0, 0, 0] # 注意:由于是列,列是第二个维度,所以是src[:, 0: 100]
cv2.imshow("sora", src)
cv2.waitKey(0)
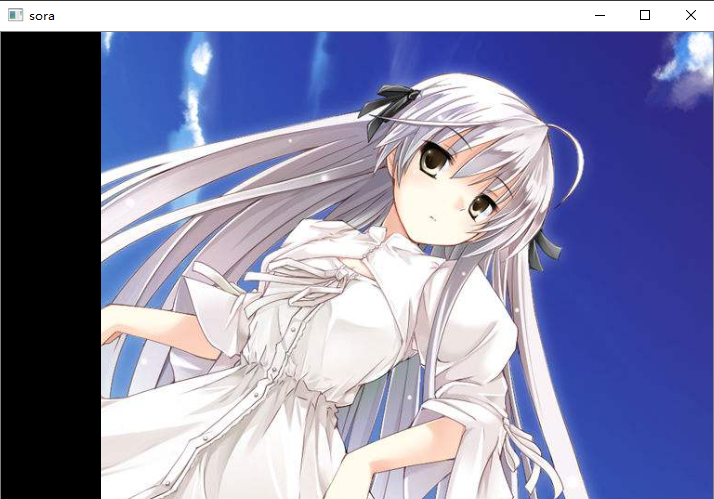
关于上面cv2的语法暂时不用管,只要知道我在做什么即可,我们后面会慢慢说,这里只是介绍图片的结构、以及它和底层三维数组之间的对应关系。最主要的还是引出了numpy,我想说的是,numpy是一个很强大的库,如果不熟悉numpy的话,就暂时不要看这篇博客了,建议先去看看numpy再来看这篇博客。关于numpy的博客我没有写,但是可以去菜鸟教程中搜索,这个模块很强大、然而常用的方法并不难,一两个小时就能掌握,然后再来看这篇博客足够了。
读取与保存
既然我们是要对图像进行处理,那么肯定要能够把图像读取进来。另外处理完了,我们肯定还要保存起来。那么opencv如何对图片进行读取和保存呢?
import cv2
# 关于图片的读取我们刚才已经用过很多遍了
# 主要调用函数imread,里面输入图片的路径即可,会得到包含这张图片的每一个像素点的三维数组
# 另外如果这张图片无法读取,或者指定的图片不存在,那么会返回None,不会报错
src = cv2.imread("image/sora.png")
# 这里表示创建一个窗口,因为图片要显示在窗口上面
# 参数1表示窗口的名字
# 参数2表示窗口大小,有以下几个参数:,cv2.WINDOW_GUI_NORMAL,cv2.WINDOW_AUTOSIZE,cv2.WINDOW_FREERATIO,cv2.WINDOW_KEEPRATIO
# cv2.WINDOW_NORMAL:窗口大小可以改变
# cv2.WINDOW_GUI_NORMAL:同上
# cv2.WINDOW_AUTOSIZE:窗口大小不可以改变
# cv2.WINDOW_FREERATIO:窗口大小自适应比例
# cv2.WINDOW_KEEPRATIO:窗口大小保持比例
# cv2.WINDOW_GUI_EXPANDED:窗口色彩变暗色
cv2.namedWindow("sora", cv2.WINDOW_AUTOSIZE)
# imshow表示显示图片,接收两个参数。
# 参数1:窗口的名字,对,你没有看错,还是窗口的名字
# 对于imshow显示图片来说,是需要创建一个窗口的,然后图片在窗口上显示。
# 调用imshow函数会自动帮我们创建,但是此时就没法指定窗口的属性了。
# 所以如果我们需要设置窗口属性,那么就需要调用namedWindow手动创建窗口并指定上面的某个窗口属性
# 但是一般我们是处理图片的,不太关注窗口什么样,所以我们一般都不会设置namedWindow。我在后续也不会设置,这里只是提一下有这么个东西
# 然而一旦设置了namedWindow,那么imshow里面的窗口名要和namedWindow里面的窗口名保持一致,这样图片才会在我们创建的窗口上显示
# 否则的话imshow函数依旧会单独创建一个窗口,此时就出现了两个窗口。imshow函数会把图片显示在自己创建的窗口上,而我们自己创建的窗口则什么也没有
# 至于参数2:显然就是图片对应的三维数组啦
cv2.imshow("sora", src)
# 这里表示暂停,如果没有这一行,那么显示图片后的瞬间,窗口就会关闭。
# 传入一个大于0的整数,表示窗口持续多少毫秒后关闭。传入0,表示让窗口一直不关闭
cv2.waitKey(0)
# 表示手动销毁窗口,如果程序结束也会自动销毁
cv2.destroyWindow("sora")
图片的读取介绍完了,下面是图片的保存,图片的保存也很简单
import cv2
src = cv2.imread("image/sora.png")
src[0: 100, :] = [0, 0, 0]
# 保存图片,直接调用cv2.imwrite即可
# 参数1:保存的文件名,会根据文件后缀自动判断图片格式。保存的图片格式和原始图片格式不一致也无所谓
# 参数2:图片的三位数组
# 参数3:图片的质量,这个默认值None,会自动选择,但是一般我们会手动进行设置,因为不希望保存的图片质量变差。参数如下:
# IMWRITE_JPEG_QUALITY:针对于jpg、jpeg格式的图片,范围是0-100,值越大质量越高,默认是95,因此文件是jpg文件格式,我们希望保存的图片质量最高,那么就可以这么保存
# cv2.imwrite("image/sora1.png", src, [cv2.IMWRITE_JPEG_QUALITY, 100])
# 但是注意:jpg格式的图片属于有损压缩,即使你把质量调成100,依旧会有损失
# IMWRITE_PNG_COMPRESSION:针对于png格式的图片,范围是0-9,值越大压缩比越大,得到的图片质量不变
# 因为png是属于无损压缩的,只不过压缩比增大,得到的图片体积会变小。
# IMWRITE_PXM_BINARY:这个是对于PPM,PGM或PBM格式的图片,不存在压缩。
cv2.imwrite("image/sora1.jpg", src, [cv2.IMWRITE_JPEG_QUALITY, 5])
# 因此如果保存的是png格式,对图片的大小,多一点少一点无所谓,那么第三个参数可以不用设置
# 如果保存的的是jpg格式,那么建议设置成100,不过即便设置成100,精度还是有丢失的。这里我们设置为5,保存为jpg,看看会变成什么样子。
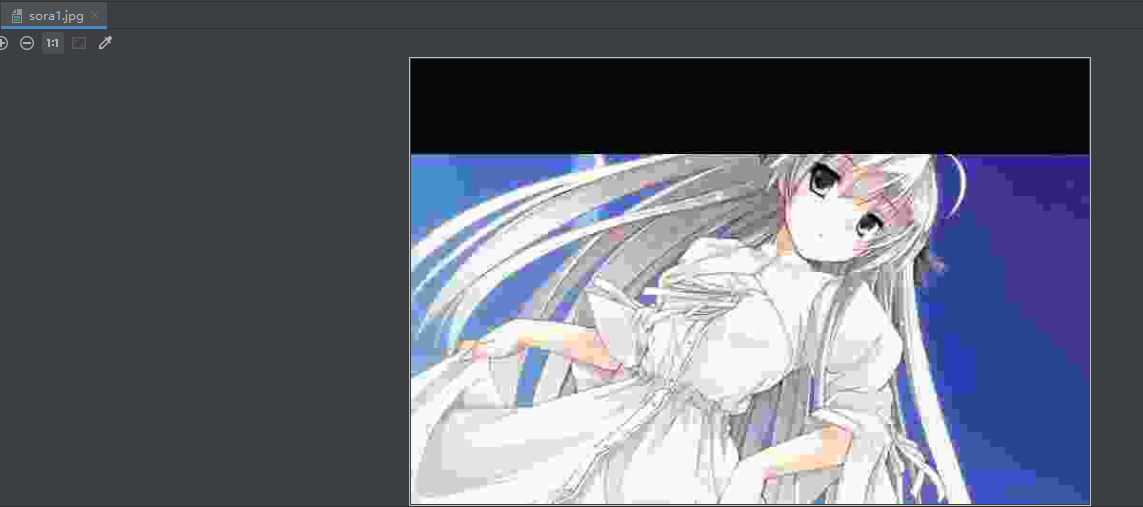
可以看到保存为jpg,品质设置为5,保存之后已经糟糕到无法看下去了。但是不管咋样,图片我们是保存下来了。
操作像素点
我们下面来对图片的像素进行一个操作,我们就对像素取反吧。假设一个像素点是[a, b, c],a,b,c肯定都是属于0到255的,那么我们就把该像素点变成[255-a, 255-b, 255-c]。对图片的每一个像素点都进行这样的操作。
import cv2
src = cv2.imread("image/sora.png")
# 获取图片的行数、列数,至于color,如果是彩色图片,那么color就是3,灰度图片,color就是1
rows, cols, color = src.shape
# 由于我们下面要遍历三层for循环,肯定会耗时不少,我们来计个时
t1 = cv2.getTickCount() # 表示cpu执行到这一步用了多少tick
# 遍历每一行
for row in range(rows):
# 遍历每一列
for col in range(cols):
# 遍历每一个颜色通道的值
for c in range(color):
src[row, col, c] = 255 - src[row, col, c]
# cv2.getTickFrequency()可以计算出当前cpu在1秒内会使用多少tick
# 相除得到秒数
print("总耗时:", (t2 - t1) / cv2.getTickFrequency()) # 总耗时: 2.1317877
cv2.imshow("sora", src)
cv2.waitKey(0)
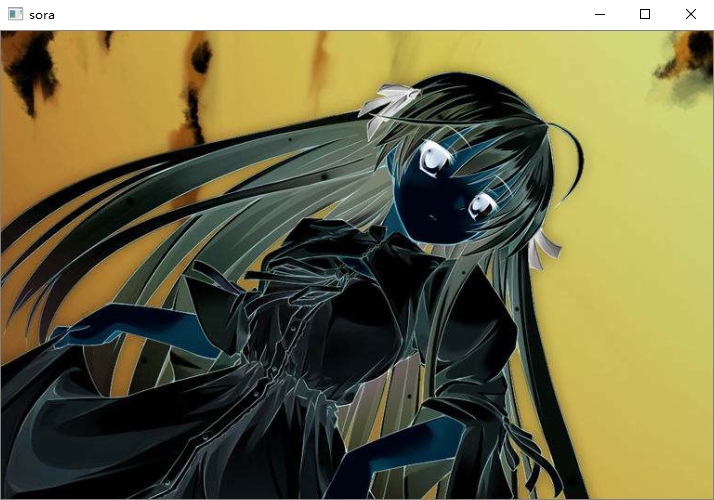
我们看到耗时两秒还是比较长的,因为是使用for循环处理每一个像素,等于是循环了468 * 712 * 3次,因此这样显然是不合适的。所以cv2提供了更简单的做法,这个是使用向量化进行操作的,速度肯定不是python的for循环能比的。
import cv2
src = cv2.imread("image/sora.png")
t1 = cv2.getTickCount()
# 这个是cv2提供的方法表示直接对一个像素的每一个通道都进行取反
# 输入原始的三维数组,会返回取反之后的三维数组
src = cv2.bitwise_not(src)
t2 = cv2.getTickCount()
print("总耗时:", (t2 - t1) / cv2.getTickFrequency()) # 总耗时: 0.0003634
cv2.imshow("sora", src)
cv2.waitKey(0)
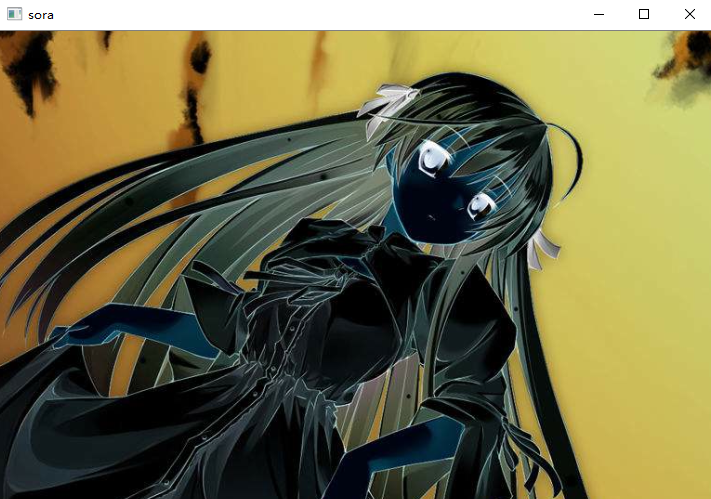
得到了结果是相同的,但是速度快了不知多少倍,这就是向量化的威力。另外既然有取反,那么有没有按位与、或、异或呢,答案是有的。不过由于取反是对一个元素取反,所以bitwise_not可以只输入一个三维数组即可,但是按位与、或、异或是需要两个三维数组的,对相同位置的像素进行相应操作,返回一个操作完之后的新的三维数组。
按位与:cv2.bitwise_and(src1, src2)按位或:cv2.bitwise_or(src1, src2)按位异或:cv2.bitwise_xor(src1, src2)按位取反:cv2.bitwise_not(src)
色彩空间
什么是色彩空间,我们说一个像素有三个通道,每个通道的取值范围都是0~255,每个通道取不同的值,那么三个通道组合起来就形成了不同的颜色。比如三通道都是0,那么就是黑色。三通道都是255,那么就是白色。关于色彩空间有很多种,如RGB,HSV,HLS,YCrCb,YUV等等,最常用的就是RGB。在opencv中,提供了大量的方法,可以让我们各种色彩空间中任意转换等等。
色彩空间转换
import cv2
src = cv2.imread("image/sora.png")
# 比如,我们把rgb图像转成灰度图像
# 另外,我们虽然一直说RGB,但是在opencv中,是使用bgr表示的
# 这里面有很多转换的方式,可以转成HSV,HLS,YCrCb,YUV等等
# 这里我们转换成灰度图,直接调用cvtColor方法,传入src,和你要转换的方式
# 这个转换的方式比较固定,就是cv2.COLOR_XXX2XXX,比如你要HLS转BGR,就是cv2.COLOR_HLS2BGR
src1 = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
cv2.imshow("sora_gray", src1)
src2 = cv2.cvtColor(src, cv2.COLOR_BGR2YCrCb)
cv2.imshow("sora_ycrcb", src2)
src3 = cv2.cvtColor(src, cv2.COLOR_BGR2HLS)
cv2.imshow("sora_hls", src3)
src4 = cv2.cvtColor(src, cv2.COLOR_BGR2YUV)
cv2.imshow("sora_yuv", src4)
cv2.waitKey(0)

以上就实现了BGR到其他色彩空间之间的转换,另外既然可以BGR转到其他色彩空间,那么还可以转回来。对应的api则是cv2.COLOR_GRAY2BGR,cv2.COLOR_YCrCb2BGR,cv2.COLOR_HLS2BGR,cv2.COLOR_YUV2BGR。
色彩提取
一张图片,我们可以提取具有某种颜色的部分,这个时候我们一般不会使用RGB色彩空间,而是会使用HSV,使用HSV可以更容易获取指定颜色的区域、对颜色进行跟踪,我们可以看一张图标。
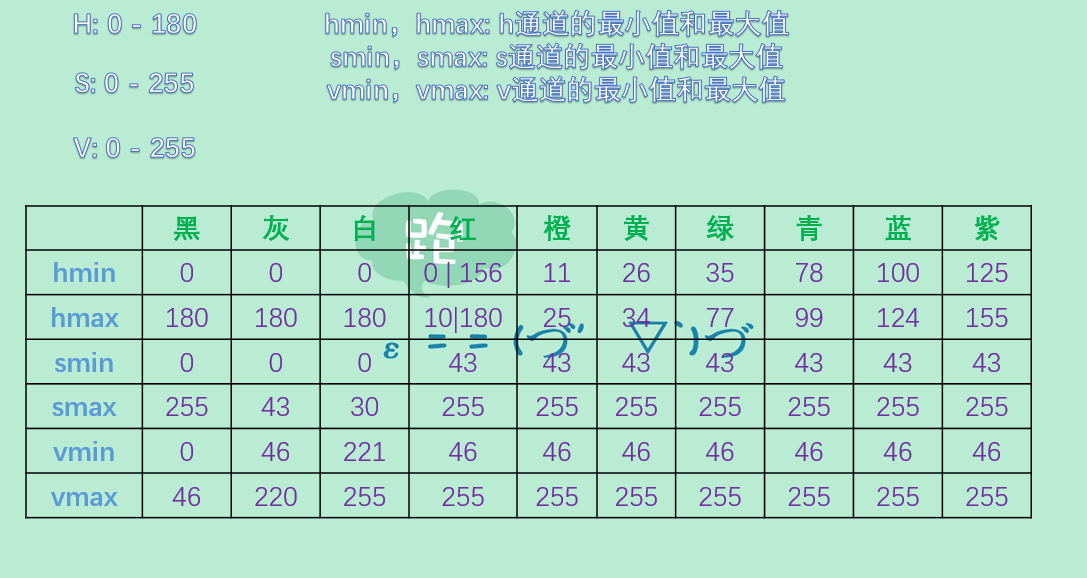

你就是老子的master吗?,我们来把saber的白色的那玩意提取出来吧
import cv2
import numpy as np
src = cv2.imread("image/saber.png")
# 转成HSV
hsv = cv2.cvtColor(src, cv2.COLOR_BGR2HSV)
# 找到白色hmin、smin、vmin
hsv_min = np.array([0, 0, 221])
# 找到白色hmax、smax、vmax
hsv_max = np.array([180, 30, 255])
# 调用inRange方法,传入三维数组、hsv_min,hsv_max
mask = cv2.inRange(hsv, hsv_min, hsv_max)
cv2.imshow("saber", mask)
cv2.waitKey(0)

效果不是很好,主要是因为颜色区分的不是很明显,有些地方并不是白色,但是接近白色也被提取出来了。因为我们指定的范围是最小值到最大值,只要在这个范围内都会被提取出来,因此可以适当地增大最小值、减小最大值,把范围缩小,或者再做一些其他的后期处理,还是能比较精确的提取的。所以使用hsv比较适合追踪图像,使用inRange搭配hsv就可以实现。
通道分离
我们说图片是有三通道的,那么可以使用opencv进行分离,分离出bgr三个通道。还是那句话,尽管我们一直叫rgb,但是在opencv中使用bgr,不过都是一个东西。
import cv2
src = cv2.imread("image/sora.png")
# 调用cv2.split可以对通道进行分离
b, g, r = cv2.split(src)
cv2.imshow("sora_b", b)
cv2.imshow("sora_g", g)
