rabbitmq是一款消息队列。
首先什么是消息,消息是指在应用间传送的数据。消息可以是简单的字符串, 也可以是一些复杂的对象。
消息队列则是应用间进行通信的一种方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
可以类比一下,python中的队列,也是为了不同线程之间进行数据共享,但是rabbitmq这款消息队列要远比python中的队列强大的多。
因此消息队列可以看成是应用之间的异步协助机制,至于为什么需要消息队列,可以想象在流量高峰时期,我们不可能临时增加服务器。但是又想支撑这么大的流量,因此可以使用消息队列将操作进行异步执行,比如用户下单成功发送短信,那么我们没必要非等到短信发送成功结束流程,而是把发送短信这条消息放在队列中,由另外的线程从消息队列中去取消息,然后执行发送短信的业务逻辑。

这是一个普通也是最简单但也是效果最不好的执行流程
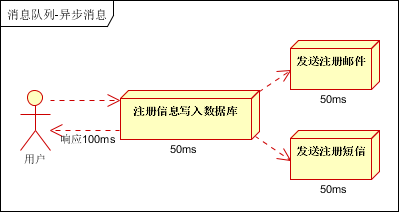
发送邮件和短信变成异步的了,效果有提升,但仍然不是最优的办法
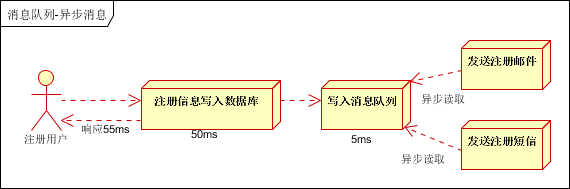
这种效果是最好的,因为发送短信和邮件不是必须的业务逻辑。我们可以写入一个消息队列,那么另外的线程去获取消息然后执行,可以大大的提升效率。
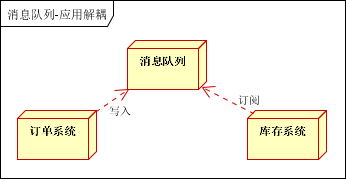
再比如库存系统,如果高峰时期,那么会有大量的请求访问库存系统,这样压力会很大,那么我们就可以将消息写入消息队列,直接返回用户下单成功。然后库存系统在获取消息队列里面的消息,进行下单操作。
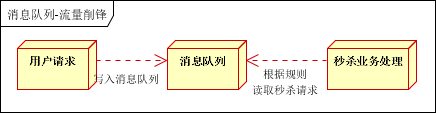
以及专门用来处理日志的kafka也是同样的道理
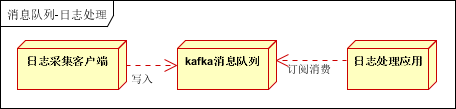
日志采集客户端,负责日志数据采集,定时写入Kafka队列
Kafka消息队列,负责日志数据的接收,存储和转发
日志处理应用:订阅并消费kafka队列中的日志数据
看一张架构图来理解rabbitmq的基本原理
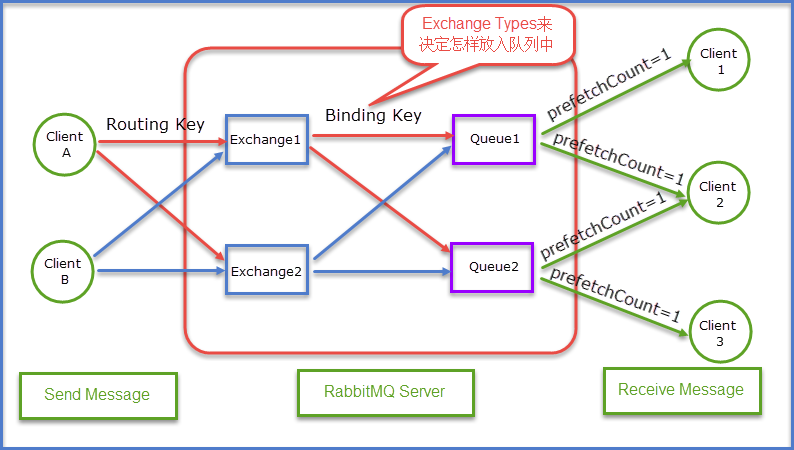
clientA和clientB可以看成是订单系统,往消息队列里面发送消息,client123可以看成是库存系统,往消息队列里面取数据
解释一下图中的一些关键词
Queue:
队列,rabbitmq的作用是存储消息,那么自然要有队列来进行存储。队列的特点是先进先出,因此可以看出clientA和clientB是生产者,生产者生产消息送到rabbitmq的内部对象Queue里面去,而client123可以看成是消费者,消费者则是从队列中取出数据,可以简化为:

生产者Send Message “A”送到Queue中,消费者发现消息队列Queue中有订阅的消息,就会将这条消息A读取出来进行一系列的业务操作,这里是一个消费者对应一个队列Queue,也可以是多个消费者订阅同一个队列Queue,当然这里就会将Queue里面的消息平分给其他的消费者,但这样会存在一个问题。每个消息的处理时间不同的话,就会有消费者一直处于忙碌之中,而有的消费者处理完之后会处于空闲之中。因为前面提到了,如果一个消费者对应一个队列Queue的话,很好理解。但是多个消费者对应一个队列Queue的话,就会将Queue里面的消息均摊给相应的的消费者,因此我们就可以使用prefetchcount来限制每次发送给消费者信息的的个数
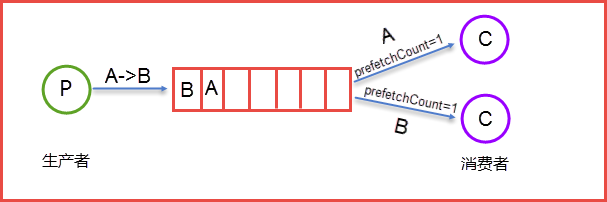
这里的prefetchCount=1是指每次从Queue中发送一条消息来。等消费者处理完这条消息后Queue会再发送一条消息给消费者。
exchange
在最开始的rabbitmq的架构图中,我们看到了生产者将消息发送到Queue当中,但是是直接发送的吗?显示不是,中间经过了一层exchange,那么这个exchange是干什么的呢?首先我们可以思考一下,这个rabbitmq里面只能有一个Queue吗?显然不是,可以有多个Queue,那生产者send message的时候,要往哪一个Queue里面send数据呢。所以这个时候exchange就出现了,生产者send数据其实不是直接send到Queue里面去的,而是经过exchange(交换器),再由exchange将消息路由到一个或者多个Queue,当然exchange还会对不符合规则的消息进行丢弃,这里指的是下面的exchange type。那么exchange是怎样将消息准确的推送到对应的Queue里面呢?主要依赖于binding,rabbitmq是通过binding将exchange和Queue链接在一起,这样exchange就知道如何将消息准确的推送到对应的Queue当中
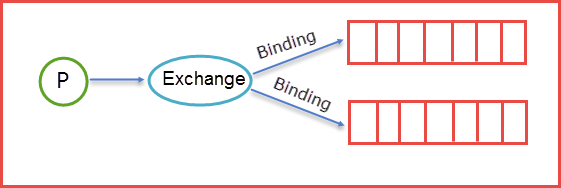
在binding(绑定)exchange和Queue的同时,一般会指定一个binding key,生产者将消息发送到exchange的时候,一般会产生一个routing key,当然binding key和routing key对应上之后消息就会发送到相应的Queue中去。而exchange有四种类型,不同的类型有着不同的策略。すなわち生产者发送了一条消息,routing key的规则是A,就会将routing key=A的消息发送到exchange中,这时候exchange中有自己的规则,会按照对应的规则去筛选生产者发送的消息,如果能对应上exchange的内部规则,那么exchange就会将消息推送到对应的Queue当中去。因此,生产者往exchange里面send消息,会产生一个routing key,exchange和Queue绑定的时候会有一个binding key,只要两者符合,那么就会将生产者send过来的消息放到对应的Queue当中。但是刚才也说了,exchange有着不同的类型(exchange type),不同类型的exchange会有着不同的策略,这也就决定了消息所推送到的Queue会不一样,那么exchange都有哪些类型呢?
exchange type
·fanout
fanout类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中。

上图所示,生产者(P)生产消息1将消息1推送到Exchange,由于Exchange Type=fanout这时候会遵循fanout的规则将消息推送到所有与它绑定Queue,也就是图上的两个Queue最后两个消费者消费。
·direct
direct类型的Exchange路由规则也很简单,它会把消息路由到那些binding key与routing key完全匹配的Queue中

