java的IO通过java.io包下的类和接口来支持。主要包括输入输出流。每种输入输出流可以分为字节流和字符流。
java7在java.nio即其子包下提供了一系列全新的API。
java还可以通过序列话将内存中的java对象转换为二进制字节流。
File类
File对象是操作文件或者路径的可以删除,创建,遍历文件或者路径。
var file=new File(".");
System.out.println(file.getAbsolutePath());
var file1=new File(".\abc.txt");
var fold=new File("疯狂java");
// fold.mkdir();
//创建文件需要在创建File对象时,指定好路径和文件名。
var filejava=new File(".\疯狂java\abc.txt");
filejava.createNewFile();
System.out.println(file1.getAbsolutePath());;
//判断File对象所对应的文件或者目录是否存在
if(file.exists()){
System.out.println("file所对应的文件或者目录存在");
}
if(!file1.exists()){
System.out.println("file1所对应的文件或者目录不存在");
System.out.println(file1.createNewFile());
}
//New File只是得到一个File对象,这个对象可以操作文件也可以操作目录。如果使用createNewFile,则生成文件,如果使用mkdir则生成目录。
}
}
java的IO流
java把不同的输入输出抽象表述为流stream。开发者可以使用一致的代码读写不同的IO流节点。
流的分类
按照流向分为输入流和输出流。按照程序所运行的内存的角度,从内存到硬盘为输出。
输出流:OutputStream,Writer作为基类
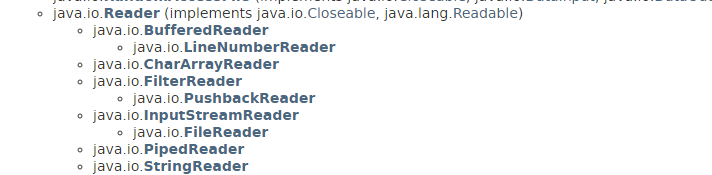
输入流:InputStream,Reader作为基类。
字节流和字符流,主要是操作的对象不同,字节流操作8位的byte,字符流操作16位的char。前者以InputStream和OutputStream为基类。字符流以Reader和Writer为基类。
节点流和处理流
节点流就是当程序和数据源直接相连时,可以从、向一个特定的IO设备读写数据的流。低级流
处理流:用于对一个已存在的流进行连接或者封装。封装后的流来实现数据读写功能。也被称为高级流,包装流
java使用处理流来包装节点流是一种典型的装饰器设计模式,通过使用处理流来包装不同的节点流,既可以消除不同节点流的实现差异,也可以提供更方便的方法来完成输入输出功能。
处理流的主要功能:
增加缓冲的方式来提高输入输出效率
处理流可以提供一系列方法,一次性输入输出大批量内容,而不用输入或输出一个或多个字节或字符
通过使用处理流,java程序无须理会输入输出的节点是磁盘。网络还是其他设备,程序值要将这些节点流包装成处理流,就可以使用相同的输入输出代码来读写不同的输入输出设备
FileInputStream和FileOutputStream是节点输入输出流。
FileReader和FileWriter是字符输入输出流。
其中,使用节点输入和字符输入流是,需要先定义byte数组和char数组。如果数组大小够用,则一次读完。如果数组大小不够,则循环读取,根据读取方法 的返回值(如果没有读到内容返回-1)来判断停止条件。方法会自动寻找到上一次的位置,数组会自动被覆盖,如果最后一次读取的长度小于数组长度,则上一次读取的内容的尾部将不会覆盖,所以输出读取内容的时候,需要添加个数。否则会重复输出。
写的时候一样。不过FileWriter可以直接传入字符串。可以省略字符数组的定义。
以上介绍了四个抽象基类和四个方位文件的节点流。
为了方便,我们一般使用处理流
处理流思路是程序通过处理流来输入输出功能,让节点流与底层IO设备文件交互
识别处理流,只需要看其构造函数参数是不是一个物理节点,如果是是一个已经存在的流,那么肯定是一个处理流。节点流的构造器参数都是以物理IO节点为参数的。
使用处理流,开发效率高,执行效率也高。
使用处理流时,只需关闭上层的处理流,而节点流会自动被关闭。
字节流的功能比字符流强大。因为字节可以处理所有的二进制文件。但是如果是文本的话就需要转换,所以如果输入输出的内容是二进制文件,才考虑使用自己流。
打印流的printStream是字节流,而writer是字符流。我们通常用的是字节流。
在java.io包下有40个类,但是还有AudioInputStream,访问音频,CipherInputStream,DeflaterInputStream,ZipInputStream。加密解密,压缩解压的字节流。
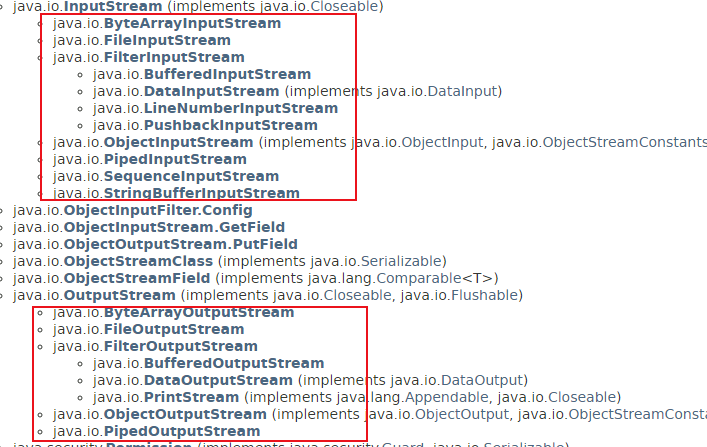

如图,其中ByteArray的是数组的输入输出流。有字符的也有字节流。构造参数为字节数组和字符数组。
还有字符串的输出输入流。
还有四个访问管道的流有字节和字符流。
还有四个缓冲流。提高输入输出效率,增加缓冲功能后需要使用flush才能将蝗虫去内容写入实际的物理节点。
还有两个转换流
InputStreamReader:将字节输入流转换为字符输入流
OutPutStreamWriter:将字节输出流转换为字符输出流。
var reader=new InputStreamReader(System.in)将字节输入流(键盘输入是字节输入流的实例)转换为字符输入流。还可以将reader转换为BufferedReader,因为这个缓冲流可以一次读一行。以换行为标志,如果没有读到换行符,则程序阻塞,等读到换行符为止。
推回输入流 有pushbackInputStream和pushbackReader 字节流和字符流
退回输入流带有一个缓冲区,当调用这两个输入流时,会把指定的数组内容退回到缓冲区,当推回输入流每次调用read时,会先从推回缓冲区读取,只完全读取了退回缓冲区内容后,还没有装满read所需的数组时,才会从原输入流中读取
重定向标志输入输出
三个方法
setErr(PrintStream err)
setIn(InputStream in)
setOut(PrintStream out)
都是传入字节流做参数。
JAVA虚拟机读写其他进程的数据
Runtime对象的exec方法可以运行平台上的其他程序,该方法产生一个process对象,process对象代表由该java程序启动子进程。process提供了如下三个方法。用于让程序和其子进程进行通信。
InputStream getErrorStream()获取子进程的错误流。
InputStream getInputStream()获取子进程的输入流
OutputStream getOutputStream()获取子进程的输出流。
这里的输入输出要站在java程序的角度,例如让子进程读取程序中的数据,则需要使用输出流。
向子进程输入数据,需要获得子进程的输出流,然后子进程需要创建scanner对象,并且是标准输入。
RandomAccessFile
RandomAccessFile是java输入输出流体系中功能最丰富的文件内容访问类。可以读取文件也可以输出数据。与其他输入输出流不同,他支持随机访问方式,可以自由访问文件的任意位置。
如果需要向已经存在的文件追加内容,则应该使用此类。
他只能读写文件,不能读写其他IO
创建该类对象时,对象的文件记录指针位于0出,读写n个字节,向后移动n次
getFilePointer 获取文件记录指针当前的位置。
void seek 将文件记录指针定位到pos位置。
但是不支持向文件指定位置插入内容。如果需要插入,需要将指定位置之后的内容先写入内存,然后将插入内容追加,然后再把内存中的内容追加
java9改进的对象序列化