cv2.imshow("sora_r", r)
cv2.waitKey(0)

import cv2
src = cv2.imread("image/sora.png")
# 如果熟悉numpy的话,那么split和这个是等价的
b, g, r = src[:, :, 0], src[:, :, 1], src[:, :, 2]
cv2.imshow("sora_b", b)
cv2.imshow("sora_g", g)
cv2.imshow("sora_r", r)
cv2.waitKey(0)
分离出来之后,还可以进行合并。
import cv2
src = cv2.imread("image/sora.png")
b, g, r = cv2.split(src)
# r是一个numpy中的array,fill方法表示全部填充成0,表示使所有像素的r通道变成0
# 相当于减弱红色,从而凸显蓝色和绿色
r.fill(0)
# 调用merge方法,可以将多个通道组合在一起
# 传入一个元组
src1 = cv2.merge((b, g, r))
# 将所有像素的r通道变成255,相当于增强红色
r.fill(255)
src2 = cv2.merge((b, g, r))
cv2.imshow("sora1", src1)
cv2.imshow("sora2", src2)
cv2.waitKey(0)

像素运算
对cv2读取的图片的像素进行操作,就等于对numpy中的三维数组进行操作,所以我们可以很容易的对像素进行运算。像素运算,如果是两张图片的话,那么cv2要求这两张图片的结构必须是一样的,这里我又截了一张图,和之前的sora.png都是712 * 468的,叫satori.png
import cv2
import numpy as np
src1 = cv2.imread("image/sora.png")
src2 = cv2.imread("image/satori.png")
cv2.imshow("sora", src1)
cv2.imshow("satori", src2)
# 调用cv2.add对两个像素做加法,由于数组是np.uint8类型,如果相加超过255,那么会等于255
src3 = cv2.add(src1, src2)
cv2.imshow("sora_satori", src3)
cv2.waitKey(0)
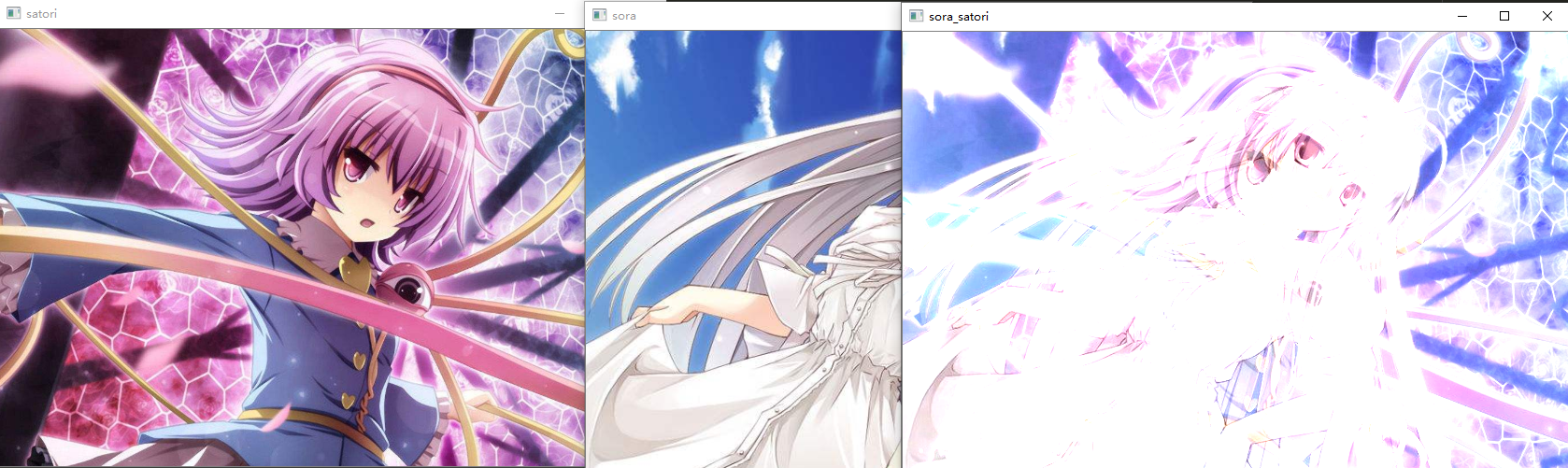
可以看到效果不是很好,非常白,其实也很好理解,两个像素相加结果肯定会变大,越接近255,就越白。同理还可以对像素做其它运算,值得一提的是,这些cv2提供的api,全部可以使用numpy进行手动运算,而且cv2这些api底层使用的也是numpy。
cv2.subtract(src1, src2):对应像素相减,相减会更接近0,那么图片会比较黑
cv2.multiply(src1, src2):对两个像素做乘法,这比相加还过分,会更白
cv2.divide(src1, src2):对两个像素做除法,这比相减还过分,会更黑
cv2.mean(src1, src2):对两个像素求均值
还记得之前说的,对像素进行位运算吗?
import cv2
import numpy as np
