一、常见的中文编码
GB2312编码是在ASCII编码基础上扩展来的,在1980年由中国国家标准总局发布,其中最主要的变化就是引入了简体中文的编码,一共容纳了包括简体中文在内的6000多个字符。
仅仅是简体中文肯定是不够用的,1995年,GBK编码在GB2312编码的基础上进行扩充,加入了繁体中文和一些符号的编码,扩充后容纳了20000多个字符。
56个民族56枝花,中华儿女56个民族不同民族之间的语言符号也有一定的差异,为了编码大团圆,2000年,GBK再一次被扩充,就产生了GB18030编码,GB18030编码不仅容纳简体中文和繁体中文,还纳入少数民族汉字,一共70000多个汉字和字符,GB18030是在GB2312和GBK的基础上扩充的,比GB2312和GBK更广阔。
二、.encode()方法和.decode()方法
.encode( )和.decode()分别称为编码方法和解码方法,字符串通过编码转换为字节码(一种二进制数据类型,如Unicode编码),字节码通过解码转换为可以被人类读懂的字符串。它们的关系如下图所示。

1.encode方法
encode方法能够将字符串转换成给定编码的字节形式,语法格式为:
str.encode(encoding=”code”,errors=”errorstype”)
encode方法对str类型数据进行处理,返回的是给定编码的字节形式;encoding设定编码的方法;errors设置所需要的错误处理方案,默认为“strict”,当发生与 Unicode 相关的编码错误时将被引发。示例如下:
str0= '爬虫俱乐部'byte0= str0.encode('gb2312') # 以gb2312编码对str0进行编码,获得bytes类型对象 print(byte0)
结果如下:

输出结果为“爬虫俱乐部”的二进制编码。
2.decode方法
decode方法将给定编码的字节码解码为utf-8编码的字符串,语法格式为:
bytes.decode(encoding=”code”,errors=”errorstype”)
decode方法对bytes类型数据进行处理,返回的是字符串;encoding设定解码的方法,设定的解码方式应该与bytes的编码方式一致;errors设置所需要的错误处理方案,默认为“strict”,当发生与 Unicode 相关的解码错误时将被引发。示例如下:
str0= '爬虫俱乐部' byte0= str0.encode('gb2312') # 以gb2312编码对str0进行编码,获得bytes类型对象 str1=byte0.decode('gb2312')# 对gb2312编码的byte0进行解码,获得str类型对象 print(str1)
结果如下:

成功将“爬虫俱乐部”的二进制编码解码为字符串“爬虫俱乐部”。
三、网络爬虫应用
前面已经为大家介绍过,默认情况下,Python 源码文件以 UTF-8 编码方式处理。但并非所有的网页的源代码都是UTF-8 编码的,较新的网页一般为UTF-8编码,一些有年代的网站可能是GB2312等其他编码方式,这样我们获取的网页源代码中的中文将出现乱码,或者post的表单需要使用GBK编码的字节流形式传送,encode和decode就能为我们解决问题。以爬取新浪财经高管任职信息为例。在本例中,为了阅读简便我们选取平安银行的高管任职信息为例。新浪财经的网页源代码为GB2312编码,所以当我们直接打印网页源代码的文本格式数据时,中文就会显示乱码。
import requests #导入requests模块url="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml" text=requests.get(url).text#通过requests 模块的get方式将源代码赋给text print(text)
结果如下:

从输出结果可知,源代码中的中文部分都显示为乱码。用decode对源代码进行解码。我们已经知道GB18030是在GB2312的基础扩充且更全面,所以这里选取GB18030编码进行解码。
byte=text.decode(encoding="gb18030",errors="strict") print(byte)
结果如下:
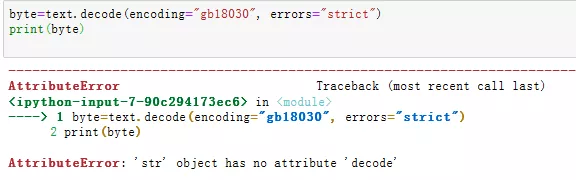
发生报错,在介绍decode方法时说过,它的作用对象是bytes类型,但这里的.text是解码后的字符串类型,并且默认使用Unicode编码解码,因此.text不再适用。此时,我们需要提取原生字符串,即调用.content而非.text,然后使用decode进行解码。
import requestsurl="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml" content=requests.get(url).content#将源代码的编码字节赋给contentbyte=content.decode(encoding="gb18030",errors="strict") print(byte)
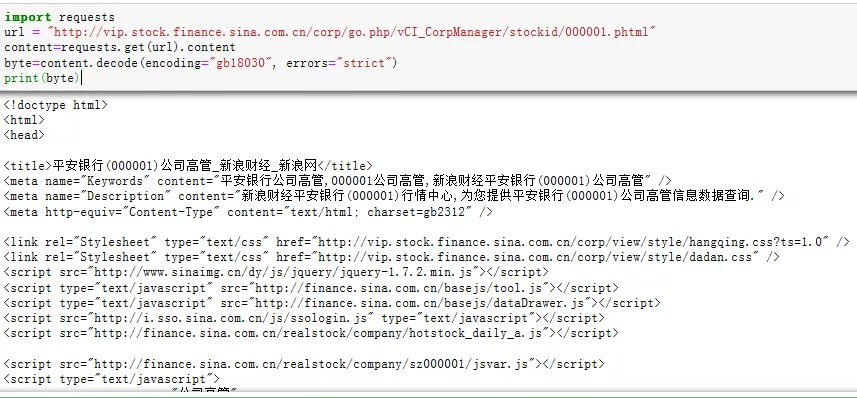
调用content属性将源代码的字节码赋给content,再对content进行解码就能得到中文正常显示的源代码啦。当然,此处也可以通过response对象自带的encoding属性得到正确的内容。
import requestsurl="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml" text=requests.get(url)text.encoding= "gb18030" print(text.text)
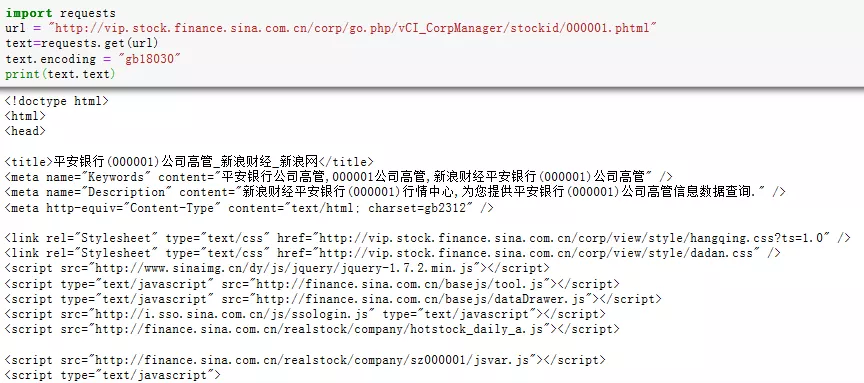
接下来只需要对得到的正常显示的源代码文件进行字符串处理就可以得到我们想要的信息啦。
摘自:微信公众号: