一、数据库访问方式有两种
1、表扫描
从表的物理起点开始浏览表中的每一行,如果筛选条件,则包含在结果集中。
2、索引
使用B树查找数据。
二、索引分类
先解释下几个概念
- 堆:没有聚集索引的表
- 聚集表:含有聚集索引的表
- B树:平衡树,试图提供一种一致的、成本相对较低的方法,以找到一条特定的信息
索引分为3种, 如何理解呢? 新建一张operlog表示例,没加主键(创建主键会默认创建一个唯一聚集索引)
CREATE TABLE [dbo].[operlog]( [id] [int] IDENTITY(1,1) NOT NULL, [operdate] [datetime] NOT NULL, [oper] [nvarchar](200) NOT NULL )
1、聚集索引
以下为创建聚集索引: Operlog_id为聚集索引
-- 创建了聚集索引 CREATE CLUSTERED INDEX Operlog_id ON dbo.operlog(id)
特点:
- 每个表中只能有一个聚集索引
- 页节点存放的是真正数据
- 新数据按着他在聚集索引里正确的物理顺序插入
2、非聚集索引
(1)堆上的非聚集索引
以下为创建对上的聚集索引: Operlog_oper为非聚集索引
-- 创建了非聚集索引(只有此语句) CREATE NONCLUSTERED INDEX Operlog_oper ON dbo.operlog(oper)
特点:
- 页节点存放的是数据指针(RID:由特定行的区段、页、行偏移量组成)
- 有可能出现多次访问同一个数据页,导致查询慢(不过也可能数据页被内存缓存了,速度不一定慢)
(2)聚集索引上的非聚集索引(或称聚集表上的非聚集索引)
以下为创建聚集表上的非聚集索引: Operlog_id为聚集索引,Operlog_oper为聚集表上的非聚集索引
-- 创建了聚集索引 CREATE CLUSTERED INDEX Operlog_id ON dbo.operlog(id) -- 创建了聚集表上的非聚集索引 CREATE NONCLUSTERED INDEX Operlog_oper ON dbo.operlog(oper)
特点:
- 页节点存放的是聚集键,在找到节点后仍要继续按聚集索引查找
