(一)什么是梯度下降法
梯度下降法
和之前介绍的k近邻算法和线性回归法不同,梯度下降法不是一个机器学习算法。它既不能解决分类问题也不能解决回归问题,那梯度下降是什么呢?以及它的作用又是什么呢?
其实,梯度下降法是一种基于搜索的最优化方法。
作用就是最小化一个损失函数,或者最大化一个效用函数,当然最大化一个效用函数就不是梯度下降了,而是梯度上升,但是本质都是一样的。
为什么会有梯度下降
我们在线性回归中,我们可以求出最小化一个函数所对应的参数的解。但是后面我们会看到,很多算法我们是没办法直接求到解的。那么基于这样的模型,我们就需要使用搜索的策略,来找到这个最优解。那么梯度下降法就是在机器学习领域,最小化损失函数的一个最常用的方法。
图解梯度下降

图中描述了损失函数J和参数θ之间的变化关系,图像上每一个点都会对应一个切线,或者说是导数。由于我们这里是一维的,所以就用导数来描述了,如果是多维的,那么就要对每一个维度上进行求导,组合起来就叫做梯度。
我们发现当蓝色的点在左边的时候,那么随着θ的减小,J对应的取值就会变大。θ增大,J对应的取值就会减少。而我们的目的,是希望找到一个合适的θ,使得J能取到最小值。首先我们要知道,梯度(这里是导数)代表方向,代表J增大的方向,所以我们要沿着梯度的反方向(所以才叫梯度下降啊,如果是梯度上升,那么这里的函数就是效用函数),才能找到一个最小值。所以我们需要一个η,让此刻的θ减去η*dJ/dθ,比如η可以取0.1,那么此刻蓝色的点会往右走,然后继续重复,发现此刻的导数依旧不为零,继续重复,直到导数为零,或者说直到不能再下降为止。同理这个蓝色的点如果在右边也是一样,在左边的话,导数是负值,而η是正值,然后乘上此刻的导数得到的是一个负值,用theta去减,显然最终结果会增大,在导数为负值的情况下,θ值增大的话,显然对应着J的减小。在右边的话,导数是一个正值,η*dJ/dθ是一个正值,θ去减的话,显然值会减小,在导数为正的情况下,导数值减小,显然也对应着J的减小。因此不管导数为正为负,这个式子都是成立的。