src1 = cv2.imread("image/sora.png")
src2 = cv2.imread("image/satori.png")
# 对两个像素进行按位与运算
src3 = cv2.bitwise_and(src1, src2)
cv2.imshow("sora_satori", src3)
cv2.waitKey(0)
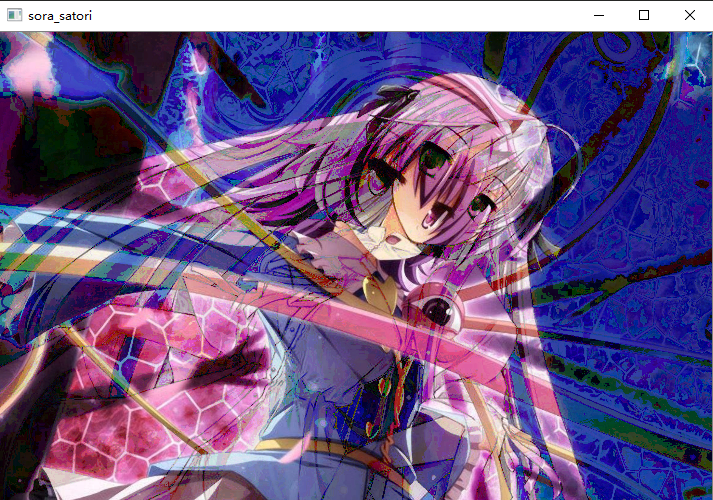
可能有人觉得,目前处理的效果不咋地啊,别急,只能说这不是opencv的问题,这是我们对像素进行这样的操作时得到的就是这样一个结果。
import cv2
import numpy as np
src1 = cv2.imread("image/sora.png")
src2 = cv2.imread("image/satori.png")
# 对两个数组的对应位置的像素比较,然后取大的那一方
src3 = np.where(src1 > src2, src1, src2)
# 对两个数组的对应位置的像素比较,然后取小的那一方
src4 = np.where(src1 < src2, src1, src2)
cv2.imshow("sora_satori1", src3)
cv2.imshow("sora_satori2", src4)
cv2.waitKey(0)
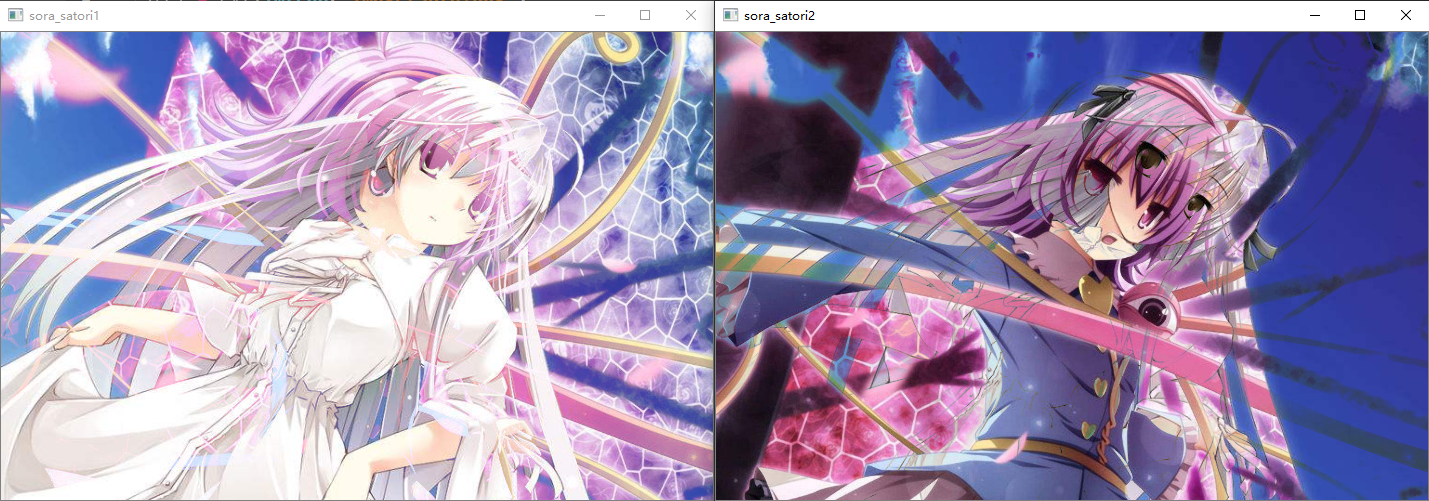
我们看到此时的效果稍微好一些了,其实用我们之前的PIL模块处理得到结果是一样的,进行这样的的运算就是这样的一个结果。
我们这里面有很多的api,我只演示了其中一部分,剩下可以自己尝试,非常简单。还是那句话cv2最大的特点就是把读取完的图片转换成了numpy的三维数组,我们使用numpy可以进行任意的变化,比如两个像素之前取方差、标准差、甚至是我们自定义的规则都行,包括cv2提供的位运算也可以,比如按位与:直接src1 & src2即可,所以还是那句话,用好cv2的前提是先用好numpy。
我们之前读取图片得到三维数组,那么我们处理之后也是三维数组,通过imshow展示成图像,那么我们也可以手动创建一个三维数组
import cv2
import numpy as np
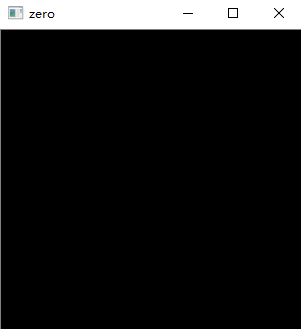
# 生成一个 100 * 100像素的图片,不要忘记指定类型为uint8
# zeros表示生成的数组的元素全部是0
src = np.zeros((300, 300, 3), dtype=np.uint8)
cv2.imshow("zero", src)
cv2.waitKey(0)
ROI与泛洪填充
什么是ROI,ROI就是你感兴趣的区域,不要误会ROI(region of interest)真的是感兴趣区域,以矩形、圆、椭圆、乃至不规则多边形等方式勾勒出需要处理的区域就叫做ROI。泛洪填充就是对ROI区域进行填充,名字很高大上,但是一旦知道具体含义就觉得不那么高大上了。
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