对象序列化的目标是将对象保存到磁盘中,或允许在网络中直接传输对象。对象序列化机制允许把内存中的java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,通过网络将这种二进制流传输到另一个网络节点。其他程序一旦获得这种二进制流,都可以将这种二进制流恢复成原来的java对象。
要实现序列化,就需要类实现两个接口
Serializable。一个标记接口,无需实现任何方法。
Externalizable接口
使用对象流实现序列化
上述接口实现其中一个就可以序列化
实现serializable接口后,要将对象序列化,第一步创建objectoutputstream对象,这是一个处理流,需要用节点流来创建对象。第二步将对象写入磁盘,调用writeobject方法。
如果反序列化,则创建objectinputstream同样是处理流。调用readobject。
反序列化仅仅是读取数据,并不是类。因此要指定java对象所属的类,否则会出异常。
反序列化无须通过构造器来初始化对象。
如果像一个文件中序列化了多个对象,则恢复对象时,按顺序。
一个可序列化对象包含多个父类时,这些父类要么有无参数的构造器,要么也是可序列化的,否则序列化时抛InvalidClassException异常。
如果父类时不可序列化的,只带有无参的构造器,父类中定义的变量值不会序列化到二进制流中。
如果一个类中有另一个引用类型的成员变量,那么这个引用类型必须是可序列化的,否则无论这个类实现序列化接口与否,都不可以序列化。
只有第一次序列化某个对象时,才会真正输出二进制文件,后面再次序列化该对象,只是输出编号(第一次输出二进制文件时也输出一个编号 )
当这个对象,在第二次序列化之前改变了,那么改变的值将不会得到序列化。反序列化后的对象的值还是没改变之前的。
java9为objectInputStream增加了setObjectInputFilter和get。。方法,可以设置序列化过滤器。当反序列化时,会执行过滤器中的checkinput方法,如果返回拒绝,则阻止反序列化,如果返回运行则序列化。
transient关键字只能修饰java的引用类型变量。被他修饰过的引用类型变量,进行序列化时会跳过。
自定义序列化
序列化时,当需要采用特定的方式对对象进行序列化,以便起到加密等的作用,或者特定的处理某个引用类型变量。而不是直接跳过。则需要实现几个方法
在序列化和反序列化过程中需要特殊处理的类应该提供如下特殊签名的方法,这些特殊的方法用以实现自定义序列化:
private void writeObject(java.io.ObjectOutputStream out)throws IOException
private void readObject(java.io.ObjectInputStream in) throws IOException,
ClassNotFoundException; private void readObjectNoData()throws ObjectStreamException;
其中write方法和read方法应该相对应,在write中特殊处理,在read中应该反处理。
并且二者的变量顺序要一致,否则不能正确的恢复对象。
还有另外一种更加彻底的自定义序列化的方法
适用writeReplace()方法,序列化对象时,可以将对象改变为其他类型的对象。该方法可以有访问修饰符。因此可以被器子类继承。
系统在序列化对象之前,会先调用该方法,返回另一个对象,然后继续先调用该方法,知道不在返回另外一个对象为止,最后调用writeObject方法。
与此方法相对应的,还有一个readResolve方法。该方法的保护性的复制整个对象。
因为java反序列化对象时,无需调用构造器,因此,反序列化的过程类似于克隆,也就是反序列化回来的对象,和序列化之前的对象,不是同一个。这与前面讲的不矛盾,前面是说序列化多次同样的对象,会存一个编号。但这个编号却与原对象不是一个对象
所以对于单例模式或者枚举类型来说,这样反序列化就会出现问题。
这时,readResolve就发挥作用了,在readObject方法之后,会调用该方法,该方法丢弃反序列化的对象,重新返回一个对象。此时可以返回源对象。
但是这个方法也有一个bug,因为这个方法也可以让子类继承。如果子类继承又没有重写,那么子类反序列化之后将是父类对象。而又不能总是让子类重写。因此对于final类,实现这个方法比较合适,否则就先将该方法设为private。
另外一种序列化机制
Externalizable接口序列化
跟前面的一样,只不过强制自定义序列化。这个接口有两个方法,必须实现。
void readExternal(ObjectInput in):需要序列化的类实现 readExternal方法来实现反序列化。该方法调用DataInput(它是ObjectInput的父接口)的方法来恢复基本类型的属性值,调用ObjectInput的readObject方法来来恢复引用类型的属性值。
void writeExternal(ObjectOutput out):需要序列化的类实现writeExternal方法来保存对象的状态。该方法调用DataInput(它是ObjectInput的父接口)的方法来保存基本类型的属性值,调用 ObjectOutput的writeObject方法来保存引用类型的属性值。
执行反序列化时,会先调用public的无参构造函数。因此实现该接口的类,必须有公共的无参构造函数。
两者的区别是
第一个可以系统自动确定如何序列化
后者需要程序员强制自定义
前者易于实现,接口继承就行,不需要实现方法
后者必须实现两个抽象方法。
前者性能略差,后者性能略好
注意的几点
1.对象的类名,实例变量都会被实例化。但是方法,静态变量,transient实例变量(瞬态实例变量)都不会被序列化。
2.不能使用static是变量不能实例化。
3.保证序列化对象的实例变量类型也是可序列化的,否则定义为瞬态变量。不然不能实例化。
4.通过文件、网络读取序列化后的对象时,必须按照实际写入的顺序。
版本
如果类更新了,再反序列化时,会因为类版本不兼容而导致反序列化失败
这是我们应该定义一个private static final的serialVersionUID属性值,该属性值用于标识该Java类的序列化版本,也就是说如果一个类升级后只要它的serialVersionUID属性值保持不变,序列化机制也会把它们当成同一个序列化版本。
但是要注意:
1.如果类的改变,只是改变了方法,静态变量,或者瞬态变量。那么不影响反序列化,因此不用改变这个id
2.如果类的改变,改变了实例变量。或者实例变量名相同,类型不同,则会反序列化失败。需要更新ID变量值。
3如果新类比旧类少实例变量,则不用改变id,可以兼任。如果新类多,也可以兼容,不改变id,但是反序列化出的新的对象中农多出的实例变量值都是null。
NIO
前面的输入输出流都是阻塞式的,并且是处理字节的,即使不是字节流,底层也是字节。因此效率不高
jdk1.4开始,提供了新的IO称为NIO。在java.nio包下
新IO采用内存映射文件的方式来处理输入输出,将文件或文件的一段区域,映射到内存中,这样可以向访问内存一样访问文件。速度要快
与新IO相关的包
java.nio 主要包含各种与Buffer相关的类
java.nio.channels 主要包含channel和Selector相关的类
java.nio.charset 主要包含于字符集相关的类
java.nio.channel.spi 主要包含于CHannel相关的服务提供者变成接口
java.nio.charset.spi 包含于字符集相关的服务提供者编程接口
Channel是对传统的输入输出系统的模拟,与传统的流处理方式不同在于他提供了一个map方法,可以将一块数据映射到内存,因此是面向块的处理
Buffer是一个容器,在饭送到Channel之前必须放到buffer中,从channel中读取的数据也必须先放入buffer,buffer允许是用Channel直接将文件的某块数据映射成buffer。
Charset类,提供了Unicode与字节序列转换。
Selector类提供了支持非阻塞的方式。
Buffer