想象一个山谷,就好似小球滚到谷底一样。不管小球在山谷的哪一侧,最终都会滚到谷底。当小球滚到谷底的时候,我们就说找到了一个最好的参数θ。
所以梯度就是J增大的方向,而我们要想要得到一个最小值,那么显然就要沿着梯度的反方向,这就是梯度下降。
那么小球滚落是不是有速度的呢?这个滚落的速度、或者说梯度下降下降的速度由谁来决定呢?就是由η来决定的。
η
- η称为学习率
- η的取值影响获得最优解的速度
- η取值不合适的话,甚至得不到最优解
- η是梯度下降法的一个超参数
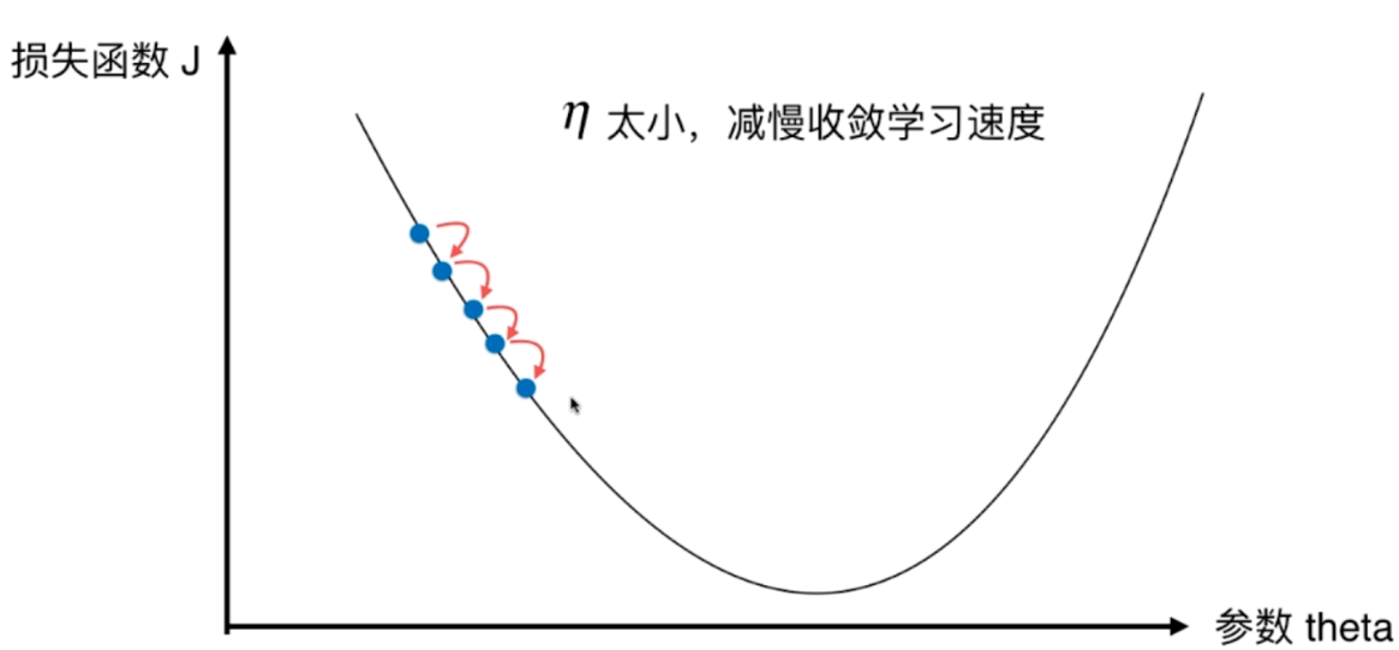
怎么理解呢?如果η取值越大,那么小球是不是越滚越快呢?越快的话,获取最终的参数θ的速度是不是也越快呢?
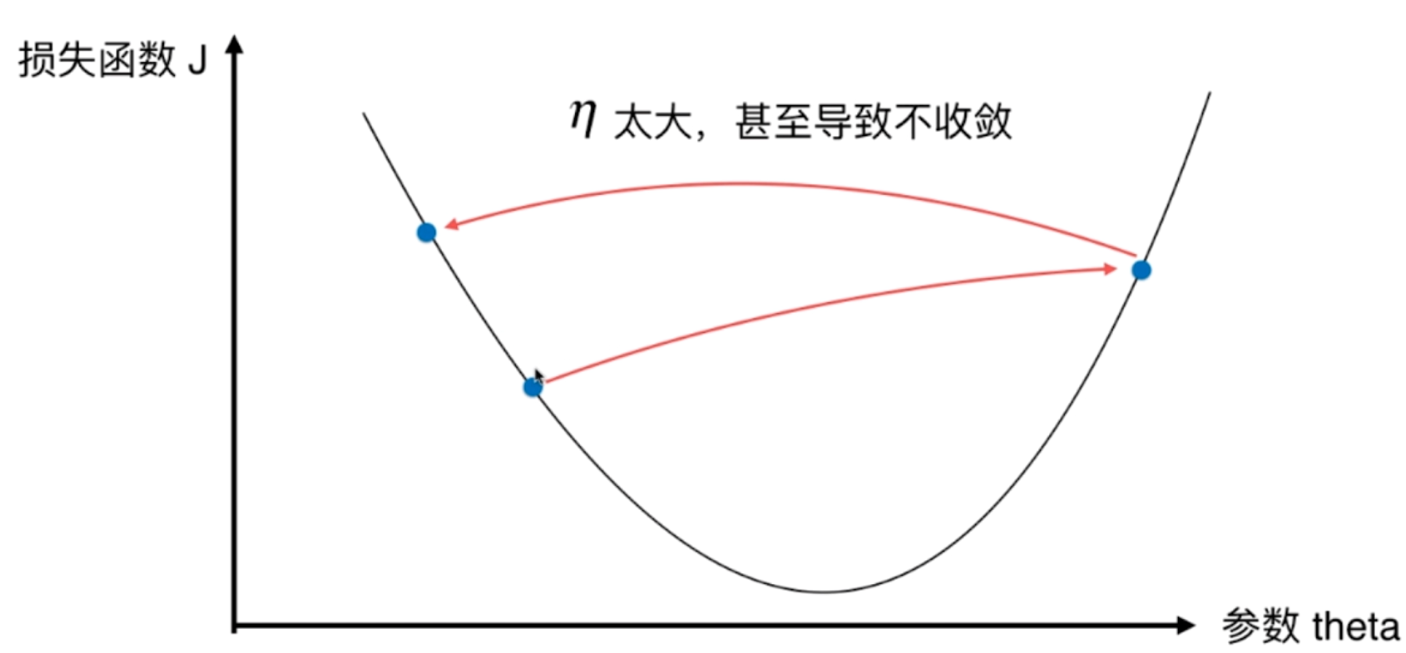
但是如果过快的话,从左边滚来下的时候,是不是可能又会滚到右边去呢?
比如我们一开始的导数为-8,我们要找到导数为0或者接近0的点。经过连续的下降我们已经快接近0了,假设此时为θ1,可如果η过大的话,再一相减,导数可能就大于0了,而且增大的程度也比较严重,假设此时为θ2。这说明在θ1和θ2之间,可能存在一个更好的θ,使得导数(不管正负),和0之间的差距会更小。换句话说,就是在θ1的时候,如果此时能下降的小一些、或者下降的慢一些就好了,因此我们会想到把η取小一些不就好啦,这样下降的速度不就慢啦,每一次下降的距离不就小啦,在θ1的时候就不会一下子跑到θ2的位置上啦。但是η是一个超参数,是在一开始就决定好的,不可能在优化的时候改变它,要避免这种情况,我们只能在一开始的时候把η的取值变得小一些。可是如果η过小的话,就意味着一点一点的下降,最终肯定会找到一个合适的θ,但是这样造成的代价就是优化的速度会很慢。
因此我们在优化的时候,是需要做一个平衡,从而找到合适的η。
注意事项
我们上面只是一个简单的二次函数,但是真实情况中,函数并不只有唯一一个极值点,或者说导数为0的点不止一个。

