楔子
曾经在处理有关地铁人员数据的时候,遇到过两种格式的数据,当时确实把我给难住了。虽然最后解决了,但是方法不够优雅,一个是借助SQL来曲线救国,一个是使用纯Python逻辑。但是pandas作为一个非常优秀的第三方库,肯定提供了相应的解决方案,只不过当时在解决之后就没有之后了。然鹅最近这样的数据又碰到了,所以下定决心一定要使用pandas提供的方式解决,最后经过努力总算找到了解决的办法。
先来看看当时是哪两种数据让我感到困惑吧。
第一种数据:
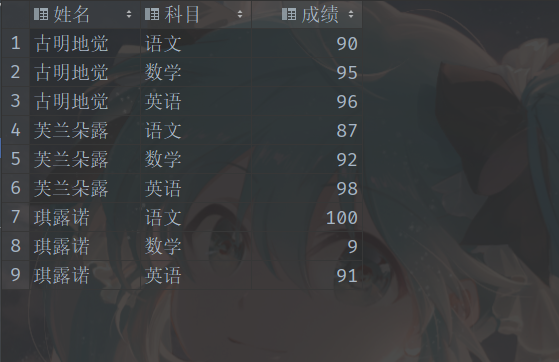
我们需要变成以下这种格式:
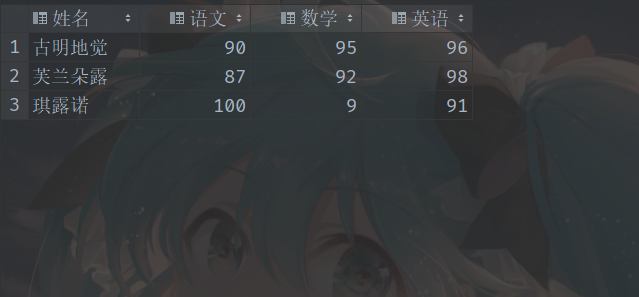
第二种数据:

我们需要变成以下这种格式:
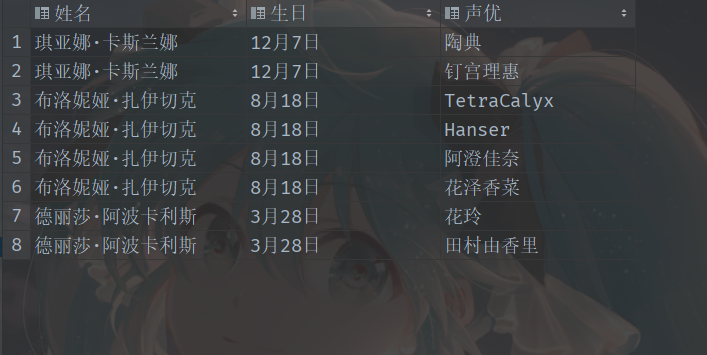
下面我们就来看看这两种格式的数据应该怎么处理。
处理第一种数据(行转列)
首先pandas中的Series对象有一个方法叫做unstack,调用一个具有二级索引的Series对象的unstack方法,会得到一个DataFrame对象。其索引就是Series对象的一级索引,列就是Series对象的二级索引。
print(df)
"""
姓名 科目 分数
0 古明地觉 语文 90
1 古明地觉 数学 95
2 古明地觉 英语 96
3 芙兰朵露 语文 87
4 芙兰朵露 数学 92
5 芙兰朵露 英语 98
6 琪露诺 语文 100
7 琪露诺 数学 9
8 琪露诺 英语 91
"""
# 将"姓名"和"科目"设置为索引, 然后取出"分数"这一列, 得到的对应的具有二级索引的Series对象
two_level_index_series = df.set_index(["姓名", "科目"])["分数"]
# 此时得到的Series就是一个具有二级索引的Series
# 一级索引就是"姓名"这一列, 二级索引就是"科目"这一列
print(two_level_index_series)
"""
姓名 科目
古明地觉 语文 90
数学 95
英语 96
芙兰朵露 语文 87
数学 92
英语 98
琪露诺 语文 100
数学 9
英语 91
Name: 分数, dtype: int64
"""
# 调用具有二级索引的Series的unstack, 会得到一个DataFrame
# 并会自动把一级索引变成DataFrame的索引, 二级索引变成DataFrame的列
new_df = two_level_index_series.unstack()
print(new_df)
"""
科目 数学 英语 语文
姓名
古明地觉 95 96 90
琪露诺 9 91 100
芙兰朵露 92 98 87
"""
# 是不是改回来了呢? 但是还有不完美的地方, 这个DataFrame的索引和列都有一个名字
# 索引的名字叫"姓名", 列的名字叫"科目", 因为原来Series的两个索引就叫"姓名"和"科目"
# 可以通过 rename_axis(index=, columns=) 来给坐标轴重命名
new_df = new_df.rename_axis(columns=None)
# 这里我们只给列重命名, 没有给索引重命名, 至于原因请往下看
new_df = new_df.reset_index()
print(new_df)
"""
姓名 数学 英语 语文
0 古明地觉 95 96 90
1 琪露诺 9 91 100
2 芙兰朵露 92 98 87
"""
# 大功告成, 如果index的名字变为空的话, 那么reset_index之后, 列名就会变成index
# 但如果原来的索引有名字, 那么reset_index之后, 列名就是原来的索引名
调用unstack默认是将一级索引变成DataFrame的索引,二级索引变成DataFrame的列。更准确的说,unstack是将最后一级的索引变成DataFrame的列,前面的索引变成DataFrame的索引。比如有一个具有八级索引的Series,它在调用unstack的时候,默认是将最后一级索引变成DataFrame的列,前面七个索引整体作为DataFrame的索引。
只不过索引一般很少有超过二级的,所以这里就用二级举例了。因此问题来了,那么可不可以将一级索引(这里的"姓名")变成DataFrame的列,二级索引(这里的"科目")变成DataFrame的行呢?答案是可以的,在unstack中指定一个参数即可。
print(df)
"""
姓名 科目 分数
0 古明地觉 语文 90
1 古明地觉 数学 95
2 古明地觉 英语 96
3 芙兰朵露 语文 87
4 芙兰朵露 数学 92
5 芙兰朵露 英语 98
6 琪露诺 语文 100
7 琪露诺 数学 9
8 琪露诺 英语 91
"""
two_level_index_series = df.set_index(["姓名", "科目"])["分数"]
# 这里的level默认是-1, 表示将最后一级的索引变成列
# 这里我们指定为0(注意: 索引从0开始), 告诉pandas, 把第一级索引变成列
new_df = two_level_index_series.unstack(level=0)
new_df = new_df.rename_axis(columns=None)
new_df = new_df.reset_index()
print(new_df)
"""
科目 古明地觉 琪露诺 芙兰朵露
0 数学 95 9 92
