Lecture 13: Deep Learning
13.1 Deep Neural Network
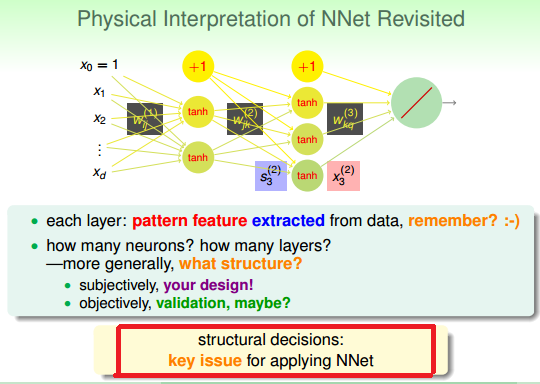
图 13-1
如何设计每一层 layer ! layer 是一层一层加上去的,还是有可能是 几层几层加上去的(CNN 肯定是几层几层加上去的)。
1) “结构决定功能”固然正确,但是如何设计结构以及结构中的参数呢。
2) 既然 nn 需要设计结构,那么学习 CNN 和 RNN 这些神经网络有什么意义? 可能每个具体问题都需要一个特定的网络。我应该要了解 CNN 和 RNN, 然后从模式识别和 NLP 中选择一个细分领域做下去。
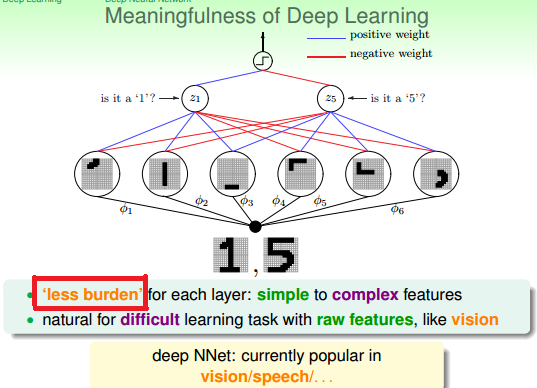
图 13-2
Less Burden 不应该是 Deep NNet 所特有吧!对任何 NNet, 单层的能力本身就很弱!那么这些弱爆的 layers 如何成为一个碉堡的 NNet 呢?

图 13-3
图 13-3 所说的道理所对,但是太抽象!来个实际点的,请看下图

图 13-4
initialization 为什么具有那么强的法力?IMHO: initialization 是给了很好的起点。如仁川登陆、如二分法。 pre-training 是怎么做到的?从前往后,还是从后往前 pre-train ?
13.2 Autoencoder

图 13-5 Autoencoder
怎么设计一个 autoencoder 呢? 比如图 13-5, 它的第二层的感知器个数可以修改,激活函数可以修改。每一层间的连接数也应该可以修改(比如第 N+1 层只连接 k 个 第 N 层的线等等。可能这种玩法不多)。
如果把每层看成是信息压缩过程中的一步,将最后一层看成是解压那肯定是对的。autoencoder 这种算是不错的方法。
来个搞笑的, CNN NNet 处理后的数据能复原?(如果不能,那就真的搞笑了)

图 13-6
autoencode 可以用与数据降维。类似的方法有 PCA, SVD, MF(MF 应该等同于 SVD)
13.3 Denosing Autoencoder

图 13-7
神经网络的表达能力很强,这代表一个结构不好的神经网络也能在 in-sample 有很好的表现。这时采取的正则化来筛选模型参数又能做到什么地步呢?
正则化不能用于筛选结构,只能结构已定情况下筛选出相关的网络参数。
对 autoencode 而言,有一种特殊的筛选方法。如图 13-8 所示

图 13-8
因为,自编码器的输入和 label 间的关系相当于只有常规机器学习中的正样本,加入的噪声相当于负样本 。对于其他 NNet 能不能做这样的处理?
13.4 Principal Component Analysis
对与 autoencode 而言,通常中间层 node 的个数都比 输入和输出层 node 个数个数少(中间层最多和输入层,输出层 node 个数一样。如果中间层 node 数多了,还不如不要)。
先研究一下激活函数为 linear 的线性编码器。

图 13-9
后续的这么太数学,就此略过
最后用一张图结束本节!

图 13-10
题外话:
T1:给跪了,林老师太强! (本节内容并不复杂,从鉴赏的角度来看。林老师简直碉堡!)
T2: 如果计算能力强大,一切都不是问题。关键在于不强大!!这个可以参考海军处理水文条件的做法!!!