我们一开始的点在右边,然后梯度下降的话,会往左边走,走着走着,走到了导数为0的点。但是呢,这只是一个局部最优解,下面还有一个导数为0的点,对应的损失函数J更小,这个解叫做全局最优解。
因此我们使用梯度下降,这种搜索的策略所带来的问题。就是说,我们只是找到了一个我们看起来一个最好的解而已,但它并不是在全局层面上最好的解。
那么如何解决这个问题呢?
- 多次运行,随机化初始点
- 梯度下降的初始点也是一个超参数
我们可以很容易想到,随机化初始点的话,那么如果初始点在右边,那么会滑到一个局部最优解,如果在左边呢?那么就会滑到一个全局最优解。因此多次运行、随机化初始点,通过对获得的最优解进行比较,可以找到一个更好的位置。因此初始点也是一个超参数。
我们一直在说,最小化一个损失函数。我们在线性回归中,好像也是在最小化一个损失函数诶。是的,本质上是类似的,如果把用梯度下降带到线性回归里面的话,也是完全可以解释的通的。而线性回归貌似没有什么起始点的概念,确实没有,因为线性回归法的损失函数只有一个极值点,换句话说,只有一个最优解,当然也就是全局最优解。
(二)模拟实现梯度下降法。
代码演示
我们来生成数据集,绘制出图像
import numpy as np
import matplotlib.pyplot as plt
# 从-1到6,分割200份
plot_x = np.linspace(-1, 6, 200)
plot_y = plot_x ** 2 - plot_x * 5 - 1
plt.plot(plot_x, plot_y)
plt.show()
图像大致如上,我们下面就通过传入x求出此时的导数,当然这里的x我们用θ表示
# 这里函数我们用dJ表示,参数用θ表示,意思是函数J和θ之间的关系
def dJ(theta):
# 那么下面就求导了
# 如何求导呢?我们可以手动计算,但是numpy给我提供了方法
# np.poly1d([a, b, c]) --> a * x**2 + b * x + c
p = np.poly1d([1, -5, -1]) # 此时的p就相当于 1 * x**2 - 5*x - 1,调用p(3)就等于3**2 - 5*3 - 1 = -7
d = p.deriv() # 调用p.deriv(),求出导数
return d(theta) # 返回此时的导数,或者直接手动求导代入theta也是一样,这里主要为了顺便介绍一下numpy如何求导
# 除了返回此时theta对应的导数,还要计算其对应的值
def J(theta):
return theta ** 2 - 5 * theta - 1
# 下面就开始梯度下降了
eta = 0.1 # 学习率我们设置为0.1
theta = 0.0 # theta我们就设置成0.0
epsilon = 1e-8
"""
这个epsilon是什么?首先我们由于学习率的问题,不一定能找到dJ(theta)恰好等于0的点
而且由于计算机浮点数的误差,也很难精确到0,但是我们可以定一个容忍边界。
我们可以观察一下曲线,我们发现越到导数为0的地方,曲线越平滑
说明此时损失函数降低的越不明显,如果某一次损失函数下降的值与上一次的值之差没有超过我们这里限定的epsilon
那么我们就认为这里就是导数接近于0的点
"""
while True:
gradient = dJ(theta) # 计算此时的导数值,或者说是梯度
last_theta = theta # 用last_theta来保存上一次的theta
theta = theta - eta * gradient # 梯度下降,求出下一次对应的θ值
# 这一次和上一次之间函数值的差值小于epsilon的话,我们就找到了对应的θ
if abs(J(theta) - J(last_theta)) < epsilon:
break
print(gradient) # -0.00027222589353748106
print(theta) # 2.499891109642585
"""
这个值是不是很符合呢?梯度确实接近于0
theta接近2.5,我们对应的函数是x ** 2 - x * 5 - 1
这是开口向上的二次函数,什么时候有最小值呢?当x(也就是这里的theta)等于 -b / 2a 的时候
"""
观测theta的变化细节
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plot_x = np.linspace(-1, 6, 200)
plot_y = plot_x ** 2 - plot_x * 5 - 1
def dJ(theta):
p = np.poly1d([1, -5, -1])
d = p.deriv()
return d(theta)
def J(theta):
return theta ** 2 - 5 * theta - 1
eta = 0.1
theta = 0.0
epsilon = 1e-8
# 我们将每一次的eta保存起来
theta_history = [eta]
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
# 将新的theta添加进去
# 代码其他的没有变化
theta_history.append(theta)
if (abs(theta) - abs(last_theta)) < epsilon:
break
plt.plot(plot_x, plot_y)
plt.plot(np.array(theta_history), J(np.array(theta_history)), color="r", marker="+")
plt.show()

可以看到,由于一开始梯度比较陡,我们每一次下降的程度会比较大,但是随着曲线变得平滑,我们下降的速度或者说下降的距离也越来越小,到达梯度为0的地方,基本上就不下降了,当小于给定的临界值,我们就说找到了最优解(假设当前只有一个最优价的前提下)
print(len(theta_history)) # 82
我们总共下降了81次,求出了最好的theta值
我们将以上的代码进行封装,探究不同的eta,对梯度下降的影响
import numpy as np
import matplotlib.pyplot as plt
def dJ(theta):
p = np.poly1d([1, -5, -1])
d = p.deriv()
return d(theta)
def J(theta):
return theta ** 2 - 5 * theta - 1
# 用户传入初始的theta和eta,epsilon默认为1e-8
def gradient_descent(initial_theta, eta, epsilon=1e-8):
theta = initial_theta
theta_history = [theta]
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if (abs(J(theta) - J(last_theta))) < epsilon:
break
return theta_history
def plot_theta_history(theta_history):
plot_x = np.linspace(-1, 6, 200)
plot_y = plot_x ** 2 - plot_x * 5 - 1
plt.plot(plot_x, plot_y)
plt.plot(np.array(theta_history), J(np.array(theta_history)), color="r", marker="+")
plt.show()
# 我们将学习率设置的低一些
eta = 0.01
theta = 0.
theta_history = gradient_descent(theta, eta)
plot_theta_history(theta_history)
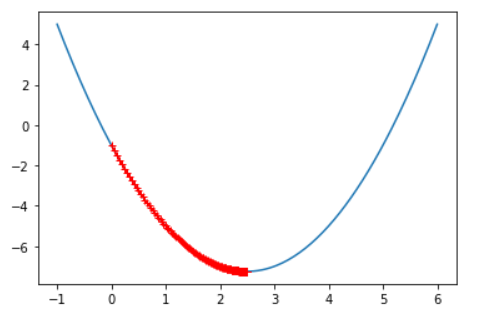
可以看到之间的点变得密了,因为我们的学习率变低了,每一次下降的慢了
print(len(theta_history)) # 424
这一次我们总共下降了423次,最优解
eta = 0.001
theta = 0.
theta_history = gradient_descent(theta, eta)
plot_theta_history(theta_history)
print(len(theta_history)) # 3682
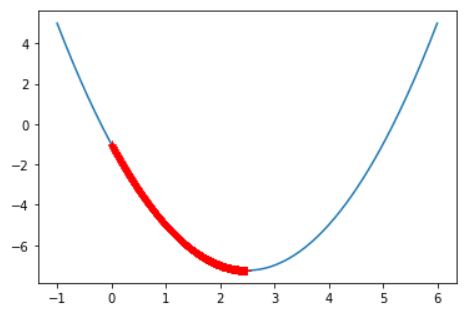
当我们把eta下降的再低一些,变成0.001,可以看到,我们设置marker为+,已经密集到都连在了一起,变成一条粗线,而此时我们下降的3681次
这是eta取值较小的情况,如果eta取值较大呢?
eta = 0.8
theta = 0.
theta_history = gradient_descent(theta, eta)
plot_theta_history(theta_history)

