一、算法介绍
快速排序(Quick Sort):它的基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,分别对这丙部分继续进行快速排序,直至整个序列有序。
任取一个元素 (如第一个) 为中心
所有比它小的元素一律前放,比它大的元素一律后放,形成左右两个子表;
对各子表重新选择中心元素并依此规则调整,直到每个子表的元素只剩一个
①每一趟的子表的形成是采用从两头向中间交替式逼近法;
②由于每趟中对各子表的操作都相似,可采用递归算法。
二、基本步骤
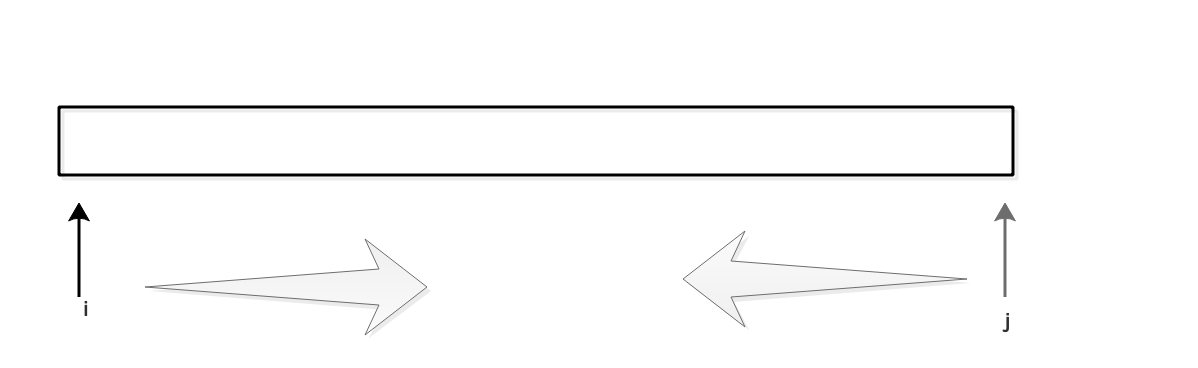
设置两个指针i,j,首先在序列里面选出一个枢纽temp出来,将j指向的数字和temp比较,如果比temp大,则减1,如果比temp小,应该把当前j指向的位置上面的数值和

三、算法分析
最好:划分后,左侧右侧子序列的长度相同,
最坏:从小到大排好序,递归树成为单支树,每次划分只得到一个比上一次少一个对象的子序列,必须经过 n-1 趟才能把所有对象定位,而且第 i 趟需要经过 n-i 次关键码比较才能找到第 i 个对象的安放位置
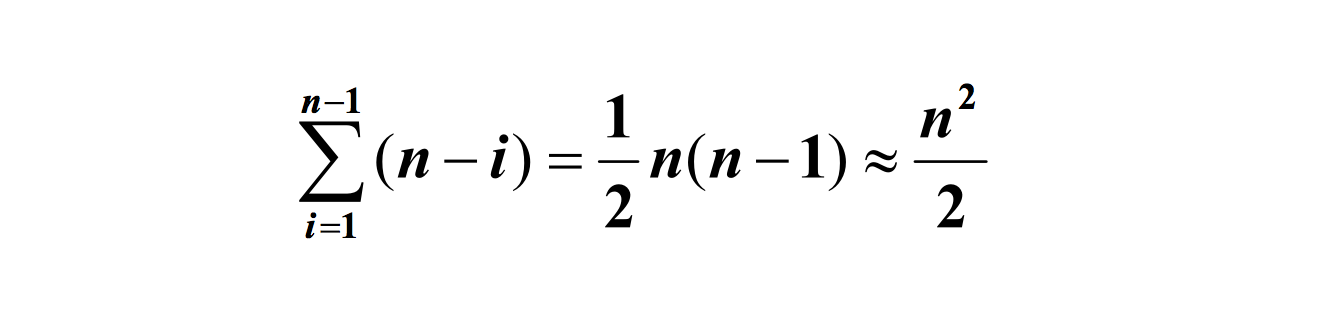
若出现各种可能排列的概率相同,则可取最好情况和最坏情况的平均情况
时间效率:O(nlog2n) —每趟确定的元素呈指数增加
空间效率:O(log2n)—递归要用到栈空间
稳 定 性: 不稳定 —可选任一元素为支点
1.如何选枢纽
由上述描述可以知道,快速排序是以枢纽的点进行来回交换,所以快速排序的排序趟数和初始的序列有关系。
所以选择快速排序的枢纽点是非常重要的,因为关系到排序的效率。
取前或后法:序列中的第一个或最后一个元素作为基准,如果输入序列(上文中的数组)是随机的,处理时间可以接受的。如果数组已经有序时,此时的分割就是一个非常不好的分割。因为每次划分只能使待排序序列减一,此时为最坏情况,时间复杂度为Θ(n^2)。而且,输入的数据是有序或部分有序的情况是相当常见的。因此,使用第一个元素作为枢纽元是非常糟糕的
随机选取基准:
这是一种相对安全的策略。由于枢轴的位置是随机的,那么产生的分割也不会总是会出现劣质的分割。在整个数组数字全相等时,仍然是最坏情况,时间复杂度是O(n2)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。
三数取中法:在快排的过程中,每一次我们要取一个元素作为枢纽值,以这个数字来将序列划分为两部分。在此我们采用三数取中法,也就是取左端、中间、右端三个数,然后进行排序,将中间数作为枢纽值。显然使用三数中值分割法消除了预排序输入的不好情形,并且减少快排大约14%的比较次数。
2.如何证明时间复杂度
1、最优情况
在最优情况下,Partition每次都划分得很均匀,如果排序n个关键字,其递归树的深度就为 [log2n]+1( [x] 表示不大于 x 的最大整数),即仅需递归 log2n 次,需要时间为T(n)的话,第一次Partiation应该是需要对整个数组扫描一遍,做n次比较。然后,获得的枢轴将数组一分为二,那么各自还需要T(n/2)的时间(注意是最好情况,所以平分两半)。于是不断地划分下去,就有了下面的不等式推断:
这说明,在最优的情况下,快速排序算法的时间复杂度为O(nlogn)。
2.最坏情况