- 如果以此索引查找,可能会比"堆上的非聚集索引"查找还慢,因为他多了一步按聚集索引查找,如果数据量大的话,会比"堆上的非聚集索"引多很多开销
三、详细介绍
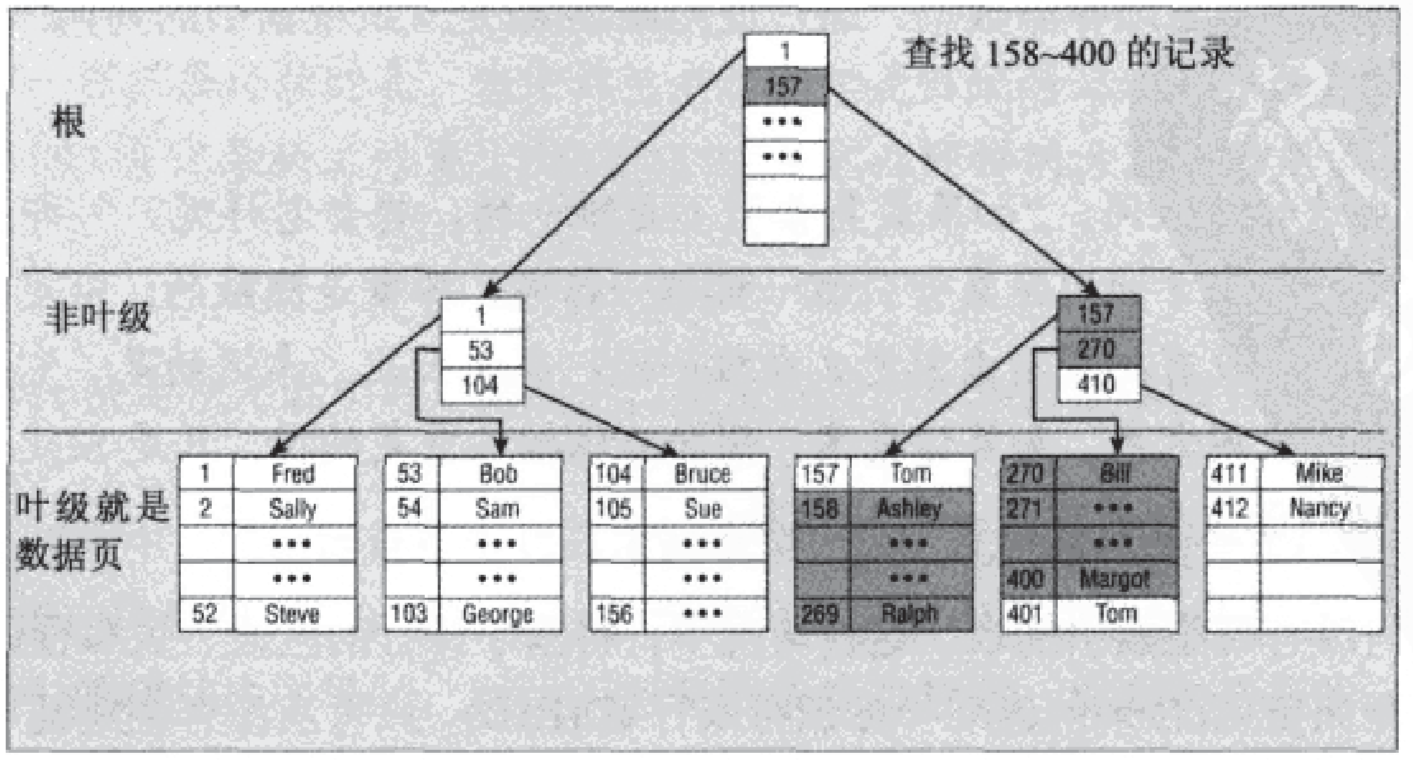
1、聚集索引: 数据叶节点就是真正数据,如下图所示:
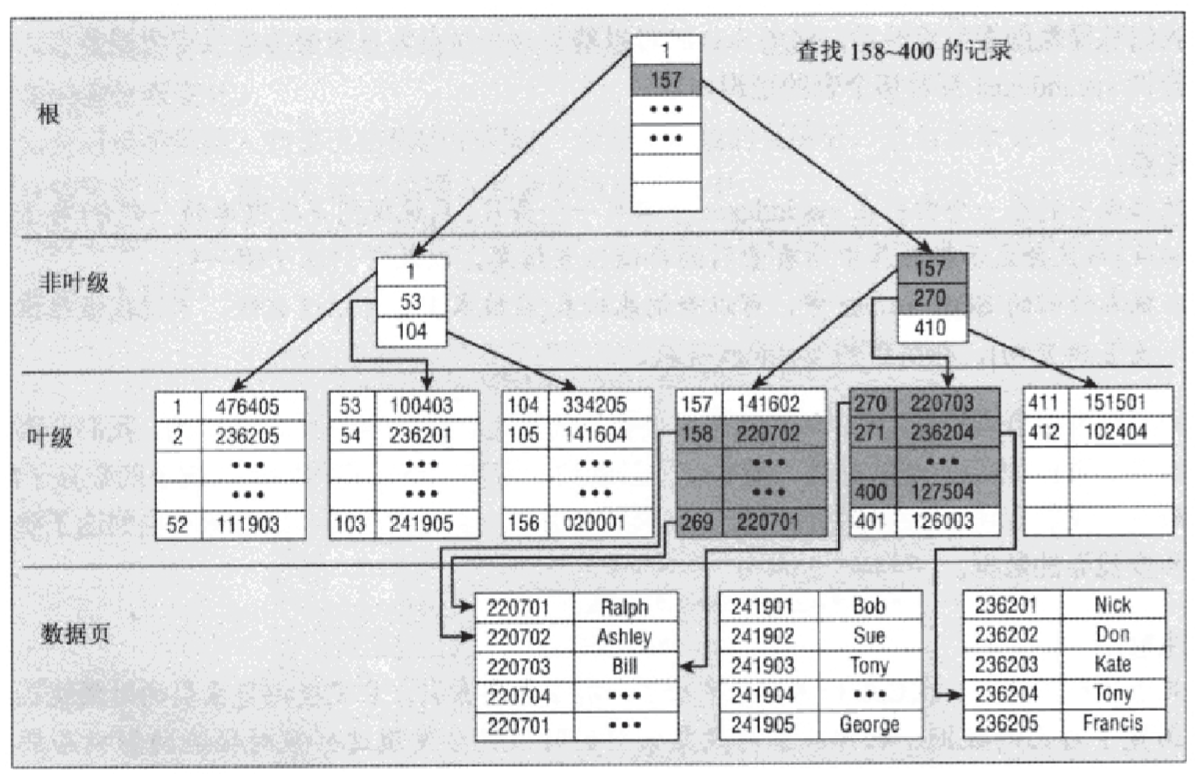
2、堆上的非聚集索引:叶节点存储的不是真正的数据,而是指向数据的指针,如下图所示:
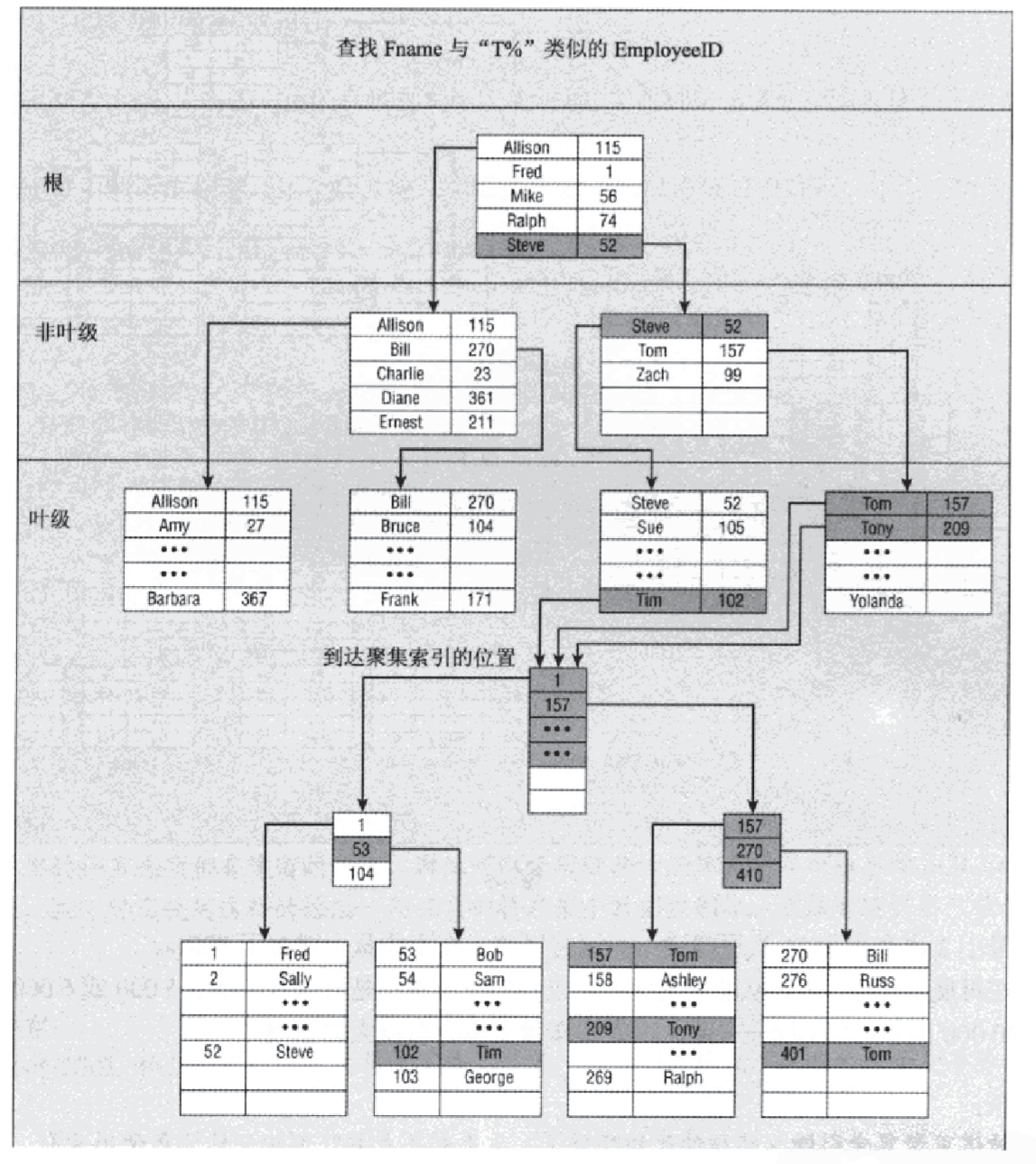
3、聚集表上的非聚集索引:叶节点存储的不是真实数据,也不是数据的指针,而是聚集键,如下图所示:
四、如何选择什么时候用什么样的索引?
索引不是万能的!
- 如果经常做增加修改,尽量少用索引,因为增加会导致重建索引,修改是先删除后增加索引,都会增加开销
- 非聚集索引:列的唯一值百分比越高越好
- 聚集索引:每个表只有一个,所以尽量在表创建时确定好,以防后期修改维护麻烦
- 使用Sql Server Profiler分析
本文参考《sql server 2008高级程序设计》,如有错误,敬请指正!