1 英语 96 91 98
2 语文 90 100 87
"""
# 我们看到结果就变了, 这种表示方式虽然有点奇怪, 但它也确实可以正确地表达出数据的含义
其实如果你思维够灵活的话,那么即使不使用level=0这个参数也可以实现这一点,那就是设置索引的时候不指定
["姓名", "科目"],而是指定["科目", "姓名"],这样"科目"就成为了一级索引,"姓名"就成了二级索引,一样可以完成任务。
除了stack之外, pandas还提供了一个模块级别的函数: pivot, 可以让我们更加方便地处理这种数据。
print(df)
"""
姓名 科目 分数
0 古明地觉 语文 90
1 古明地觉 数学 95
2 古明地觉 英语 96
3 芙兰朵露 语文 87
4 芙兰朵露 数学 92
5 芙兰朵露 英语 98
6 琪露诺 语文 100
7 琪露诺 数学 9
8 琪露诺 英语 91
"""
print(pd.pivot(df, index="姓名", columns="科目", values="分数"))
"""
科目 数学 英语 语文
姓名
古明地觉 95 96 90
琪露诺 9 91 100
芙兰朵露 92 98 87
"""
# 可以看到上面这一步,就直接相当于df.set_index(["姓名", "科目"])["分数"].unstack()
# 然后再手动rename_axis、再reset_index即可
# 如果我们是想将"姓名"变成列的话, 那么就指定columns="姓名"即可
print(pd.pivot(df, index="科目", columns="姓名", values="分数"))
"""
姓名 古明地觉 琪露诺 芙兰朵露
科目
数学 95 9 92
英语 96 91 98
语文 90 100 87
"""
可以看到pivot算是unstack的一个很好的替代品,但是unstack的灵活性要更高一些,当然啦,两种解决方式都要掌握。
处理第二种数据(一行生成多行)
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典,钉宫理惠
1 布洛妮娅·扎伊切克 8月18日 TetraCalyx,Hanser,阿澄佳奈,花泽香菜
2 德丽莎·阿波卡利斯 3月28日 花玲,田村由香里
"""
df = df.set_index(["姓名", "生日"])["声优"].str.split(",", expand=True)
.stack().reset_index(drop=True, level=-1).reset_index().rename(columns={0: "声优"})
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典
1 琪亚娜·卡斯兰娜 12月7日 钉宫理惠
2 布洛妮娅·扎伊切克 8月18日 TetraCalyx
3 布洛妮娅·扎伊切克 8月18日 Hanser
4 布洛妮娅·扎伊切克 8月18日 阿澄佳奈
5 布洛妮娅·扎伊切克 8月18日 花泽香菜
6 德丽莎·阿波卡利斯 3月28日 花玲
7 德丽莎·阿波卡利斯 3月28日 田村由香里
"""
估计可能有人会懵,我们来一步一步拆解,不过我们需要介绍一下DataFrame的stack方法。
首先Series只有unstack,没有stack。而DataFrame既有unstack,又有stack。Series(具有二级索引)的unstack是将自身变成一个DataFrame,而DataFrame的unstack和stack则是将自身变成一个具有二级索引(前提是该DataFrame的索引和列都只有一级)的Series。
我们上面说了,在默认情况下,对于Series来讲,调用其unstack方法,会默认将一级索引变成DataFrame的索引,二级索引变成DataFrame的列(当然可以通过level来控制)。但是调用DataFrame的unstack则是将自身的索引变成对应Series的二级索引,将自身的列变成对应Series的一级索引;调用DataFrame的stack,则是将自身的索引变成对应Series的一级索引,将自身的列变成对应Series的二级索引。
文字读起来绕的话,可以看一张图,在默认情况下如图所示:
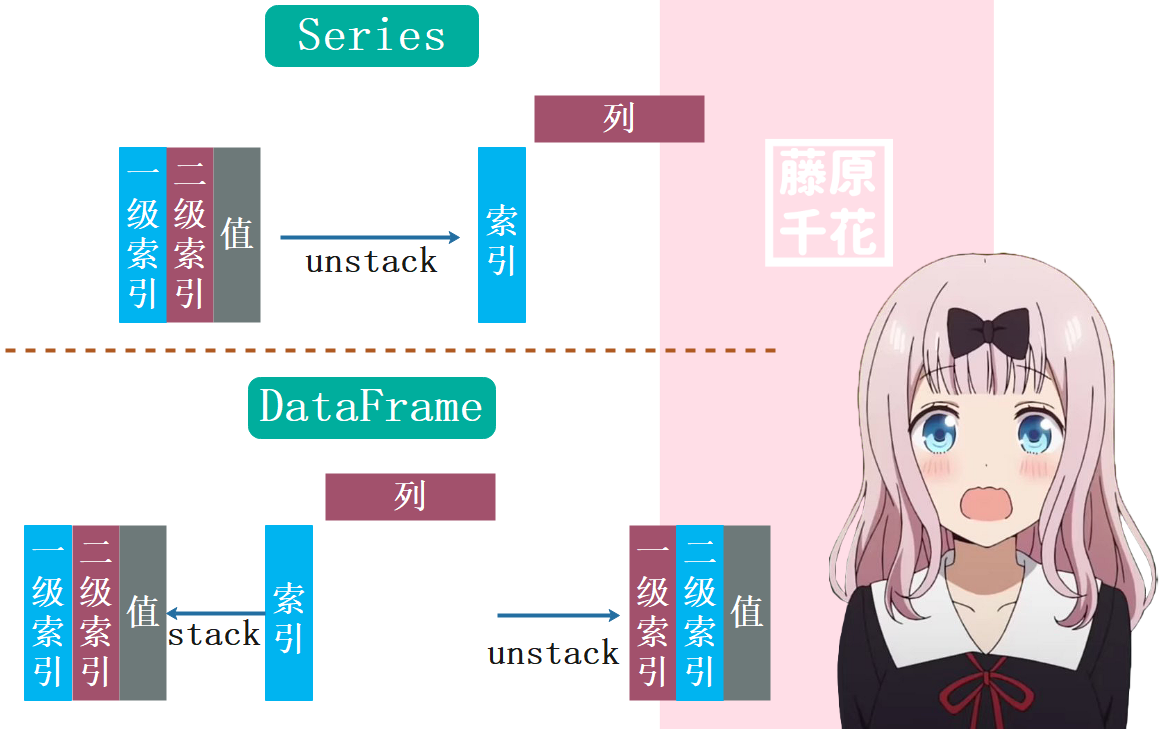
下面我们就来分析之前的那一大长串。
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典,钉宫理惠
1 布洛妮娅·扎伊切克 8月18日 TetraCalyx,Hanser,阿澄佳奈,花泽香菜
2 德丽莎·阿波卡利斯 3月28日 花玲,田村由香里
"""
# 我们是对"声优"这个字段进行分解, 那么将除了该字段之外其它字段设置为索引
df = df.set_index(["姓名", "生日"])
# 此时的df只有"声优"这一列, 原来的"姓名"和"生日"被设置成了索引
print(df)
"""
声优
姓名 生日
琪亚娜·卡斯兰娜 12月7日 陶典,钉宫理惠
布洛妮娅·扎伊切克 8月18日 TetraCalyx,Hanser,阿澄佳奈,花泽香菜
德丽莎·阿波卡利斯 3月28日 花玲,田村由香里
"""
# 筛选出"声优"这个字段, 此时得到的是一个具有二级索引的Series
# 索引的名字叫做: "姓名" 和 "生日"
s = df["声优"]
print(s)
"""
姓名 生日
琪亚娜·卡斯兰娜 12月7日 陶典,钉宫理惠