# 截取出图片的100~300行,200~400列
# 第三个维度,那个三元组如果不写,那么默认取全部
# 因此src[100: 300, 400: 600]和src[100: 300, 400: 600]是等价的
part = src[100: 300, 400: 600]
# 将这部分转换成灰度
part = cv2.cvtColor(part, cv2.COLOR_BGR2GRAY)
# 转化为灰度之后,那么像素就由三个点变成了一个点,所以我们再转回来
# 灰度转成BGR,不代表图像就变彩色了,还是灰色,只是结构和彩色图像是一样的
part = cv2.cvtColor(part, cv2.COLOR_GRAY2BGR)
# 再覆盖原来的图像
src[100: 300, 400: 600] = part
cv2.imshow("sora", src)
cv2.waitKey(0)
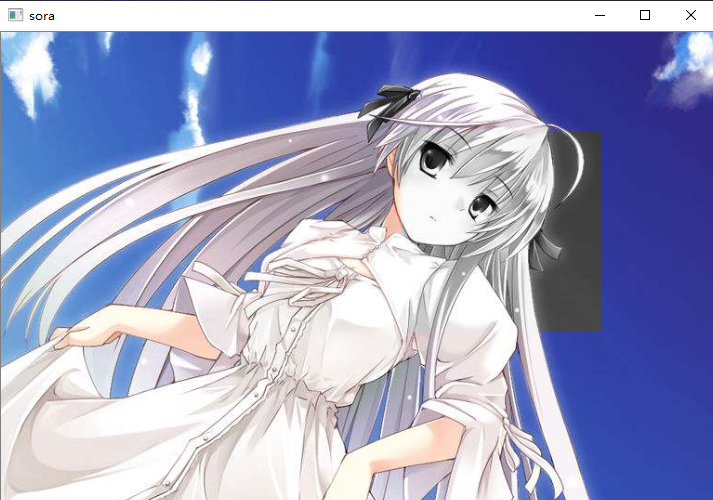
此时我们就把对应的区域给换掉了
模糊操作
模糊操作的基本原理就是使用离散卷积,定义好一个卷积核,卷积核进行移动,对一个像素点进行处理,得到一个新的像素点。这就意味着,不同的卷积核会得到不同的卷积效果,模糊也只是卷积的一种表象,我们举个最简单的例子。
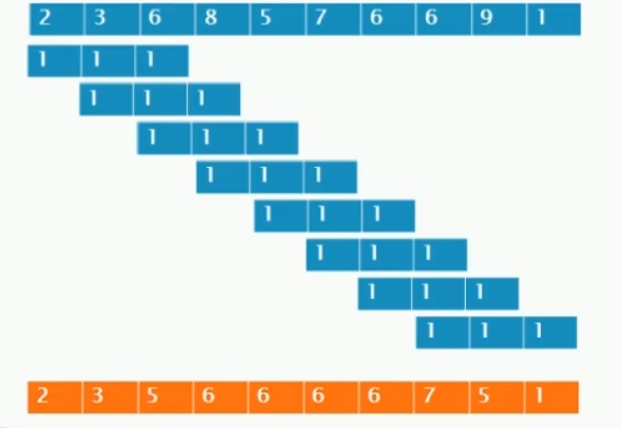
最上面的是我们原始的数据,1 1 1就是我们定义的卷积核,下面橙色的部分是原始数据经过卷积核处理之后的结果。首先我们的卷积核一定要定义成奇数个,只有这样才有中心点,而且我们看到开头的结果是没办法进行卷积的,那么就直接把原始数据拉过来即可。
卷积核先和原始数据的2 3 6 对齐,那么我们计算的是卷积核中心的位置,因为最左边的2没法计算,所以直接就取的是原始数据。而3我们看到对应的还是3,原始数据和卷积核对应相乘,1 *2 + 1 * 3 + 1*6,再取三者平均值,得到结果为3
然后卷积核向右移动一个步长,此时对应3 6 8,那么相乘取平均,得到5,就是这么计算得来的。当然卷积核可以多种多样,计算的方式也可以多种多样,数据的结构还是可以多种多样,我们这里只是举一个最简单的例子,来提一下卷积是个什么东西
而在opencv中,给我们提供了很多模糊的方式,这些数学公式底层都封装好了,直接用api调用即可,当然如果你知道数学原理的话,那么你完全可以使用numpy手动实现。
均值模糊
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
# blur表示均值模糊,参数一:原始数组
# 参数二:卷积核大小,一个元组,表示在x方向、y方向上的模糊程度,都必须是大于等于1的整数
# 比如(1, 15),这个是只在y方向模糊,(15, 1)只在x方向模糊,(15, 15)这个是两个方向都模糊
# 值越大,模糊程度越高
src1 = cv2.blur(src, (1, 15))
src2 = cv2.blur(src, (15, 1))
src3 = cv2.blur(src, (15, 15))
cv2.imshow("sora_no_blur", src)
cv2.imshow("sora_y_blur", src1)
cv2.imshow("sora_x_blur", src2)
cv2.imshow("sora_both_blur", src3)
cv2.waitKey(0)