可以看到,第一次下降就直接下降到右边去了。不过好在eta还是不算太大,使得我们整体还是减小了的,这样来来回回还是找到了使得函数值最小的位置

如果eta超过了1,可以看到解释器要抛出OverflowError了,不过我这内存比较大,暂时还没有报错。从这我们可以看出,每一次都会从一边跳到另一边,在我们eta取0.8的时候,虽然也是左右两边来回跳,但是函数值是减小的,但是当eta去1.1,函数值是增大的,最终会越来越大,直到内存溢出。
我们把代码修改一下,而且实际上我们的代码有一步是有问题的,如果当两个值为无穷大的时候,那么两者相减得到是一个NaN,意思是not a number,所以(abs(J(theta) - J(last_theta)))这行代码是有局限性的,但这并不意味着我们就要将它删掉,事实上我们可以增加一个条件,梯度下降的次数,如果下降的次数超过了我们设定的阈值,那么就不再下降了。
import numpy as np
import matplotlib.pyplot as plt
def dJ(theta):
p = np.poly1d([1, -5, -1])
d = p.deriv()
return d(theta)
def J(theta):
return theta ** 2 - 5 * theta - 1
def gradient_descent(initial_theta, eta, iter_counts=1e4, epsilon=1e-8):
theta = initial_theta
theta_history = [theta]
n_counts = 1
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
# 增加一个判断条件
if (abs(J(theta) - J(last_theta))) < epsilon or n_counts > iter_counts:
break
n_counts += 1
return theta_history
def plot_theta_history(theta_history):
plot_x = np.linspace(-1, 6, 200)
plot_y = plot_x ** 2 - plot_x * 5 - 1
plt.plot(plot_x, plot_y)
plt.plot(np.array(theta_history), J(np.array(theta_history)), color="r", marker="+")
plt.show()
theta_history = gradient_descent(theta, eta)
print(len(theta_history)) # 10002
print(theta_history[-1]) # nan
可以看到最后一次theta已经是无穷大了,not a number,我们只下降6次,我们来看看theta是怎么变化的
eta = 1.1
theta = 0.
theta_history = gradient_descent(theta, eta, iter_counts=10)
plot_theta_history(theta_history)
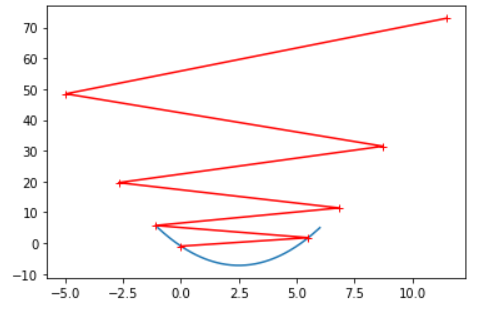
这个红色的线一直往外蹦,换句话说,函数的值越来越大,因此可以看出,此时eta的值就太大了
因此可能有人就想了,eta取值为0.8的时候还没事,取1.1就有事了,那么1是不是eta的一个极限值呢?
其实不要有这种想法,eta取值为多少是跟我们的损失函数,是根损失函数在该点的导数值是相关的,而不是说有一个固定的标准,也正因为如此,我们说eta是一个超参数,有时候我们会进行网格搜索,来寻找一个较好的eta值。
不过eta一般取值为0.01是一个最保险的结果,尽管下降的会很慢。
因此如果出现了异常,或者一直跑不出来结果,可以绘制一下theta_history,看看是不是学习过大造成的影响。
(三)线性回归中的梯度下降法
之前我们的theta只是一个值,但是实际上theta和我们的线性回归一样,每一个点实际上是有多个分量的。如果只有一个分量的话,那么我们之前称之为导数,但如果是多个分量的话,多个分量所对应的导数组合起来的向量就叫做梯度,因此梯度就是对每一个分量求偏导,然后组合起来。

即使对于多维,我们之前推理的梯度下降的方式仍然是成立的。
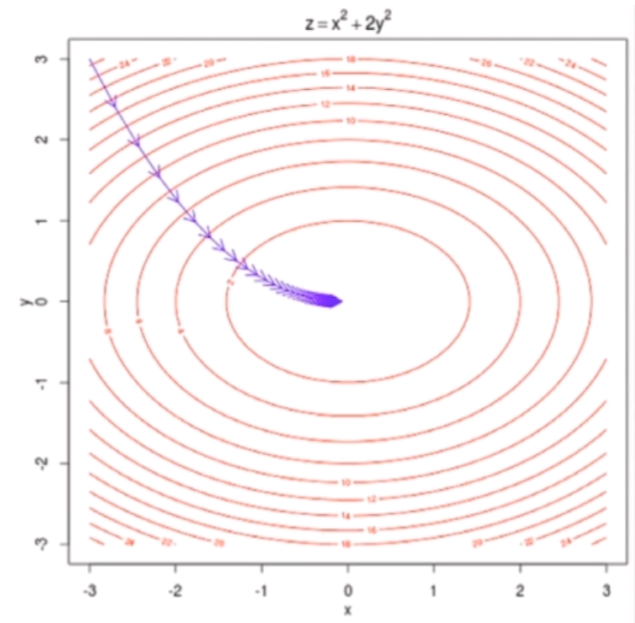
这是一个椭圆的图像,我们使用梯度下降依旧是成立的,只不过下降的方式有多种,但是我们沿着梯度下降的速度是最快的。
我们来看看线性回归中使用梯度下降