布洛妮娅·扎伊切克 8月18日 TetraCalyx,Hanser,阿澄佳奈,花泽香菜
德丽莎·阿波卡利斯 3月28日 花玲,田村由香里
Name: 声优, dtype: object
"""
# 然后对这个字段进行分解, 我这里设置的是以逗号为分隔符
# 具体是以什么分隔, 以你自己的数据为准
# 显然这里得到的是一个具有二级索引的DataFrame
df = s.str.split(",", expand=True)
# split之后, 字段名使用0 1 2 3..., 默认以最长为基准, 长度不够的使用None填充
print(df)
"""
0 1 2 3
姓名 生日
琪亚娜·卡斯兰娜 12月7日 陶典 钉宫理惠 None None
布洛妮娅·扎伊切克 8月18日 TetraCalyx Hanser 阿澄佳奈 花泽香菜
德丽莎·阿波卡利斯 3月28日 花玲 田村由香里 None None
"""
# 调用stack方法, 按照之前说的, 会变成一个Series
# 其索引就是DataFrame的索引加上列变成的索引, 由于DataFrame的索引有两级, 显然此时得到的是一个具有三级索引的Series
# 不过也可以把DataFrame的索引当成一个整体看成是Series的一级索引, 然后列变成对应的二级索引
s = df.stack()
# 此时的数据好像有那么回事了, 另外我们发现在stack的时候自动将None给过滤掉了, 这也是我们希望的结果
print(s)
"""
姓名 生日
琪亚娜·卡斯兰娜 12月7日 0 陶典
1 钉宫理惠
布洛妮娅·扎伊切克 8月18日 0 TetraCalyx
1 Hanser
2 阿澄佳奈
3 花泽香菜
德丽莎·阿波卡利斯 3月28日 0 花玲
1 田村由香里
dtype: object
"""
# 然后调用reset_index, 但是我们发现由于索引有三级,那么reset_index之后就会使得0 1 0 1 2...这些也变成了一列
# 可以reset_index之后手动drop掉, 但是我们也可以直接删掉
s = s.reset_index(drop=True, level=-1)
# 于是我们指定drop=True, 但是这样会把所有索引都删掉, 因此还要指定level=-1, 这样只会删除最后一级索引
print(s)
"""
姓名 生日
琪亚娜·卡斯兰娜 12月7日 陶典
12月7日 钉宫理惠
布洛妮娅·扎伊切克 8月18日 TetraCalyx
8月18日 Hanser
8月18日 阿澄佳奈
8月18日 花泽香菜
德丽莎·阿波卡利斯 3月28日 花玲
3月28日 田村由香里
dtype: object
"""
# 但是我们发现,上面的reset_index(drop=True, level=-1)并没有把前面的索引变成列
# 这是因为我们指定了level,如果不指定level,那么drop=True会把所有的索引都删掉
# 但指定了level只会删除对应级别的索引,而不会同时对前面的索引进行reset,于是需要再调用一次reset_index,此时就什么也不需要指定了
df = s.reset_index()
# 会自动进行笛卡尔乘积
print(df)
"""
姓名 生日 0
0 琪亚娜·卡斯兰娜 12月7日 陶典
1 琪亚娜·卡斯兰娜 12月7日 钉宫理惠
2 布洛妮娅·扎伊切克 8月18日 TetraCalyx
3 布洛妮娅·扎伊切克 8月18日 Hanser
4 布洛妮娅·扎伊切克 8月18日 阿澄佳奈
5 布洛妮娅·扎伊切克 8月18日 花泽香菜
6 德丽莎·阿波卡利斯 3月28日 花玲
7 德丽莎·阿波卡利斯 3月28日 田村由香里
"""
# 但是我们发现列名,是自动生成的0,于是再进行rename
df = df.rename(columns={0: "声优"})
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典
1 琪亚娜·卡斯兰娜 12月7日 钉宫理惠
2 布洛妮娅·扎伊切克 8月18日 TetraCalyx
3 布洛妮娅·扎伊切克 8月18日 Hanser
4 布洛妮娅·扎伊切克 8月18日 阿澄佳奈
5 布洛妮娅·扎伊切克 8月18日 花泽香菜
6 德丽莎·阿波卡利斯 3月28日 花玲
7 德丽莎·阿波卡利斯 3月28日 田村由香里
"""
# 此时就大功告成啦
在pandas0.25版本的时候, DataFrame中新增了一个explode方法, 专门用来将一行变多行。
如果你用过hive的话,那么explode你肯定会很熟悉,是专门用来对一个数组进行"炸裂"的。只不过hive中的explode在对字段进行炸裂的时候不可以有其它的字段,如果在炸裂的同时还能和其它字段进行笛卡尔积,那么还需要加上一个"侧写"的语法。但是pandas中explode是可以直接对DataFrame进行使用的,我们来看一下:
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典,钉宫理惠
1 布洛妮娅·扎伊切克 8月18日 TetraCalyx,Hanser,阿澄佳奈,花泽香菜
2 德丽莎·阿波卡利斯 3月28日 花玲,田村由香里
"""
# 此时不需要指定expand=True了, 这里我们需要的是一个列表
df["声优"] = df["声优"].str.split(",")
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 [陶典, 钉宫理惠]