buffer像一个数组,有各自类型,常用的是ByteBuffer和CharBuffer
Buffer是抽象类,实现类没有构造器,只有一个allocate的静态函数
capacity:缓冲区容量,创建后不可改变,不能为负值,就是一个数组。
limit:位于limit之后的数据不能读也不能写。保证不能读到null;
position:用于指明下一个可以被独处的或者写入的缓冲区位置索引
刚开始,position是0,limit=capacity。
put如数据或读入数据,position向后移动,调用flip,limit=position,是的数据固定。position=0,准备读取
调用clear,将position=0,limit=capacity,数据没有删,是的可以继续读入数据。
ByteBuffer有一个allocateDirect方法,创建直接buffer,创建成本高,但是读取效率高,适用于长期存储的buffer
还有一个mappedByteBuffer,表示将磁盘文件的部分内容或全部映射到内存中。Channel的map方法。
Channel
channel可以调用map直接将一块内容映射成buffer
不能直接访问channel只能使用buffer
需要使用节点流来getchannel,inputStream返回fileChannel等等。
字符集Charset
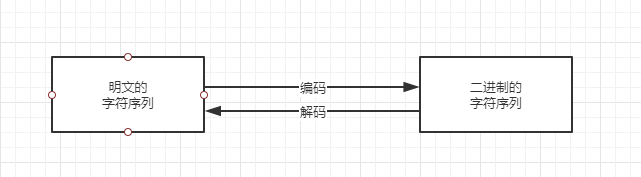
java默认使用Unicode字符集,但有些操作系统不适用Unicode字符集,那么当从系统中读取数据到java程序中时,就有可能出现乱码。
首先获取Charset对象,,然后根据对象创建Encoder编码,Decoder解码。然后调用编码让字符序列根据特定的字符集,编码成二进制,调用解码,将二进制变为字符序列。也可以直接将字符串变为二进制序列。
文件锁
多个运行的程序需要修改同一个文件,程序之家需要某种机制进行通信,使用文件锁可以有效阻止多个进程并发修改同一个文件。
NIO中,提供FileLock来支持文件锁定功能,在FileChannel中提供的lock和trylock方法可以获得FileLock对象
lock是阻塞式的,如果无法得到文件锁则阻塞,trylock非阻塞,得到返回文件锁,否则返回null
可以锁定指定内容,也可以指定共享与否。
某些平台,文件锁是建议的,即使有锁,也可以并行访问。
有些平台,不能同步地锁定一个文件并把它映射到内存中
如果两个java程序使用一个java虚拟机,则不允许对同一个文件枷锁
关闭FileChannel时,会释放虚拟机在该文件上的所有锁,因此应该避免对同一个被锁定的文件打开多个FileChannel。
NIO2
Java 7新增了如下API来访问文件
Path - 接口,代表一个平台无关的目录。提供了大量的方法来操作目录。
Paths - 工具类。所有方法都是static的。
Files - 操作文件的工具类。 提供了大量的方法来操作文件。 该类所包含的大量方法可能与我们日常一般的期望有些出入。
Files工具类提供了文件复制,读取文件,写入文件等功能。
java8循序开发者使用StreamAPI来操作文件目录和文件内容。
FileVisitor
更加优雅的方式来遍历文件和子目录
walkFileTree方法。方法中有Filevisitor参数,代表一个访问器,方法自动遍历start路径下的所有文件和子目录,遍历文件和子目录会触发FileVisitor的方法。
实际编程时,通过集成SimpleFileVisitor类来实现文件访问器。根据需要选择性的重写指定方法。
可以达到对指定目录进行搜索,直到找到未知。
使用WatchService监控文件变化。
监听文件系统的变化
通过register一个watchservice来监听,通过三个方法,获取watchkey,来实现不同的监听。
访问文件属性
NIO2提供了工具类,开发者可以简单的读取修改文件属性。
一个是view代表文件属性的视图
一个是Attribute代表文件属性的集合。通过view获取集合。