Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板
步骤2:编写Spider
步骤3:编写Item Pipeline
步骤4:优化配置策略
Scrapy爬虫的数据类型
Request类;Response类:Item类
Request类
class scrapy.http.Request()
Request对象表示一个HTTP请求
由Spider生成,由Downloader执行
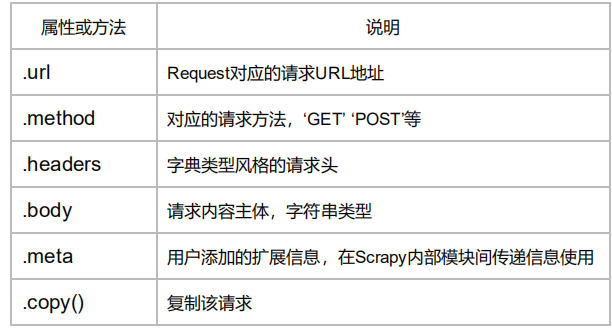
属性和方法
url method headers body meta copy
callback(callable):指定一个回调函数,该回调函数以这个request的response作为第一个参数。如果未指定callback,则默认使用spider的parse()方法。
Response类
class scrapy.http.Response()
Response对象表示一个HTTP响应
由Downloader生成,由Spider处理
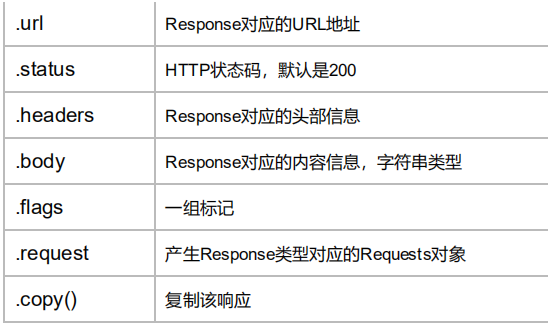
属性和方法
Item类
class scrapy.item.Item()
Item对象表示一个从HTML页面中提取的信息内容
由Spider生成,由Item Pipeline处理
Item类似字典类型,可以按照字典类型操作
Scrapy爬虫提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法
Beautiful Soup
lxml
re
XPath Selector
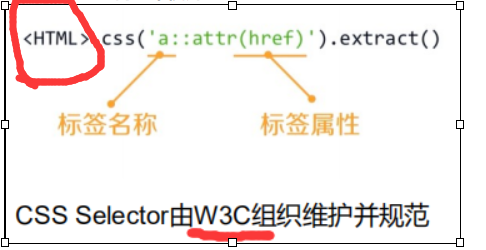
CSS Selector
CSS Selector的基本使用