1 布洛妮娅·扎伊切克 8月18日 [TetraCalyx, Hanser, 阿澄佳奈, 花泽香菜]
2 德丽莎·阿波卡利斯 3月28日 [花玲, 田村由香里]
"""
# 对该字段进行炸裂
df = df.explode("声优")
print(df)
"""
姓名 生日 声优
0 琪亚娜·卡斯兰娜 12月7日 陶典
0 琪亚娜·卡斯兰娜 12月7日 钉宫理惠
1 布洛妮娅·扎伊切克 8月18日 TetraCalyx
1 布洛妮娅·扎伊切克 8月18日 Hanser
1 布洛妮娅·扎伊切克 8月18日 阿澄佳奈
1 布洛妮娅·扎伊切克 8月18日 花泽香菜
2 德丽莎·阿波卡利斯 3月28日 花玲
2 德丽莎·阿波卡利斯 3月28日 田村由香里
"""
# 我们看到直接就把这个字段给炸开了, 并且炸开的同时会自动和其它字段进行笛卡尔积, 也就是自动匹配
所以explode这个功能真的是好用,而且这种数据也工作中也是非常常见的。
让我当时感到困惑的数据就是上面那两种,但是其实还有几种数据也是非常常见、并且不好处理的,而pandas同样提供了高效的解决办法。
根据字典拆分成多列
数据如下:
id info
001 {'姓名': '琪亚娜·卡斯兰娜', '生日': '12月7日', '外号': '草履虫'}
002 {'姓名': '布洛妮娅·扎伊切克', '生日': '8月18日', '外号': '板鸭'}
003 {'姓名': '德丽莎·阿波卡利斯', '生日': '3月28日', '外号': '德丽傻', "武器": "犹大的誓约"}
我们需要变成下面这种形式:
id 姓名 生日 外号 武器
001 琪亚娜·卡斯兰娜 12月7日 草履虫 None
002 布洛妮娅·扎伊切克 8月18日 板鸭 None
003 德丽莎·阿波卡利斯 3月28日 德丽傻 犹大的誓约
在pandas中,我们知道apply算是一个比较慢的操作,如果可以使用向量化的操作的话,就不要使用apply。但是对于当前这个例子来说,则非常适合apply。
import pandas as pd
df = pd.DataFrame({"id": ["001", "002", "003"],
"info": [{"姓名": "琪亚娜·卡斯兰娜", "生日": "12月7日", "外号": "草履虫"},
{"姓名": "布洛妮娅·扎伊切克", "生日": "8月18日", "外号": "板鸭"},
{"姓名": "德丽莎·阿波卡利斯", "生日": "3月28日", "外号": "德丽傻", "武器": "犹大的誓约"}]
})
# 筛选出"info"这一列, 然后使用apply, 里面是一个pd.Series
tmp = df["info"].apply(pd.Series)
# 打印一看, 神奇的事情发生了, 直接就变成了我们想要的结果
print(tmp)
"""
姓名 生日 外号 武器
0 琪亚娜·卡斯兰娜 12月7日 草履虫 NaN
1 布洛妮娅·扎伊切克 8月18日 板鸭 NaN
2 德丽莎·阿波卡利斯 3月28日 德丽傻 犹大的誓约
"""
# 因为我们这里的值是一个字典, 而Series接收一个字典的话, 那么字典的key就是索引, value就是值
# 在扩展成DataFrame的时候同样会考虑到字典中所有的key, 有多少个不重复的key就会生成多少个列
# 如果该行没有对应的值则使用NaN填充
# 然后就简单了, 将tmp添加到df中
df[tmp.columns] = tmp
# 然后删掉"info"这一列
df = df.drop(columns=["info"])
print(df)
"""
id 姓名 生日 外号 武器
0 001 琪亚娜·卡斯兰娜 12月7日 草履虫 NaN
1 002 布洛妮娅·扎伊切克 8月18日 板鸭 NaN
2 003 德丽莎·阿波卡利斯 3月28日 德丽傻 犹大的誓约
"""
所以我们看到,只需要对info这一列使用apply(pd.Series),即可将字典变成多个字段,列名就是字典的key,如果不存在,那么值就用NaN填充。
注意:使用apply(pd.Series)的时候,对应的列里面的值必须是一个字典,不能是字典格式的字符串。
很多时候我们的数据从对方的接口、或者对方的数据库中获取的,某个字段只是长得像字典,但其实并不是,只是一个类似于json的字符串罢了。这个时候就不可以直接使用apply了。
举个栗子:
import pandas as pd
df = pd.DataFrame({"id": ["001", "002", "003"],
"info": [str({"姓名": "琪亚娜·卡斯兰娜", "生日": "12月7日"}),
str({"姓名": "布洛妮娅·扎伊切克", "生日": "8月18日"}),
str({"姓名": "德丽莎·阿波卡利斯", "生日": "3月28日"})]
})
# 显然"info"字段的所有值都是一个字符串
tmp = df["info"].apply(pd.Series)
print(tmp)
"""
0
0 {'姓名': '琪亚娜·卡斯兰娜', '生日': '12月7日'}
1 {'姓名': '布洛妮娅·扎伊切克', '生日': '8月18日'}
2 {'姓名': '德丽莎·阿波卡利斯', '生日': '3月28日'}
"""
# 我们看到此时再对info字段使用apply(pd.Series)得到的就不是我们希望的结果了, 因为它不是一个字典
# 这个时候, 我们可以eval一下, 将其变成一个字典
tmp = df["info"].map(eval).apply(pd.Series)
print(tmp)
"""
姓名 生日
0 琪亚娜·卡斯兰娜 12月7日
1 布洛妮娅·扎伊切克 8月18日
2 德丽莎·阿波卡利斯 3月28日
"""
# 此时就完成啦
不过在生产环境中还会有一个问题,我们知道Python中的eval是将一个字符串里面的内容当成值,或者你理解为就是把字符串周围的引号给剥掉。比如说:
a = "123", 那么eval(a)得到的就是整型123a = "[1, 2, 3]", 那么eval(a)得到的就是列表[1, 2, 3]a = "{'a': 1, 'b': 'xxx'}", 那么eval(a)得到的就是字典{'a': 1, 'b': 'xxx'}a = "name", 那么eval(a)得到的就是变量name指向的值, 而如果不存在name这个变量, 则会抛出一个NameErrora = "'name'", 那么eval(a)得到的就是'name'这个字符串; 同理a = '"name"', 那么eval(a)得到的依旧是'name'这个字符串
可能有人好奇我为什么要说这些呢?是因为我在工作中经常要从对方的接口中获取数据,而由于编程语言的不同,导致空值和布尔值之间的表示方式不一样。
举个栗子:
import pandas as pd
df = pd.DataFrame({"id": ["001", "002", "003"],
"info": ['{"result": "TH", "is_ok": true}',
'{"result": null, "is_ok": false}',
'{"result": "CL", "is_ok": true}']
})
print(df)
"""
id info
0 001 {"result": "TH", "is_ok": true}
1 002 {"result": null, "is_ok": false}
2 003 {"result": "CL", "is_ok": true}
"""
# 就笔者所在公司而言, 对方公司基本上使用的都是java语言
# 所以返回的值如果包含空值或者布尔值的话, 那么结果是null, true, false
# 显然这不符合Python中的语法, 一旦eval, 那么就是几个没有定义的变量罢了
try:
df["info"] = df["info"].map(eval)
except Exception as e:
print(e) # name 'true' is not defined
# 显然在对第一个字符串进行eval的时候就报错了
# 所以这个时候我们需要将null换成None、true换成True、false换成False
# 但是某个值里面也可能恰好包含null、true或者false, 所以它们的前面和后面不可以是w
df["info"] = df["info"].str.replace(r"(?i)(?<!w)null(?!w)", "None").str.
replace(r"(?i)(?<!w)true(?!w)", "True").str.replace(r"(?i)(?<!w)false(?!w)", "False")
print(df)
"""
id info
0 001 {"result": "TH", "is_ok": True}
1 002 {"result": None, "is_ok": False}
2 003 {"result": "CL", "is_ok": True}
"""
# 替换成功, 下面进行eval
df["info"] = df["info"].map(eval)
print(type(df.loc[0, "info"])) # <class 'dict'>
# 我们看到此时得到的是一个字典类型, 之后的做法就和之前一样啦, 不再赘述了
然而当时我遇到的数据没有这么简单,它不光是字典格式的字符串,而是一个字符串格式的数组,数组里面是多个字典。如果你认真看完上面的内容,估计你已经猜到需求和解决方法了,直接先"炸裂",再apply(pd.Series)即可。
import pandas as pd
df = pd.DataFrame({"id": ["001", "002", "003"],
"info": [
'[{"result": "TH", "is_ok": true}, {"result": "TH", "is_ok": true}]',
'[{"result": null, "is_ok": false}]',
'[{"result": "CL", "is_ok": true}, {"result": "WH", "is_ok": true}]'
]
})
print(df)
"""
id info
0 001 [{"result": "TH", "is_ok": true}, {"result": "TH", "is_ok": true}]
1 002 [{"result": null, "is_ok": false}]
2 003 [{"result": "CL", "is_ok": true}, {"result": "WH", "is_ok": true}]
"""
# 替换
df["info"] = df["info"].str.replace(r"(?i)(?<!w)null(?!w)", "None").str.
