作业:
打开百度,搜索selenium,找到第一页到第十页搜索结果标题不包含selenium的标题,统计数量,并打印标题出来
在实现过程中出现的难点:翻页过程中元素过期,无法定位到翻页元素
解决方案一:
http://blog.sina.com.cn/s/blog_65bc768e0102ve78.html
解决方案二:刷新页面重新获取元素,思路来源:https://blog.csdn.net/freesigefei/article/details/50501961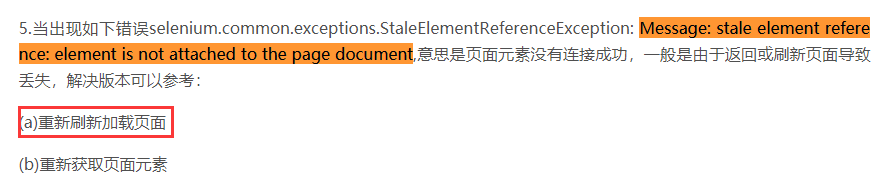
实现代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/5/7 22:19
# @Author : fguo1029
# @File : findkw.py
from selenium import webdriver
import time
#定位搜索结果的标题
def find_one_page(list_one_page=[], kw=''):
driver.find_element_by_css_selector('.s_ipt').send_keys(kw)
driver.find_element_by_css_selector('#su').click()
time.sleep(2)
# string_all = driver.find_elements_by_css_selector("div[srcid='1599']")
string_all = driver.find_elements_by_css_selector("h3>a[target='_blank'] ")
i = 0
j = 0
for string_one in string_all:
baidu_href = string_one.get_attribute('href')
kw_string = string_one.get_attribute('text')
kw_string1 = kw_string.lower()
if 'baidu' in baidu_href:
if kw in kw_string1:
i += 1
# print(kw_string, i)
else:
j += 1
if kw_string.strip() == '':
pass
else:
list_one_page.append(kw_string)
return list_one_page
#翻页功能
def find_kw_not_in_page(kw='', page=0):
flag = 0
list_all_page = []
while flag < page:
find_one_page(list_all_page, kw)
flag += 1
print(' looking for %s in page %d ' % (kw, flag))
driver.refresh()
driver.implicitly_wait(2)
driver.find_element_by_css_selector("div#page> :last-child").click()
driver.implicitly_wait(2)
return list_all_page
if __name__ == '__main__':
driver = webdriver.Chrome('G:Pythonpython3chromedriver.exe')
driver.get('http://www.baidu.com')
driver.implicitly_wait(2)
titles = find_kw_not_in_page('selenium', 10)
for i in titles:
print(i)
print('total titles numbers is %d' % len(titles))
time.sleep(2)
print('try to close chrome')
driver.quit()