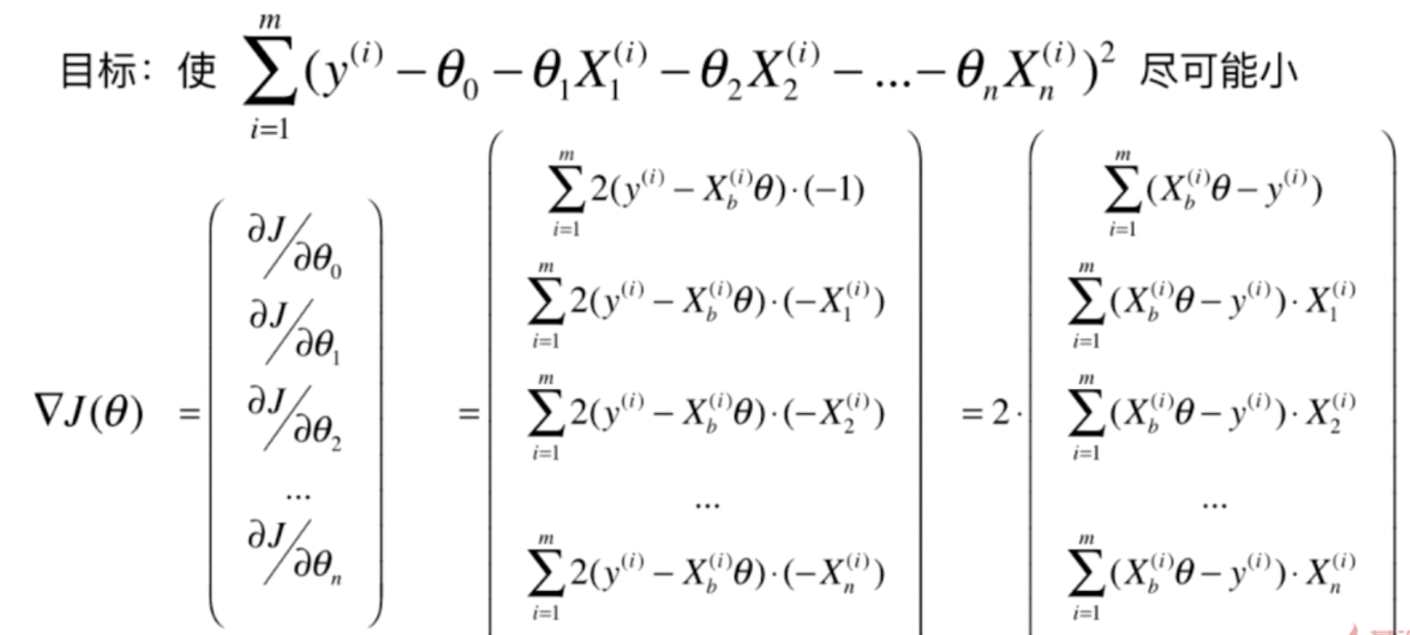
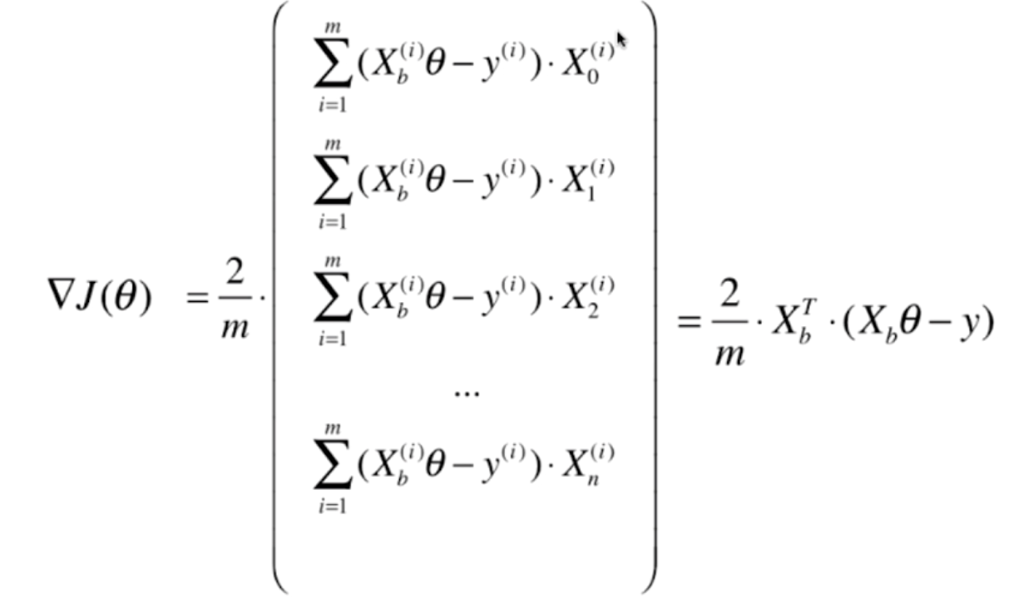
我们对每一个分量进行求导,注意,此时θ是未知量,所有的X都是常数。如果熟悉线性回归的话,可以发现,这里Xb实际上是(1, X1, X2......,Xn),θ是(θ0, θ1, θ2,......θn)·T
但是我们发现,实际上我们的结果是和m有关的,样本的数量越大,那么梯度的每一个分量对应的值就越大,这显然是不合理的。我们希望求出来的梯度当中的每一个分量和m是无关的。因此我们可以对每一个分量除以m

