
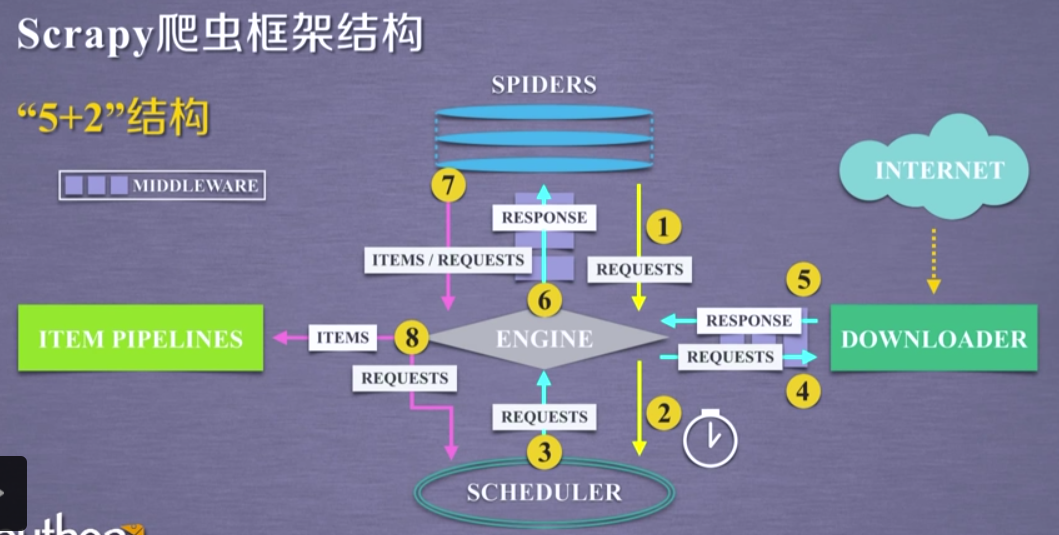
5+2 的结构
Scrapy爬虫框架解析
Engine模块(不需要用户修改):控制所有模块之间的数据流;根据条件触发事件
Downloader模块(不需要用户修改):根据请求下载网页
Scheduler模块(不需要用户修改):对所有爬取请求进行调度管理
Downloader Middleware中间键
目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应用户可以编写配置代码
Spider模块(需要用户编写配置代码)
解析Downloader返回的响应(Response)
产生爬取项(scraped item)
产生额外的爬取请求(Request)
Item Pipelines模块(需要用户编写配置代码)
以流水线方式处理Spider产生的爬取项
由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型
可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
Spider Middleware中间键
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
用户可以编写配置代码
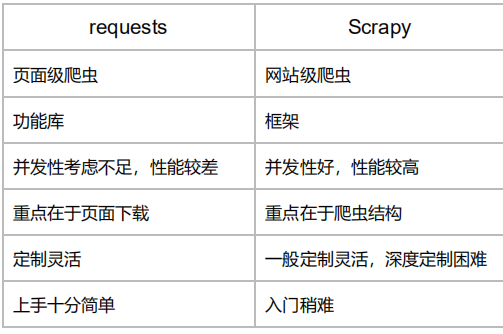
requests库和Scrapy爬虫的比较
相同点
两者都可以进行页面请求和爬取,Python爬虫的两个重要技术路线
两者可用性都好,文档丰富,入门简单
两者都没用处理js、提交表单、应对验证码等功能(可扩展)
不同点
选用哪个技术路线开发爬虫

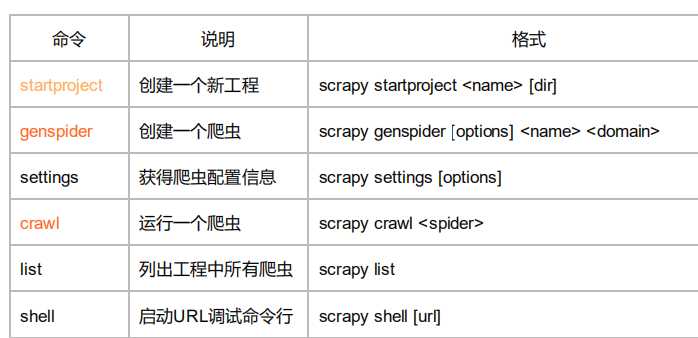
Scrapy爬虫的常用命令
Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrapy命令行
为什么Scrapy采用命令行创建和运行爬虫
命令行(不是图形界面)更容易自动化,适合脚本控制
本质上,Scrapy是给程序员用的,功能(而不是界面)更重要
一个实例
演示HTML页面地址:http://python123.io/ws/demo.html
文件名称:demo.html
产生步骤
步骤1:建立一个Scrapy爬虫工程
scrapy startproject python123demo
生成的工程目录

步骤2:在工程中产生一个Scrapy爬虫
cd python123demo > scrapy genspider demo python123.io
demo.py文件
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider):必须继承于scrapy.Spider name = 'demo' allowed_domains = ['python123.io']#只能爬取该域名一下的内容 start_urls = ['http://python123.io/'] def parse(self, response): pass
# parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求
步骤3:配置产生的spider爬虫
# -*- coding: utf-8 -*- import scrapy class DemoSpider(scrapy.Spider): name ='demo' allowed_domains = ["python123.io"] start_urls = ['https://python123.io/ws/demo.html'] def parse(self,response): fname = response.url.split('/')[-1] with open(fname,'wb') as f: f.write(response.body) self.log('Saved file %s.' % fname)
步骤4:运行爬虫,获取网页
scrapy crawl demo