replace(r"(?i)(?<!w)true(?!w)", "True").str.replace(r"(?i)(?<!w)false(?!w)", "False")
# 此时info字段中的值都还是字符串
print(df)
"""
id info
0 001 [{"result": "TH", "is_ok": True}, {"result": "TH", "is_ok": True}]
1 002 [{"result": None, "is_ok": False}]
2 003 [{"result": "CL", "is_ok": True}, {"result": "WH", "is_ok": True}]
"""
# eval
df["info"] = df["info"].map(eval)
# 虽然打印出来的结果没有什么变化, 但是字段的值变成了list类型
print(df)
"""
id info
0 001 [{"result": "TH", "is_ok": True}, {"result": "TH", "is_ok": True}]
1 002 [{"result": None, "is_ok": False}]
2 003 [{"result": "CL", "is_ok": True}, {"result": "WH", "is_ok": True}]
"""
# 炸裂, 如果值是一个字符串、整型等标量的话, 那么炸裂得到的结果还是其本身
# 我们需要对列表、元组等容器进行炸裂, 将其内部的元组一个一个的全部炸出来
df = df.explode("info")
print(df)
"""
id info
0 001 {'result': 'TH', 'is_ok': True}
0 001 {'result': 'TH', 'is_ok': True}
1 002 {'result': None, 'is_ok': False}
2 003 {'result': 'CL', 'is_ok': True}
2 003 {'result': 'WH', 'is_ok': True}
"""
# apply(pd.Series)
tmp = df["info"].apply(pd.Series)
df[tmp.columns] = tmp
# drop info
df = df.drop(columns=["info"])
print(df)
"""
id result is_ok
0 001 TH True
0 001 TH True
1 002 None False
2 003 CL True
2 003 WH True
"""
总的来说,pandas在处理这种数据时的表现是非常优秀的。
列转行
最后我们来看一看列转行,列转行可以简单地认为是将数据库中的宽表变成一张高表;而之前介绍的行转列则是把一张高表变成一张宽表。
数据如下:
姓名 水果 星期一 星期二 星期三
古明地觉 草莓 70斤 72斤 60斤
雾雨魔理沙 樱桃 61斤 60斤 81斤
琪露诺 西瓜 103斤 116斤 153斤
我们希望变成下面这种形式
姓名 水果 日期 销量
古明地觉 草莓 星期一 70斤
雾雨魔理沙 樱桃 星期一 61斤
琪露诺 西瓜 星期一 103斤
古明地觉 草莓 星期二 72斤
雾雨魔理沙 樱桃 星期二 60斤
琪露诺 西瓜 星期二 116斤
古明地觉 草莓 星期三 60斤
雾雨魔理沙 樱桃 星期三 81斤
琪露诺 西瓜 星期三 153斤
当然我们这里字段比较少,如果把星期一到星期日全部都写上去有点太长了。不过从这里我们也能看出前者对应的是一张宽表,就是字段非常多,我们要将其转换成一张高表。
pandas提供了一个模块级的函数:melt,可以方便地实现这一点。
import pandas as pd
df = pd.DataFrame({"姓名": ["古明地觉", "雾雨魔理沙", "琪露诺"],
"水果": ["草莓", "樱桃", "西瓜"],
"星期一": ["70斤", "61斤", "103斤"],
"星期二": ["72斤", "60斤", "116斤"],
"星期三": ["60斤", "81斤", "153斤"],
})
print(df)
"""
姓名 水果 星期一 星期二 星期三
古明地觉 草莓 70斤 72斤 60斤
雾雨魔理沙 樱桃 61斤 60斤 81斤
琪露诺 西瓜 103斤 116斤 153斤
"""
print(pd.melt(df, id_vars=["姓名", "水果"], value_vars=["星期一", "星期二", "星期三"]))
"""
姓名 水果 variable value
古明地觉 草莓 星期一 70斤
雾雨魔理沙 樱桃 星期一 61斤
琪露诺 西瓜 星期一 103斤
古明地觉 草莓 星期二 72斤
雾雨魔理沙 樱桃 星期二 60斤
琪露诺 西瓜 星期二 116斤
古明地觉 草莓 星期三 60斤
雾雨魔理沙 樱桃 星期三 81斤
琪露诺 西瓜 星期三 153斤
"""
# 但是默认起得字段名叫做variable和value, 我们可以在结果的基础之上手动rename, 也可以直接在参数中指定
print(pd.melt(df, id_vars=["姓名", "水果"],
value_vars=["星期一", "星期二", "星期三"],
var_name="星期几?",
value_name="销量"))
"""
姓名 水果 星期几? 销量
古明地觉 草莓 星期一 70斤
雾雨魔理沙 樱桃 星期一 61斤
琪露诺 西瓜 星期一 103斤
古明地觉 草莓 星期二 72斤
雾雨魔理沙 樱桃 星期二 60斤