当生产者(P)发送消息时Rotuing key=booking时,这时候将消息传送给Exchange,Exchange获取到生产者发送过来消息后,会根据自身的规则进行与匹配相应的Queue,这时发现Queue1和Queue2都符合,就会将消息传送给这两个队列,如果我们以Rotuing key=create和Rotuing key=confirm发送消息时,这时消息只会被推送到Queue2队列中,其他Routing Key的消息将会被丢弃。
·topic
前面提到的direct规则是严格意义上的匹配,换言之Routing Key必须与Binding Key相匹配的时候才将消息传送给Queue,那么topic这个规则就是模糊匹配,可以通过通配符满足一部分规则就可以传送。它的约定是:
1.routing key为一个句点号“. ”分隔的字符串(我们将被句点号“. ”分隔开的每一段独立的字符串称为一个单词),如“stock.usd.nyse”、“nyse.vmw”、“quick.orange.rabbit”
2.binding key与routing key一样也是句点号“. ”分隔的字符串
3.binding key中可以存在两种特殊字符“*”与“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)
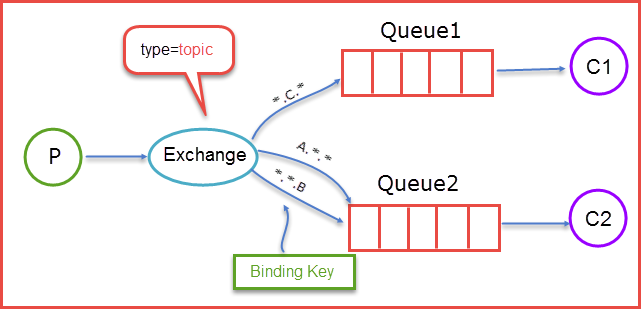
当生产者发送消息Routing Key=F.C.E的时候,这时候只满足Queue1,所以会被路由到Queue中,如果Routing Key=A.C.E这时候会被同是路由到Queue1和Queue2中,如果Routing Key=A.F.B时,这里只会发送一条消息到Queue2中。
·headers
headers类型的Exchange不依赖于routing key与binding key的匹配规则来路由消息,而是根据发送的消息内容中的headers属性进行匹配。
在绑定Queue与Exchange时指定一组键值对;当消息发送到Exchange时,RabbitMQ会取到该消息的headers(也是一个键值对的形式),对比其中的键值对是否完全匹配Queue与Exchange绑定时指定的键值对;如果完全匹配则消息会路由到该Queue,否则不会路由到该Queue。
补充说明:
ConnectionFactory、Connection、Channel