所以我们的线性回归损失函数实际上可以写成这样

实际上就是y和ŷ的均方误差,但是有时候呢?我们除的不是m而是2m,则是因为在求导的时候,那么平方会产生一个2,所以为了计算方便,我们除的是2m,但是不管除的是多少,除的总归是一个常数,对于我们优化是没有影响的。

(四)实现线性回归中的梯度下降法
看一下数据集
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(666)
x = 2 * np.random.random(size=100)
y = x * 3. + 4. + np.random.normal(size=100)
plt.scatter(x, y)
plt.show()
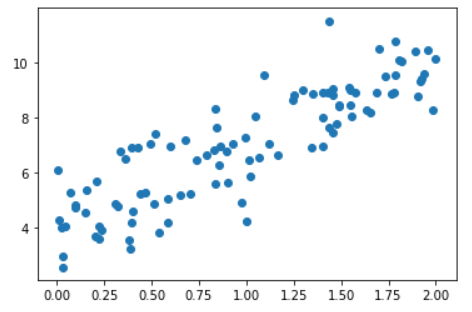
下面我们就使用梯度下降法来训练我们的模型,还记得模型长什么样子吗?

import numpy as np
import matplotlib.pyplot as plt
# 函数接收向量theta,X_b,和真实值y
def J(theta, X_b, y):
return np.sum((y - X_b @ theta) ** 2) / len(X_b)
def dJ(theta, X_b, y):
# 我们创建一个列表,用于存放梯度的每一个分量
res = np.zeros(len(theta))
# 我们看到第一个分量很好求
res[0] = np.sum(X_b @ theta - y)
# 而剩余的n项,我们注意到只是右边多了一个X,表示所有样本的第n个维度
# 因此可以用一个笨一点的方法,使用for循环
for i in range(1, len(theta)):
res[i] = (X_b @ theta - y) @ X_b[:, i]
return res * 2 / len(X_b)
def gradient_descent(X_b, y, initial_theta, eta, epsilon=1e-8, iter_counts=1e4):
theta = initial_theta
i_iter = 0
while i_iter < iter_counts:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y))) < epsilon:
break
i_iter += 1
return theta
np.random.seed(666)
x = 2 * np.random.random(size=100)
y = x * 3. + 4. + np.random.normal(size=100)
# reshape一下,变成高维的
X = x.reshape((-1, 1))
X_b = np.c_[np.ones(len(X)), X]
initial_theta = np.zeros(X_b.shape[1])
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta, epsilon=1e-8)
print(theta) # array([4.02145786, 3.00706277])
# 得到的theta[0]是截距,theta[1]是斜率,说明梯度下降成功的训练出了我们的模型
(五)梯度下降的向量化和数据标准化
梯度下降的向量化
我们进行向量化,实际上主要是针对以下式子
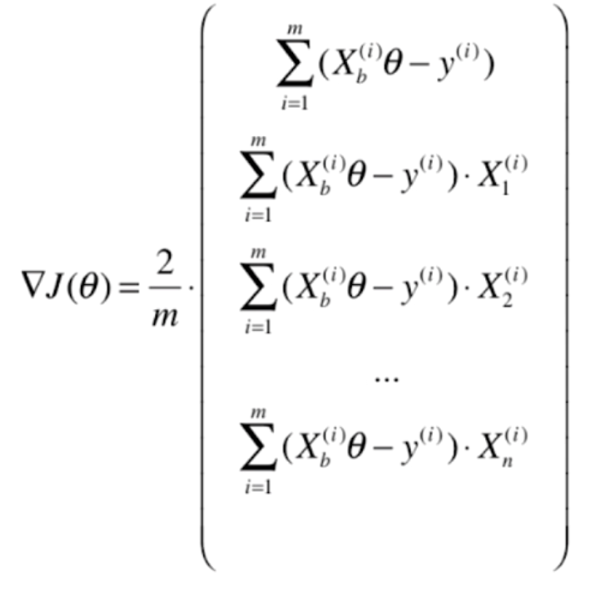
我们之前是使用for循环的方式,一个一个计算的,但是我们发现这些式子的规律很一致,那么可不可以使用矩阵的方式来进行运算呢?显然是可以的
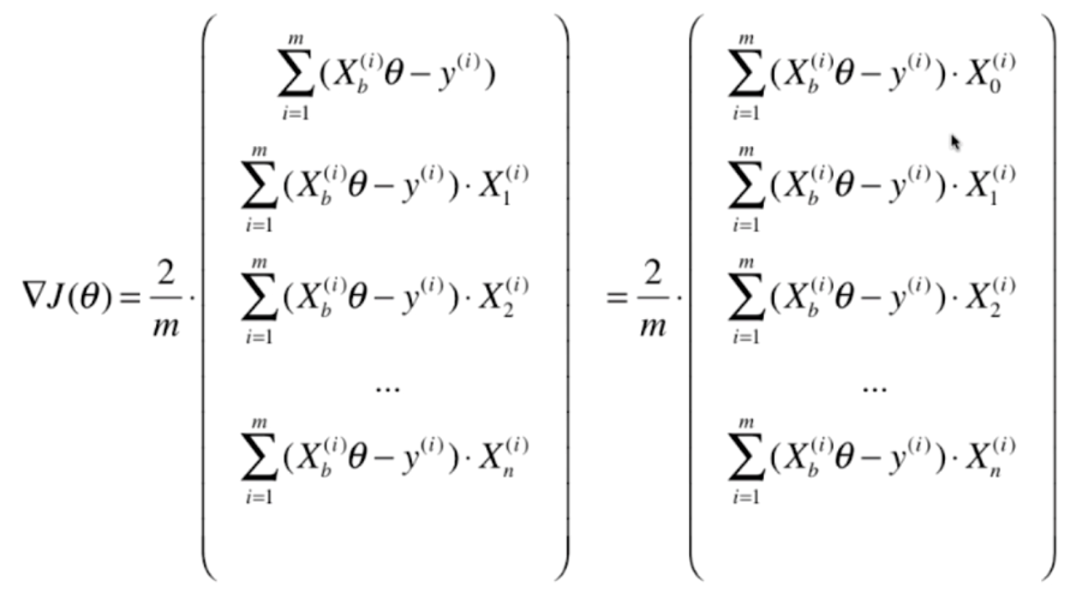
为了保持一致,我们给第一项乘上一个X0,相当于是每一个样本的第0个特征,这里显然是恒等于1的。那么我们接下来的任务就是对右边的式子进行矩阵变换
然后右边的式子可以根据·拆成两部分,然后进行点乘