琪露诺 西瓜 星期二 116斤
古明地觉 草莓 星期三 60斤
雾雨魔理沙 樱桃 星期三 81斤
琪露诺 西瓜 星期三 153斤
"""
我们看到实现起来非常方便,转换之后列变少了、行变多了,这个过程就是所谓的列转行;而反过来行变少了、列变多了则叫做行转列。那么这里的melt是如何变换的呢?示意图如下:
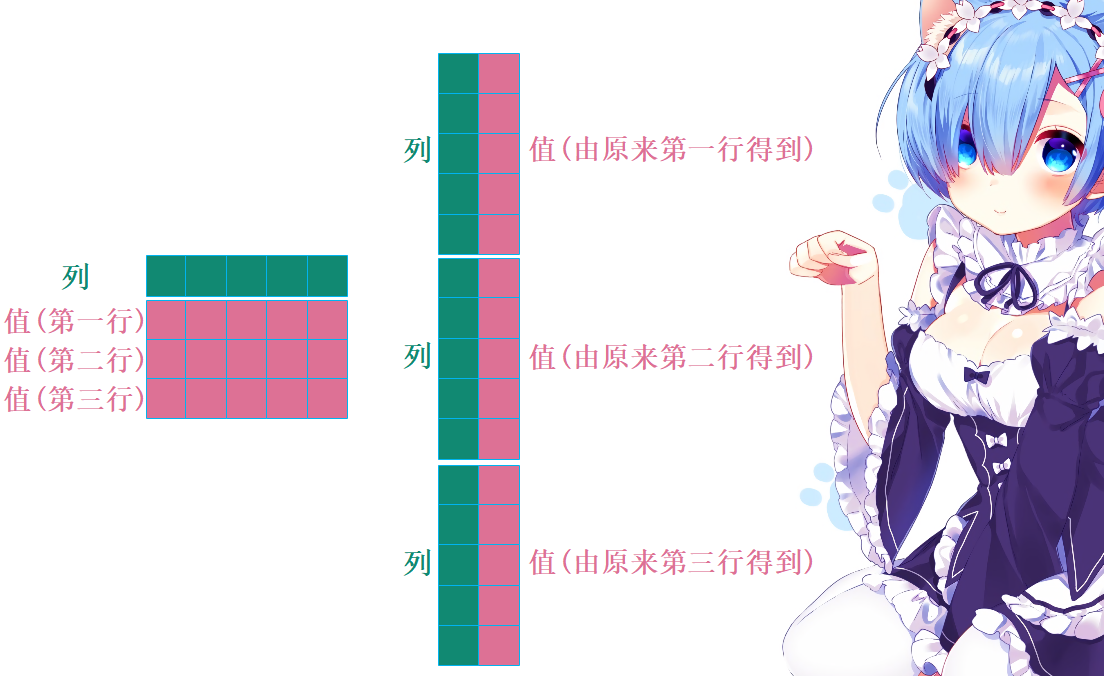
如果还有其它字段的话,那么和explode一样,会自动进行匹配,一一对应。
所以我们可以介绍一下melt里面的几个参数了:
frame: 第一个参数, 接收一个DataFrame, 这没有什么好说的id_vars: 第二个参数, 不需要进行列转行的字段, 比如这里的"姓名"和"水果", 在列转行之后会自动进行匹配value_vars: 第三个参数, 需要进行列转行的字段var_name: 第四个参数, 我们说列转行之后会生成两个列, 第一个列存储的值是"列转行之前的列的列名",第二个列存储的值是"列转行之前的列的值"。但是生成的两个列重要有列名吧,所以var_name就是生成的第一个列的列名value_name: 生成的第二个列的列名col_level: 针对于具有二级列名的DataFrame, 这个一般可以不用管
另外,我们指定列的时候也可以指定一部分的列,比如:
import pandas as pd
df = pd.DataFrame({"姓名": ["古明地觉", "雾雨魔理沙", "琪露诺"],
"水果": ["草莓", "樱桃", "西瓜"],
"星期一": ["70斤", "61斤", "103斤"],
"星期二": ["72斤", "60斤", "116斤"],
"星期三": ["60斤", "81斤", "153斤"],
})
print(df)
"""
姓名 水果 星期一 星期二 星期三
古明地觉 草莓 70斤 72斤 60斤
雾雨魔理沙 樱桃 61斤 60斤 81斤
琪露诺 西瓜 103斤 116斤 153斤
"""
# id_vars只指定"水果"
print(pd.melt(df, id_vars=["水果"],
value_vars=["星期一", "星期二"],
var_name="日期",
value_name="销量"))
"""
水果 日期 销量
0 草莓 星期一 70斤
1 樱桃 星期一 61斤
2 西瓜 星期一 103斤
3 草莓 星期二 72斤
4 樱桃 星期二 60斤
5 西瓜 星期二 116斤
"""
# 也可以指定字段顺序, 比如: "水果"在前, "姓名"在后
print(pd.melt(df, id_vars=["水果", "姓名"],
value_vars=["星期一", "星期二"],
var_name="日期",
value_name="销量"))
"""
水果 姓名 日期 销量
0 草莓 古明地觉 星期一 70斤
1 樱桃 雾雨魔理沙 星期一 61斤
2 西瓜 琪露诺 星期一 103斤
3 草莓 古明地觉 星期二 72斤
4 樱桃 雾雨魔理沙 星期二 60斤
5 西瓜 琪露诺 星期二 116斤
"""
如果要进行"列转行"的列比较多的话,可以只指定id_vars,那么默认将剩余的所有列作为value_vars。
import pandas as pd
df = pd.DataFrame({"姓名": ["古明地觉", "雾雨魔理沙", "琪露诺"],
"水果": ["草莓", "樱桃", "西瓜"],
"星期一": ["70斤", "61斤", "103斤"],
"星期二": ["72斤", "60斤", "116斤"],
"星期三": ["60斤", "81斤", "153斤"],
})
print(df)
"""
姓名 水果 星期一 星期二 星期三
古明地觉 草莓 70斤 72斤 60斤
雾雨魔理沙 樱桃 61斤 60斤 81斤
琪露诺 西瓜 103斤 116斤 153斤
"""
# 默认将除了"姓名"、"水果"之外所有列都进行列转行了
print(pd.melt(df, id_vars=["水果", "姓名"],
var_name="日期",
value_name="销量"))
"""
姓名 水果 日期 销量
古明地觉 草莓 星期一 70斤
雾雨魔理沙 樱桃 星期一 61斤
琪露诺 西瓜 星期一 103斤
古明地觉 草莓 星期二 72斤
雾雨魔理沙 樱桃 星期二 60斤
琪露诺 西瓜 星期二 116斤
古明地觉 草莓 星期三 60斤
雾雨魔理沙 樱桃 星期三 81斤
琪露诺 西瓜 星期三 153斤
"""
# 但是注意: 在value_vars省略的时候, 则需要仔细考虑一下id_vars
# 什么意思呢?看个栗子
print(pd.melt(df, id_vars=["水果"],
var_name="日期",
value_name="销量"))
# 我们看到它将"姓名"这一列也进行列转行了, 但是显然我们不想这么做
# 但是在省略value_vars的时候, 会将除了id_vars指定的字段之外的其它所有字段都进行列转行
# 所以在省略value_vars的时候, 务必注意id_vars, 假设这里要列传行的列很多, 不想一个一个写, 但是id_vars又不想指定"姓名"
# 那么可以在列转行之前就将"姓名"这一列删掉即可, 也就是把上面的df换成df.drop(columns=["姓名"])即可
"""
水果 日期 销量
0 草莓 姓名 古明地觉
1 樱桃 姓名 雾雨魔理沙
2 西瓜 姓名 琪露诺
3 草莓 星期一 70斤
4 樱桃 星期一 61斤
5 西瓜 星期一 103斤
6 草莓 星期二 72斤
7 樱桃 星期二 60斤
8 西瓜 星期二 116斤