ConnectionFactory、Connection、Channel都是RabbitMQ对外提供的API中最基本的对象。Connection是RabbitMQ的socket链接,它封装了socket协议相关部分逻辑。ConnectionFactory为Connection的制造工厂。
Channel是我们与RabbitMQ打交道的最重要的一个接口,我们大部分的业务操作是在Channel这个接口中完成的,包括定义Queue、定义Exchange、绑定Queue与Exchange、发布消息等。
Connection就是建立一个TCP连接,生产者和消费者的都是通过TCP的连接到RabbitMQ Server中的,这个后续会在程序中体现出来。
Channel虚拟连接,建立在上面TCP连接的基础上,数据流动都是通过Channel来进行的。为什么不是直接建立在TCP的基础上进行数据流动呢?如果建立在TCP的基础上进行数据流动,建立和关闭TCP连接有代价。频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。
申明:以上内容参考于https://www.cnblogs.com/dwlsxj/p/RabbitMQ.html
下面我们就来安装rabbitmq,由于rabbitmq是erlang语言编写的,因此在安装rabbitmq之前,需要先安装erlang。我安装的机器为ubuntu 18.04
安装erlang很简单,直接apt-get install erlang-nox即可
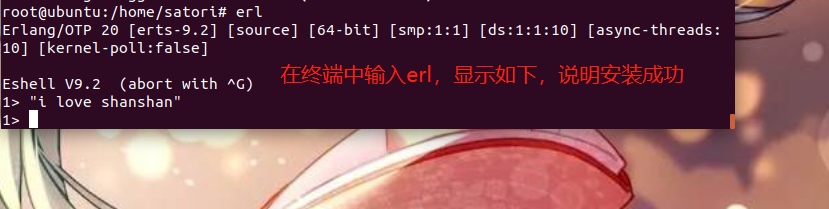
下面安装rabbitmq,apt-get install rabbitmq-server
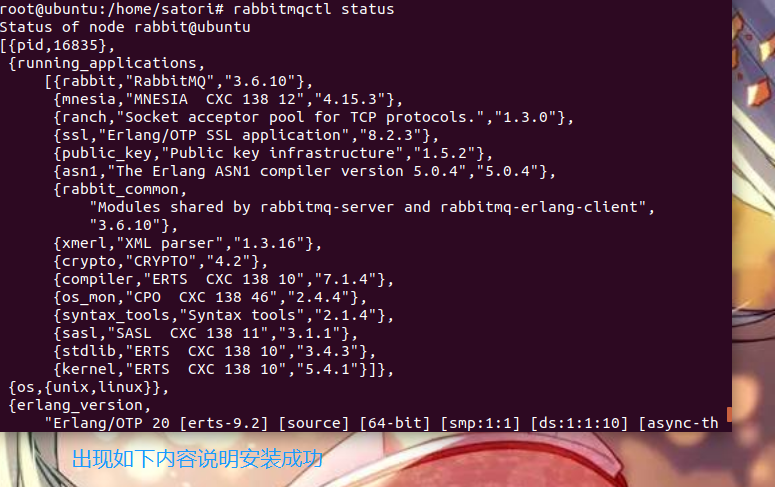
怎么确定是否安装成功呢?直接输入rabbitmqctl status即可
可以通过以下命令操作rabbitmq。
启动rabbitmq: service rabbitmq-server start
停止rabbitmq: service rabbitmq-server stop
重启rabbitmq: service rabbitmq-server restart
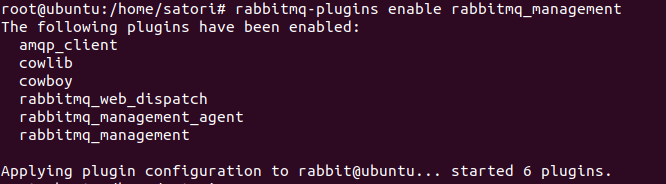
接下来启动rabbitmq插件:rabbitmq-plugins enable rabbitmq_management,这个可以启动rabbitmq的web控制台
添加用户,格式:rabbitmqctl add_user 用户名 密码

给用户管理员权限,rabbitmqctl set_user_tags 用户名 administrator

为用户设置读写权限: rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"

接下来就可以访问web控制台了,输入ip:15672即可,如下图,然后输入用户名和密码,登录web控制台。
下面我们就要使用python来连接了,python操作rabbitmq,需要一个叫做pika的模块,直接pip install pika即可。我这里直接在windows上远程操作虚拟机里的rabbitmq
看看pika的基本使用,如何连接rabbitmq并生产消费消息
'''
生产者
'''
import pika
# 我们现在是远程登录,一般情况下公司不可能随便就会让你远程连接,所以肯定需要指定用户进行认证。我们刚才创建了一个名为satori的用户并赋予了管理员权限
credentials = pika.PlainCredentials("satori", "123456")
# 这一步只是创建了socket,相当于建立了tcp连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
# 这一步则是在tcp连接的基础之上创建了一个channel,用来生成Queue,send message等等
channel = connection.channel()
# 使用channel声明一个Queue
channel.queue_declare(queue="girls")
# 下面发布消息,我们目前还没有用到交换器,所以暂时先不使用
channel.basic_publish(exchange="",
routing_key="girls",
body="my name is satori")
print("finished")
# 关闭连接
channel.close()
'''
消费者
'''
from pprint import pprint
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
# 这里还是声明一个queue,刚才生产者明明已经声明了, 为什么还要再次声明?先不管,后面说
channel.queue_declare(queue="girls")
# 定义一个回调函数
def callback(ch, method, properties, body):
pprint({"ch": ch, "method": method, "properties": properties, "body": body})
# 订阅,消费消息
channel.basic_consume(callback, # 指定回调函数
queue="girls",
no_ack=True)
# 这一步才算是真正开始消费
channel.start_consuming()
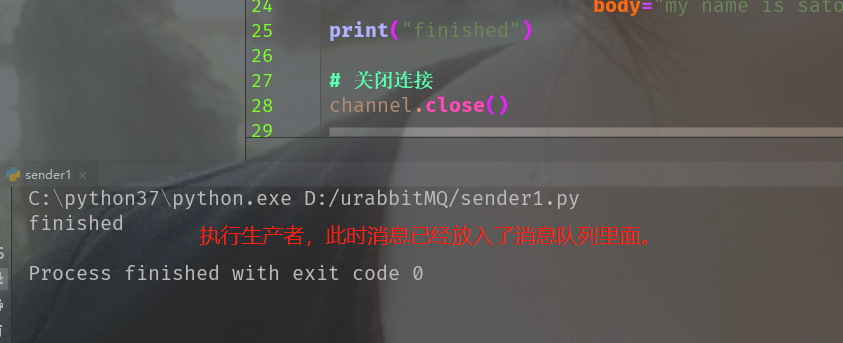