但是这样得到的结果是一个1Xn的行向量,但是我们的theta是一个nX1的列向量,尽管在numpy中不区分行向量和列向量,但是为了严谨,我们还是在得到的结果上再进行一次转置。
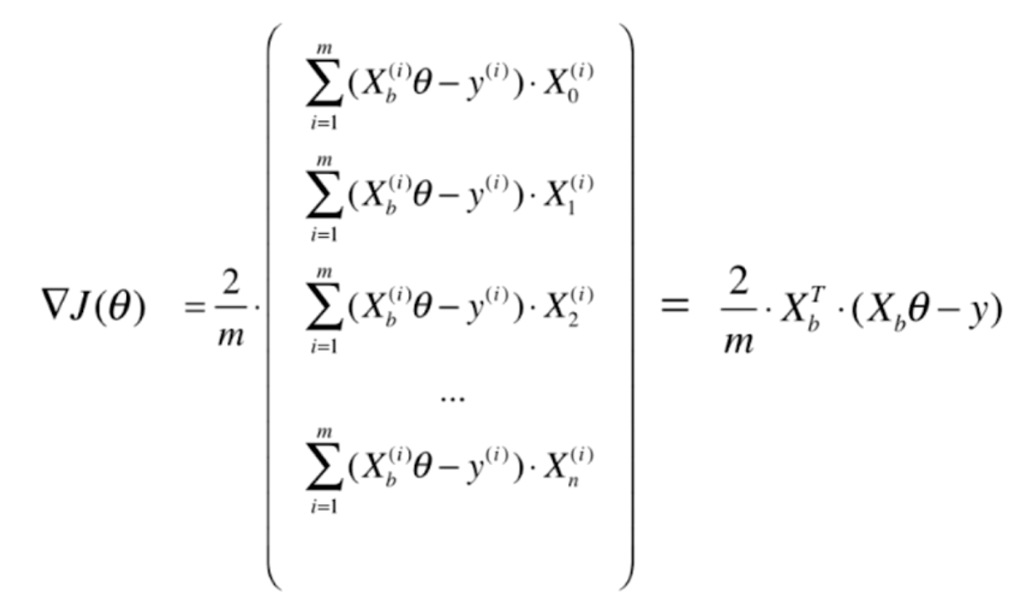
因此我们之前求得一大串式子,最终可以简化成这样一行式子
那么我们可以对之前的程序进行一下优化
import numpy as np
import matplotlib.pyplot as plt
def J(theta, X_b, y):
return np.sum((y - X_b @ theta) ** 2) / len(X_b)
def dJ(theta, X_b, y):
# 修改的只有这一处
return X_b.T @ (X_b @ theta - y) * 2. / len(y)
def gradient_descent(X_b, y, initial_theta, eta, epsilon=1e-8, iter_counts=1e4):
theta = initial_theta
i_iter = 0
while i_iter < iter_counts:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y))) < epsilon:
break
i_iter += 1
return theta
np.random.seed(666)
x = 2 * np.random.random(size=100)
y = x * 3. + 4. + np.random.normal(size=100)
X = x.reshape((-1, 1))
X_b = np.c_[np.ones(len(X)), X]
initial_theta = np.zeros(X_b.shape[1])
eta = 0.01
theta = gradient_descent(X_b, y, initial_theta, eta, epsilon=1e-8)
print(theta) # array([4.02145786, 3.00706277])
# 对比之前的结果,得到是一模一样的
数据归一化
在使用梯度下降前,要进行数据归一化。因为和正规方程解不同,梯度下降是基于搜索的方式,如果多个特征的维度的量纲不同,那么eta再与之相乘,得到的结果肯定是不准确的。

(六)随机梯度下降法
我们之前的梯度下降做的事情是将函数在某一个theta所对应的梯度值准确的求出来
但是我们发现,每一项都要对所有的样本进行计算,这样的梯度下降法又叫做批量梯度下降法(batch gradient descent),也就是说,每次计算都要将样本中所有的信息批量进行计算。
但是这样就带来了一个问题,那就是如果我们的样本量非常大,那么计算梯度本身也是非常耗时的。
那么基于这个问题,有没有什么改进的方案呢?首先我们可以想一下,我们对梯度的分量进行计算的时候,每次都要取所有的样本,然后再除以样本的总数。那么我们可不可以每次只取一个样本呢?

