使用fiddler抓取不到浏览器的包时常用的解决办法:
1.必须先打开Fiddler,再打开浏览器
2.Fiddler只能截取网页与服务器间的通信,无法截取游戏封包
3.Fiddler没有打开捕捉模式
其他问题的解决方法:
1、这种是chrome浏览器抓不到的情况:实际上fiddler是可以抓chrome的请求的。
由于可能chrome安装了代理管理的插件SwitchySharp,无论选择直接连接还是选择使用代理连接,插件都会屏蔽fiddler的设置。
fiddler会自动给浏览器设置一个代理127.0.0.1 端口8888,并且记忆浏览器的代理设置,所有的请求先走fiddler代理,再走浏览器代理。
如果使用插件,可能会直接屏蔽了fiddler的代理,因此无法监听到请求了。
chrome下的解决方法,代理插件选择“使用系统代理设置”选项,fiddler又重新能看到chrome的请求了。
或者不使用插件,不用卸载,chrome很方便禁用一个插件。然后使用浏览器默认的代理设置方式就ok了。
使用代理插件是为了方便切换代理,但是可能会导致fiddler等工具无法使用。正所谓鱼和熊掌不可兼得。
2、还有就是可能是某个进程导致的,通常我们会到任务管理器中找,这里是个藏污纳垢的地方,里面会发现好多的问题,你可以尝试着把跟系统无关的进程都关掉,一个一个排查,看可能是哪里有问题。先这么多,后面如果有新的问题,再更新。
3、还有一种情况是用了一款叫做adsafe的软件,可以屏蔽掉所有的广告。把他关掉之后就可以抓包了。分析了以下原因可能是这款软件权限比较高,就和杀毒软件一样,可以接管你所有的流量。所以,fiddler就不能正常的抓到你所有的包了。直接用任务管理器把这个程序进程杀掉就好了。
ASCII码对照表|ASCII编码_911查询 http://ascii.911cha.com/
10,0A,换行键,LF
13,0D,回车键,CR
HTTP报文是简单的格式化数据块。看一下图3-3给出的例子。每条报文都包含一条来自客户端的请求,或者一条来自服务器的响应。它们由三个部分组成:对报文进行描述的起始行(start line)、包含属性的首部(header)块,以及可选的、包含数据的主体(body)部分。
起始行和首部就是由行分隔的ASCII文本。每行都以一个由两个字符组成的行终止序列作为结束,其中包括一个回车符(ASCII码13)和一个换行符(ASCII码10)。这个行终止序列可以写做CRLF。需要指出的是,尽管HTTP规范中说明应该用CRLF来表示行终止,但稳健的应用程序也应该接受单个换行符作为行的终止。有些老的,或不完整的HTTP应用程序并不总是既发送回车符,又发送换行符。
实体的主体或报文的主体(或者就称为主体)是一个可选的数据块。与起始行和首部不同的是,主体中可以包含文本或二进制数据,也可以为空。
在图3-3的例子中,首部给出了一些与主体有关的信息。Content-Type行说明了主体是什么——在这个例子中,就是纯文本文档。Content-Length行说明了主体有多大,在这里就只有19个字节。
所有的HTTP报文都可以分为两类:请求报文(request message)和响应报文(response message)。请求报文会向Web服务器请求一个动作。响应报文会将请求的结果返回给客户端。请求和响应报文的基本报文结构相同。
HTTP请求报文中包含命令和URL
HTTP响应报文中包含了事务的结果
这是请求报文的格式:
<method> <request-URL> <version>
<headers>
<entity-body>
这是响应报文的格式(注意,只有起始行的语法有所不同):
<version> <status> <reason-phrase>
<headers>
<entity-body>
下面是对各部分的简要描述。
3.3.3 HEAD
HEAD方法与GET方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。使用HEAD,可以:
在不获取资源的情况下了解资源的情况(比如,判断其类型); •
通过查看响应中的状态码,看看某个对象是否存在; •
通过查看首部,测试资源是否被修改了。 •
服务器开发者必须确保返回的首部与GET请求所返回的首部完全相同。遵循HTTP/1.1规范,就必须实现HEAD方法。图3-8显示了实际的HEAD方法。
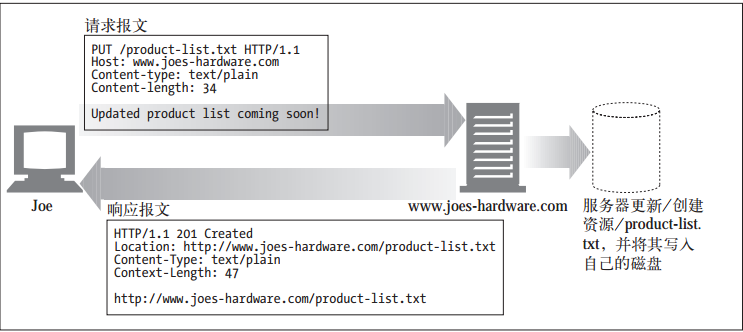
3.3.4 PUT
与GET从服务器读取文档相反,PUT方法会向服务器写入文档。有些发布系统允许用户创建Web页面,并用PUT直接将其安装到Web服务器上去(参见图3-9)。
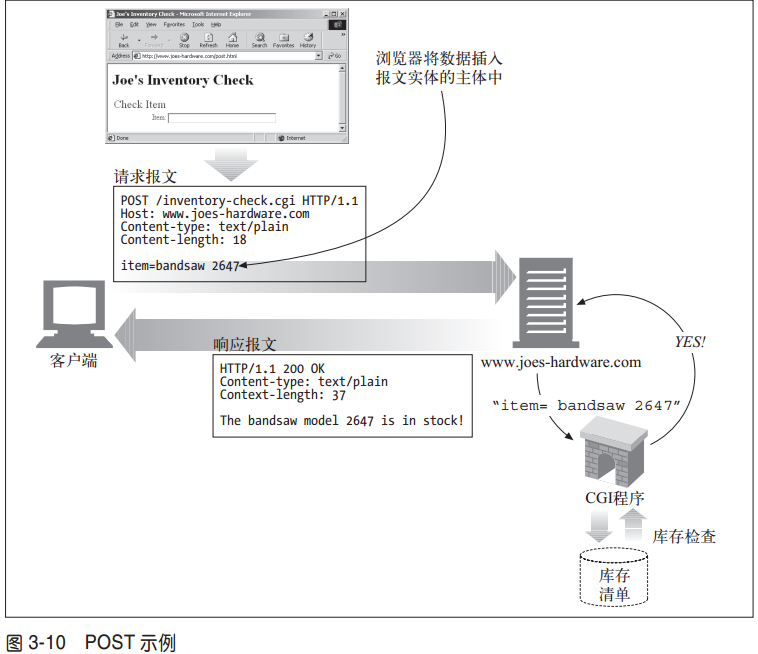
3.3.5 POST
POST方法起初是用来向服务器输入数据的3。实际上,通常会用它来支持HTML的表单。表单中填好的数据通常会被送给服务器,然后由服务器将其发送到它要去的地方(比如,送到一个服务器网关程序中,然后由这个程序对其进行处理)。图3-10显示了一个用POST方法发起HTTP请求——向服务器发送表单数据——的客户端。
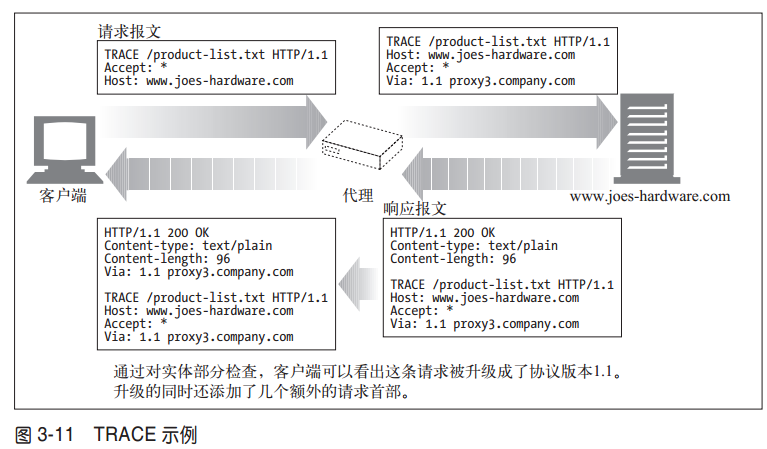
3.3.6 TRACE
客户端发起一个请求时,这个请求可能要穿过防火墙、代理、网关或其他一些应用程序。每个中间节点都可能会修改原始的HTTP请求。TRACE方法允许客户端在最终将请求发送给服务器时,看看它变成了什么样子。
TRACE请求会在目的服务器端发起一个“环回”诊断。行程最后一站的服务器会弹回一条TRACE响应,并在响应主体中携带它收到的原始请求报文。这样客户端就可以查看在所有中间HTTP应用程序组成的请求/ 响应链上,原始报文是否,以及如何被毁坏或修改过(参见图3-11)。
3.5.2 请求首部
请求首部是只在请求报文中有意义的首部。用于说明是谁或什么在发送请求、请求源自何处,或者客户端的喜好及能力。服务器可以根据请求首部给出的客户端信息,试着为客户端提供更好的响应。表3-13列出了请求的信息性首部。
表3-13 请求的信息性首部
首 部 描 述
Client-IP 提供了运行客户端的机器的IP地址
From 提供了客户端用户的E-mail地址
Host 给出了接收请求的服务器的主机名和端口号
Referer 提供了包含当前请求URI的文档的URL
UA-Color 提供了与客户端显示器的显示颜色有关的信息
UA-CPU 给出了客户端CPU的类型或制造商
UA-Disp 提供了与客户端显示器(屏幕)能力有关的信息
UA-OS 给出了运行在客户端机器上的操作系统名称及版本
UA-Pixels 提供了客户端显示器的像素信息
User-Agent 将发起请求的应用程序名称告知服务器
参考资料:http://blog.csdn.net/sufubo/article/details/49331705
【Fiddler】使用fiddler抓取指定浏览器的包 - Lauren - 博客园 https://www.cnblogs.com/lauren1003/p/6519630.html
《HTTP权威指南》([美]David Gourley,[美]Brian Totty,[美]Marjorie Sayer,[美]Sailu Reddy,[美]Anshu Aggarwal)【摘要 书评 试读】- 京东图书 https://item.jd.com/11056556.html
百度搜索url编码解密(url encode decode) - 程序员大本营 http://www.pianshen.com/article/236199113/
百度搜索结果中的URL是如何加密的?-CSDN论坛 https://bbs.csdn.net/topics/392175054?page=1