我再一次执行生产者

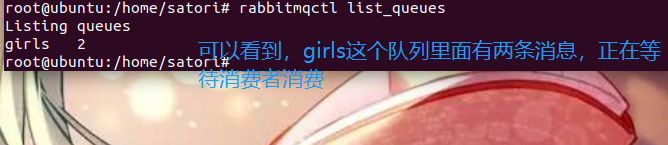
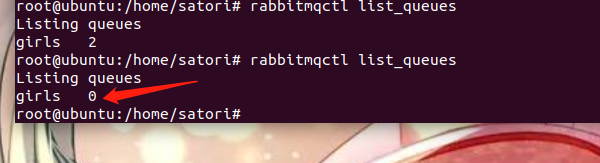
这一次我关闭消费者,执行两次生产者,并把发送的内容改一下,改成"love_shan"和"love_shanshan",然后在终端输入rabbitmqctl list_queues看看会有什么结果
再次启动消费者,可以看到两条消息都被消费了
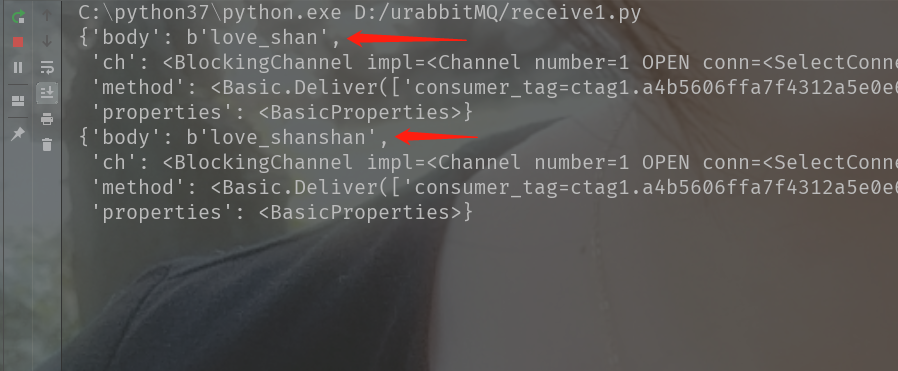
再回到终端看看,会发现队列里面的消息已经没了
继续我们之前的遗留问题,为什么我们在生产者当中声明了queue,却要在消费者当中再次声明。因为我们说不准到底是生产者先启动还是消费者先启动,如果消费者先启动而且不声明queue的话,消费者上哪儿排队去。好比一个包子铺,如果没有那么消费者会创建一个,生产者做好包子就直接往里面放就可以了。所以当声明一个queue时,会先检测有没有这个queue,如果没有会先创建,有的话直接生产消息或者消费消息。所以这算是一个为了安全起见所采取的措施。
消息安全接收
下面又出现了一个问题,怎么确保消息被消费掉了呢?如果消费者在消费消息的时候突然挂掉了,消息没消费完,包子吃一半噎死了,该咋办呢?其实rabbitmq有一个机制,那就是当消费者消费完一条消息之后,必须给服务器端一个响应表示已经消费完了,这个时候包子铺才会在自己的账本上记一笔账,表示这个包子真的被消费掉了。也就是说当消息从队列里面取出的时候,可以看成是将消息拷贝了一份给消费者,但此时的消息已经被打上了一个标记,表示这条消息已经有人消费了。当消息真的被消费了,那么会将该消息从队列里面删掉,如果消费者挂掉了,得不到响应,那么会将标记清清除,等待其他消费者消费。并且一旦某个消费者无法消费,那么服务器就会得到响应,知道socket断开,下次就不会再将消息发给这个消费者了。
注意:默认是不会管的,如果想要实现的话,还需要我们手动指定,下面是代码实现
'''
生产者
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="girls")
channel.basic_publish(exchange="",
routing_key="girls",
body="love_shanshan"
)
print("finished")
channel.close()
'''
消费者
'''
import pika
import time
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue="girls")
def callback(ch, method, properties, body):
print("准备消费消息了······")
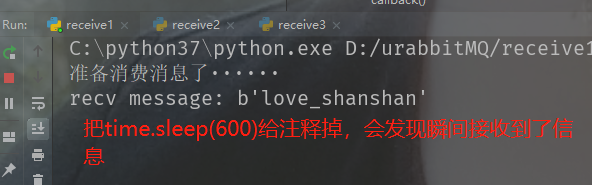
time.sleep(600)
print(f"recv message: {body}")
# 消息消费完毕必须要给服务端发送一个确认信息,method.delivery_tag是随机生成的值,告诉服务端消息消费完了,并且还要确保消费的消息确实是需要消费的消息
# 不能拿一个韭菜馅的包子,然后说白菜馅的包子吃完了
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(callback, # 指定回调函数
queue="girls",
# no_ack=True, 这个no_ack等于True表示处理完了不进行确认,丢了我们也不管,所以我们要注释掉。当然默认是True,建议就不要写
)
channel.start_consuming()
消费者我拷贝了两份,总共三份,代码是一模一样的
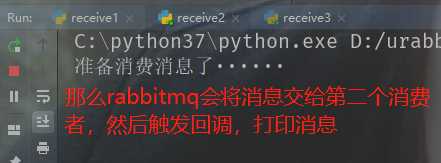
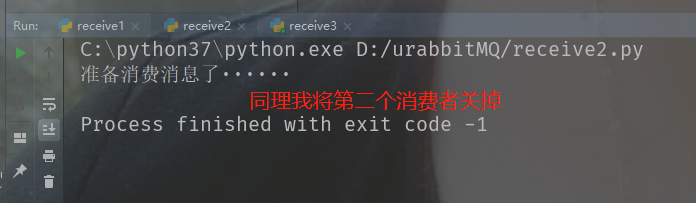
当生产者发送消息的时候,会有一个消费者消费。但是由于睡了600秒,所以需要等600秒之后,才能给服务端响应消费完毕,即便你真的消费完了,但是只要没给服务端响应,服务端都会认为你没有成功消费。在这消费的过程中队列里面的消息被标记了,也就是说此时其余的消费者是无法消费的,因为已经有消费者在消费了。当我关闭正在消费的消费者时,那么服务端感知到这个消费者挂掉了,并且没有收到响应,那么会认为消息消费失败,于是将这条消息的标记解除,并交给下一个消费者。这样就确保消息都会有消费者消费。

下面启动三个消费者

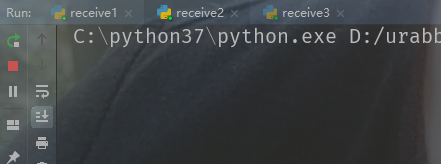

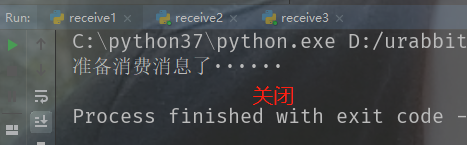
也就是说,消息已经被第一个消费者消费了,此时队列里的消息被标记了,而里面我们只放了一条消息,所以第二个和第三个消费者处于等待状态。

此时我关掉第一个消费者


600s有点长,我们改一下

消息持久化
现在问题又来了,我们刚才关心的是消费者挂了,消息怎么消费。那万一rabbitmq服务挂了呢?我们生产者往队列里面写了好多消息,但是如果服务挂掉了,那么队列里面的消息还在吗?答案是别说消息了,连队列都没了。那么怎么办呢?
channel.queue_declare(queue="girls", durable=True),加上一个durable=True,那么在重启服务的时候,会保住队列,但是里面的消息还是保不住。
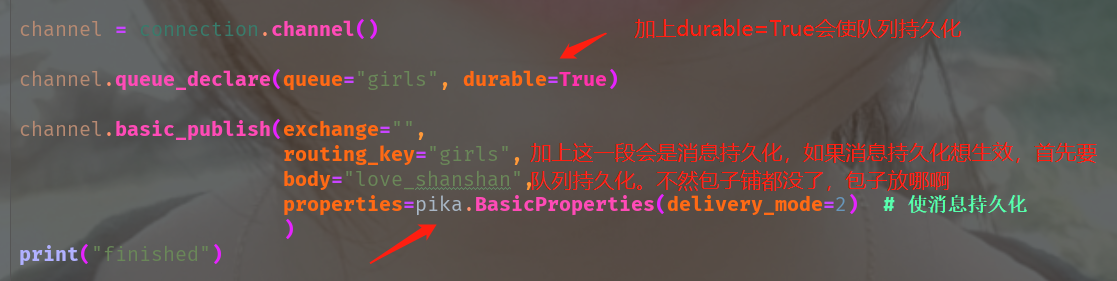
消息订阅和发布
之前的例子都是一对一的消息发送和接收,即消息只能发送到指定的queue里面,但是有些时候希望消息被所有的queue接收到,起到类似于广播的效果,那么这个时候就需要exchange了。并且广播是不会想之前一样,消费者不在线就把消息存起来,等消费者上线再接收。广播的话,不管消费者在不在线都要广播,并且广播完了就不再广播了。还记得exchange有哪四种类型吗?我们来演示一下
1.fanout
'''
生产者
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
# 声明转发器,并且此时连队列都不需要声明了,因为我们不再往队列里面发了,而是往exchange里面发
channel.exchange_declare(exchange="logs", type="fanout")
channel.basic_publish(exchange="logs",
# routing_key="girls",此时的routing_key就不需要指定了,因为知道exchange的类型是fanout,所以直接广播给每个队列
body="love_shanshan",
)
print("finished")
channel.close()
'''
消费者
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="logs", type="fanout")
# 注意接收者,必须要指定单独的队列,不然就乱套了,并且不能重名,exclusive表示排他,也是rabbitmq会帮我们生成不重名的队列名
# 并且会在消费者断开之后,会自动将该queue删除掉
result = channel.queue_declare(exclusive=True)
# 调用result.method.queue会拿到该队列名
queue_name = result.method.queue
# 将生成的queue绑定到交换机上,这样当生产者发送数据给exchange的时候,exchange会自动的将数据发送到绑定的queue里面
channel.queue_bind(exchange="logs", queue=queue_name)
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True
)
channel.start_consuming()
并且此时一定要先启动消费者,再启动生产者。因为生产者一旦启动,不管消费者有没有在线,都会广播,等到消费者上线,已经广播完了
2.direct,默认是direct
'''
生产者
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
# 默认是direct
channel.exchange_declare(exchange="direct_logs")
channel.basic_publish(exchange="direct_logs",
routing_key="info", # 只往routing_key="info"的队列发送消息
body="love_shanshan",
)
print("finished")
channel.close()
'''
消费者1
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="direct_logs")
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 绑定的时候指定routing_key
channel.queue_bind(exchange="direct_logs", queue=queue_name, routing_key="info")
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True
)
channel.start_consuming()
'''
消费者2
'''
import pika
credentials = pika.PlainCredentials("satori", "123456")
connection = pika.BlockingConnection(pika.ConnectionParameters(host="192.168.42.141",
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="direct_logs")
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 绑定的时候指定routing_key,这里的routing_key便不再是info了,而是error。
channel.queue_bind(exchange="direct_logs", queue=queue_name, routing_key="error")
def callback(ch, method, properties, body):
print(body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True
)
channel.start_consuming()


3.topic
跟direct比较相似,不再演示了
4.headers
不常用,不再演示了
消息rpc
我们目前的消息都是单向的,生产者发送,消费者只能被动的接收,那么消费者可不可以给生产者反馈呢?显然是可以的,此时就需要两个队列,不能只有一个队列,否则就死循环了。A往队列1发送数据,B从队列1里面取数据。然后B往队列2发数据,A往队列2取数据。
pass
累了,不想写了