可以看到,我们将求和给去掉了,那么就意味着我们的i每次只取一个值,得到的就是这个结果
并且可以看到,此时的结果已经不再是一个梯度了,可以理解为梯度的一个分量,我们沿着这个分量的方向前进,是不是也能得到整个损失函数的最小值呢?这个思想的实现思路,就叫做随机梯度下降法
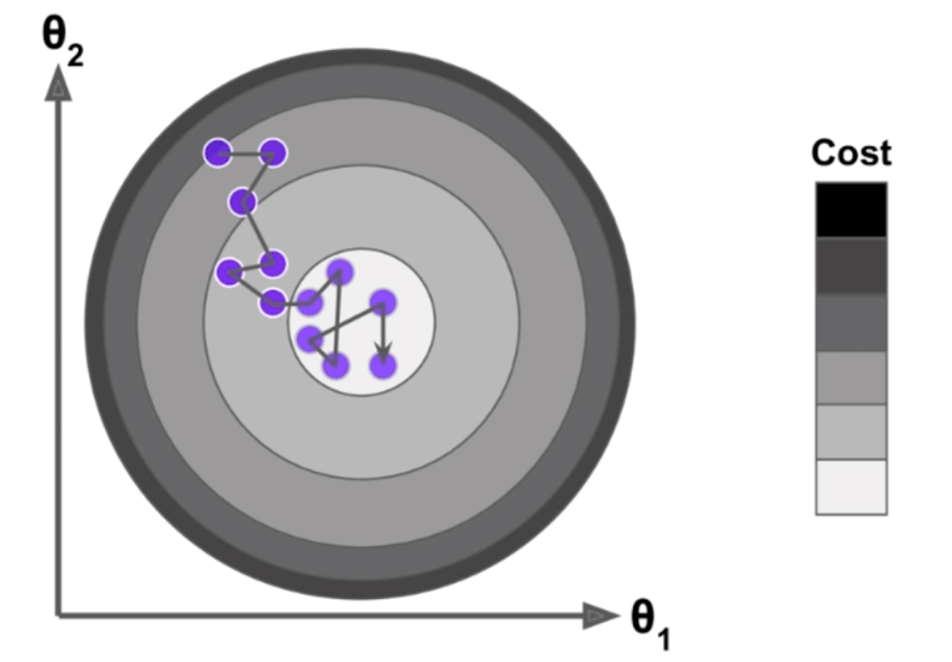
可以看到随机梯度下降并不像批量梯度下降一样,每一次都沿着最快的方向下降,而且随机梯度下降有可能还会上升,毕竟是随机的,具有一定的不可预知性。但是实验结论告诉我们,即便如此,我们使用随机梯度下降依然可以来到使损失函数达到最小值的附近。虽然不会像批量梯度下降那样,一定会找到最小值,但是当我们的样本数比较大的时候,我们是愿意牺牲一些精度来换取事件。由于eta这个学习率是固定的,有可能我们在某一次学习中已经来到了使得函数达到最小值的附近,但是由于随机梯度的不确定性,再下一次又偏离了,因此我们可以设计一个函数,使得eta在随着梯度的下降、或者迭代的次数逐渐递减。
因此我们可以使用导数,让eta等于迭代次数的倒数。但是呢这样会产生一个问题,那就是当迭代次数较少的时候,eta变化的太快了,因此我们可以让迭代次数加上一个常数b,但是当迭代次数很多的时候,eta变化的很慢,所以分子再乘上一个常数a,于是就变成了如下
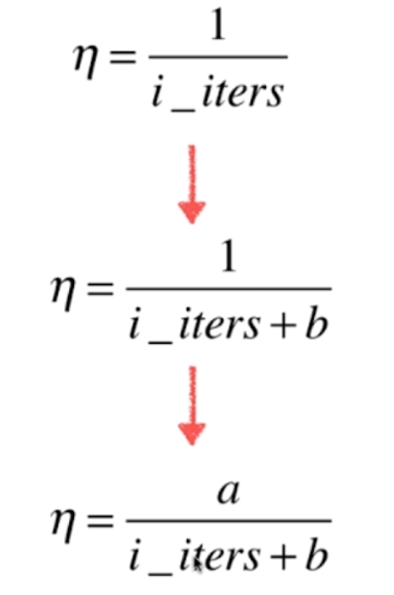
因此a和b可以看成是两个超参数,那么对于当前我们不深入a和b的取值,我们直接使用一个业界比较常用的值,a取5,b取50。另外值得一提的是,我们这种eta取值的形式,是模拟"退火"的思想。因为比如炼钢,是需要用火炼的,但是火的温度是逐渐递减的,至于怎么递减,是和时间有关的。因此a和b我们有时候也叫作t0和t1

(七)sklearn中的随机梯度下降法
from sklearn.linear_model import SGDRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
"""
大家可以看到,这个SGDRegressor是在linear_model这个模块下的
意味着sklearn里面的梯度下降只能解决线性问题
"""
boston = load_boston()
X = boston.data
y = boston.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
s = StandardScaler()
s.fit(X_train)
sgd = SGDRegressor()
sgd.fit(s.transform(X_train), y_train)
print(sgd.score(s.transform(X_test), y_test)) # 0.768187019748826
(八)有关梯度下降法的更多深入讨论
我们介绍了两种梯度下降法,一种是批量梯度下降法,一种是随机梯度下降法。批量梯度下降每一次都要使用全部的样本,比较耗费时间,但是优点是每一次训练都能沿着梯度下降最快的方向前进。随机梯度下降是每次只选择一个特征,虽然计算比较快,但是下降却不是最快的,甚至有可能向反方向前进。我们可以综合这二者的优缺点,也就是小批量梯度下降法。

什么是小批量梯度下降法呢?就是每次不看全部的样本的这么多,也不看只有一个样本这么少,而是看k个样本。所以这个k也是个超参数,很多机器算法中,都采取了这种结合的方式。
我们还介绍到了随机,随机不仅仅是运算速度快,在复杂的模型中还有一个重要的意义。
- 跳出局部最优解
- 更快的运行速度
- 并且机器学习领域很多算法都要使用随机的特点:比如,随机森林。