然后再来看最糟糕情况下的快排,当待排序的序列为正序或逆序排列时,且每次划分只得到一个比上一次划分少一个记录的子序列,注意另一个为空。如果递归树画出来,它就是一棵斜树。此时需要执行n‐1次递归调用,且第i次划分需要经过n‐i次关键字的比较才能找到第i个记录,也就是枢轴的位置,因此比较次数为n(n-1)/2,最终其时间复杂度为O(n^2)。
3.平均时间复杂度
直接设对规模的数组排序需要的时间期望为, 期望其实就是平均复杂度换个说法.
空表的时候不用排, 所以初值条件就是 T(0) = 0 .所谓快排就是随便取出一个数,一般是第一个数,然后小于等于他的放左边, 大于他的的排右边.比如左边 k 个那接下来还要排: T(n - k) + T (k - 1) 的时间.然后 k 多少那是不确定的, 遍历 1~ n , 出现概率都是相等的. 另外分割操作本身也要时间 P(n) , 操作花费是线性时间 P(n) = cn , 这也要加进去, 所以一共是:

四、完整代码示例
public class QuickSort {
//任取一个元素 (如第一个) 为中心
//所有比它小的元素一律前放,比它大的元素一律后放,形成左右两个子表;
//对各子表重新选择中心元素并依此规则调整,直到每个子表的元素只剩一个
//一趟排序过程后我们返回枢纽的位置
int partition(int A[], int left, int right) {
//选择枢纽元素
int p = A[left];
while (left < right) {
//如果尾指针位置的数比枢纽数要大,移动尾指针的位置,否则就把所指示的值给首指针的位置
while (left < right && A[right] >= p) {
--right;
}
A[left] = A[right];
//如果首指针位置的数比枢纽数要小,移动首指针的位置,否则就把所指示的值给尾指针的位置
while (left < right && A[left] <= p) {
++left;
}
A[right] = A[left];
}
//此时的首尾指针已经相等,把枢纽的值赋给首尾指针相等的位置即可
A[left] = p;
return left;
}
//快速排序的递归
void Quick(int A[], int left, int right) {
//定义一个枢纽的位置
int pnode;
if (left < right) {
pnode = partition(A, left, right);
Quick(A, left, pnode - 1);
Quick(A, pnode + 1, right);
}
}
public static void main(String[] args) {
}
参考文章
https://www.jianshu.com/p/c8b1384238f7
https://www.cnblogs.com/chengxiao/p/6262208.html
https://blog.csdn.net/oohaha_123/article/details/26558363
https://www.zhihu.com/question/22393997/answer/406278523
https://www.cnblogs.com/onepixel/articles/7674659.html
欢迎关注个人技术公众号:Coder辰砂