9 草莓 星期三 60斤
10 樱桃 星期三 81斤
11 西瓜 星期三 153斤
"""
# 此时就没有任何问题了
print(pd.melt(df.drop(columns=["姓名"]),
id_vars=["水果"],
var_name="日期",
value_name="销量"))
"""
水果 日期 销量
0 草莓 星期一 70斤
1 樱桃 星期一 61斤
2 西瓜 星期一 103斤
3 草莓 星期二 72斤
4 樱桃 星期二 60斤
5 西瓜 星期二 116斤
6 草莓 星期三 60斤
7 樱桃 星期三 81斤
8 西瓜 星期三 153斤
"""
事实上,列转行除了使用melt,还可以使用我们之前说的stack,只不过melt会更加的方便。那这样,我们就来使用stack来模拟一下melt吧。
import pandas as pd
def my_melt(frame: pd.DataFrame,
id_vars: list,
value_vars: list,
var_name: str,
value_name: str):
# 先将id_vars和value_vars指定的字段筛选出来
frame = frame[id_vars + value_vars]
# 将id_vars指定的字段设置为索引
frame = frame.set_index(id_vars)
print(">>>筛选字段、设置索引之后对应的DataFrame:
", frame)
# 调用frame的stack方法, 会得到一个具有多级索引的Series
# frame的列就是生成的Series的最后一级索引
s = frame.stack()
print(">>>得到的具有多级索引的Series:
", s)
# 直接对该Series进行reset_index即可, 会得到DataFrame, 将索引变成列
frame = s.reset_index()
print(">>>具有多级索引的Series执行reset_index:
", frame)
# 重命名
frame.columns = id_vars + [var_name, value_name]
print(">>>最终返回的DataFrame:")
return frame
df = pd.DataFrame({"姓名": ["古明地觉", "雾雨魔理沙", "琪露诺"],
"水果": ["草莓", "樱桃", "西瓜"],
"星期一": ["70斤", "61斤", "103斤"],
"星期二": ["72斤", "60斤", "116斤"],
"星期三": ["60斤", "81斤", "153斤"],
})
print(df)
"""
姓名 水果 星期一 星期二 星期三
古明地觉 草莓 70斤 72斤 60斤
雾雨魔理沙 樱桃 61斤 60斤 81斤
琪露诺 西瓜 103斤 116斤 153斤
"""
print(my_melt(df, id_vars=["姓名", "水果"],
value_vars=["星期一", "星期二"],
var_name="日期", value_name="销量"))
"""
>>>筛选字段、设置索引之后对应的DataFrame:
星期一 星期二
姓名 水果
古明地觉 草莓 70斤 72斤
雾雨魔理沙 樱桃 61斤 60斤
琪露诺 西瓜 103斤 116斤
>>>得到的具有多级索引的Series:
姓名 水果
古明地觉 草莓 星期一 70斤
星期二 72斤
雾雨魔理沙 樱桃 星期一 61斤
星期二 60斤
琪露诺 西瓜 星期一 103斤
星期二 116斤
dtype: object
>>>具有多级索引的Series执行reset_index:
姓名 水果 level_2 0
0 古明地觉 草莓 星期一 70斤
1 古明地觉 草莓 星期二 72斤
2 雾雨魔理沙 樱桃 星期一 61斤
3 雾雨魔理沙 樱桃 星期二 60斤
4 琪露诺 西瓜 星期一 103斤
5 琪露诺 西瓜 星期二 116斤
>>>最终返回的DataFrame:
姓名 水果 日期 销量
0 古明地觉 草莓 星期一 70斤
1 古明地觉 草莓 星期二 72斤
2 雾雨魔理沙 樱桃 星期一 61斤
3 雾雨魔理沙 樱桃 星期二 60斤
4 琪露诺 西瓜 星期一 103斤
5 琪露诺 西瓜 星期二 116斤
"""
此时我们就通过stack自己实现了pandas中的melt,对比内置的melt函数实现的结果,我们发现顺序有些差异,但显然结果是一样的。
小结
以上就是一些经常会遇见,但是不熟悉的话处理起来又会感到麻烦的几种数据以及需求,再来总结一下:
行转列:1. 设置索引、筛选单个字段,得到一个二级的Series。2. 调用Series的unstack,得到一个DataFrame。3. rename_axis。4. reset_index。另外我们说还有一个pd.pivot可以让我们直接跳转到上面的第三步一行生成多行:1. 如果该列里面的元素不是列表,那么变成列表。2. 调用explode对该字段进行炸裂。根据字典拆分成多列:1. 如果该列里面的元素不是字典,那么变成字典。2. 调用.apply(pd.Series)。一行生成多行和根据字典拆分成多列也可以结合起来,先explode,再apply列转行:通过melt一步搞定。或者使用stack
因此针对行转列和列转行,早期我个人经常使用unstack和stack。但是之后就没怎么用了,因为pivot和melt算是unstack和stack的一个很好的替代品,可以帮助我们更快地实现。另外,除了行转列和列转行之外,关于展开列表实现一行生成多行、将字典变成多个字段,pandas也依旧提供了很棒的支持。