中值模糊
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
src1 = cv2.medianBlur(src, 5)
cv2.imshow("sora_blur", src1)
cv2.waitKey(0)
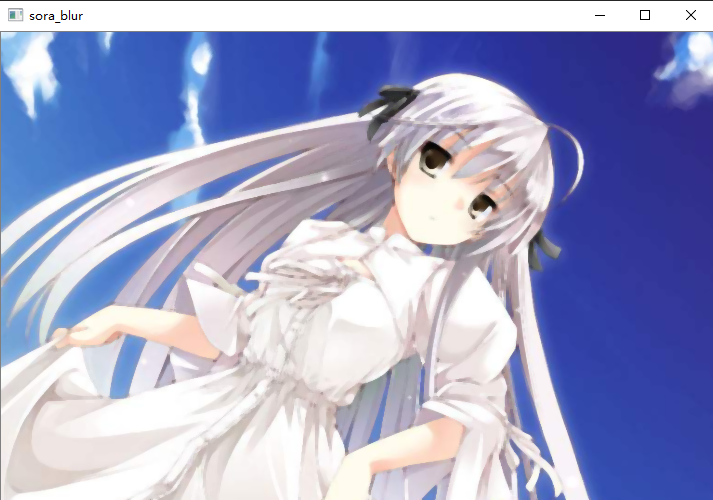
中值模糊具有很好的去噪效果,如果你的图像上有很多的小点的话,那么就可以通过中值模糊将其去掉。
自定义模糊
opencv提供了一个api,可以让我们自己定义模糊的规则,与其说的定义模糊,倒不如说是自定义卷积核
import cv2
import numpy as np
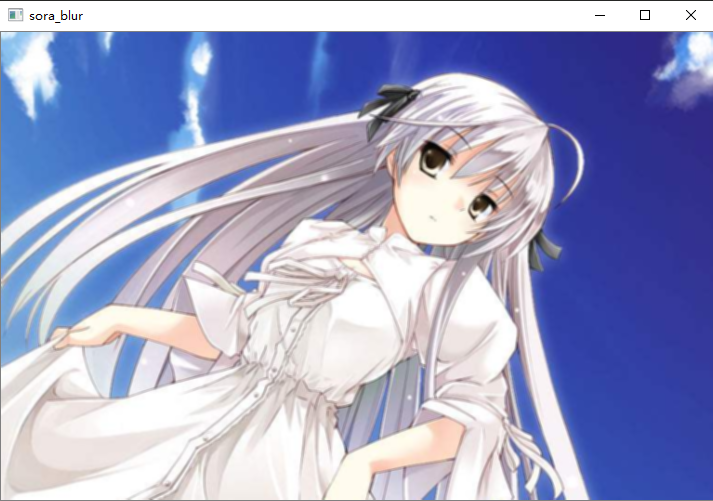
src = cv2.imread("image/sora.png")
# 这里为什么要除以9,因为要保证里面所有的元素相加等于1,所以类型要是浮点型,如果整型会截断就全变成0了
kernel = np.ones((3, 3), np.float32) / 9
# 参数1不用说,参数2表示深度,一般填入-1,参数3:kernel
src1 = cv2.filter2D(src, -1, kernel)
cv2.imshow("sora_blur", src1)
cv2.waitKey(0)
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
kernel = np.array([[0, -1, 0], [-1, 5, -1], [0, -1, 0]])
src1 = cv2.filter2D(src, -1, kernel)
cv2.imshow("sora_blur", src1)
cv2.waitKey(0)
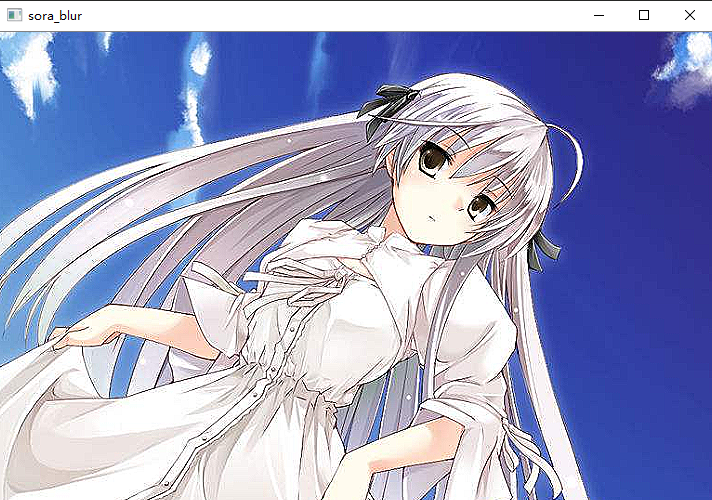
我们看到,此时就不再是模糊了,我们实现了锐化的效果。所以这个主要取决于卷积核,这个卷积核可不是随便定义的,是有数学原理的。
高斯模糊
高斯模糊可以看成是均值模糊的扩展,就是个像素的每一个点都加上一个随机值。
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
random = np.random.normal(0, 20, src.shape)
# 我们之前使用的是三层for循环,其实完全没有必要
# 如果需要使用三层for循环,那么numpy就不是numpy了
src1 = (src + random).astype(np.uint8) # 直接加即可,会将对应的每一个值都进行相加,但是必须要转成uint8类型
cv2.imshow("sora_blur", src1)
cv2.waitKey(0)

我们来看看opencv提供的高斯模糊
import cv2
import numpy as np
src = cv2.imread("image/sora.png")
# 参数1:src,参数2:卷积核大小,参数3:sigmaX
src1 = cv2.GaussianBlur(src, (5, 5), 5)
cv2.imshow("sora_blur", src1)
cv2.waitKey(0)