import requests r = requests.get('http://www.baidu.com') print(r.status_code) r.encoding = 'utf-8'#不然会乱码 print(r.text)
200
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/
www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class="head_wrapper"> <div class="s_form"> <div class="s_form_wrapper"> <div id=lg> <img hidefocus=true src=//www.baidu
.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class="fm"> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hi
dden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class="s_ipt" value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn
_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class="mnav">新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class="mnav">hao123</a> <a
href=http://map.baidu.com name=tj_trmap class="mnav">地图</a> <a href=http://v.baidu.com name=tj_trvideo class="mnav">视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class="mnav">贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/log
in.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class="lb">登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.locat
ion.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');</script> <a href=//www.baidu.com/more/ name=tj_briicon class="bri" style="display: block;">更多产品</a> </div> </div> </div> <di
v id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http:/
/jianyi.baidu.com/ class="cp-feedback">意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>

GET
Requests库的7个方法除了request(),其它6个都是调用requests()实现的
r = requests.get(url)
构造一个向服务器请求资源的Requests对象(python 是区分大小写的)
返回一个包含服务器资源的Response对象


import requests r = requests.get('http://www.baidu.com') print(r.status_code) # r.encoding = 'utf-8' # print(r.text) print(type(r)) print(r.headers)
200
<class 'requests.models.Response'>
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Co
ntent-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sat, 16 May 2020 07:36:02 GMT', 'Last-Modified':
'Mon, 23 Jan 2017 13:28:24 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max
-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}


ISO-8859-1不能解析中文
原则来讲apparent_encoding 比encoding 更准确


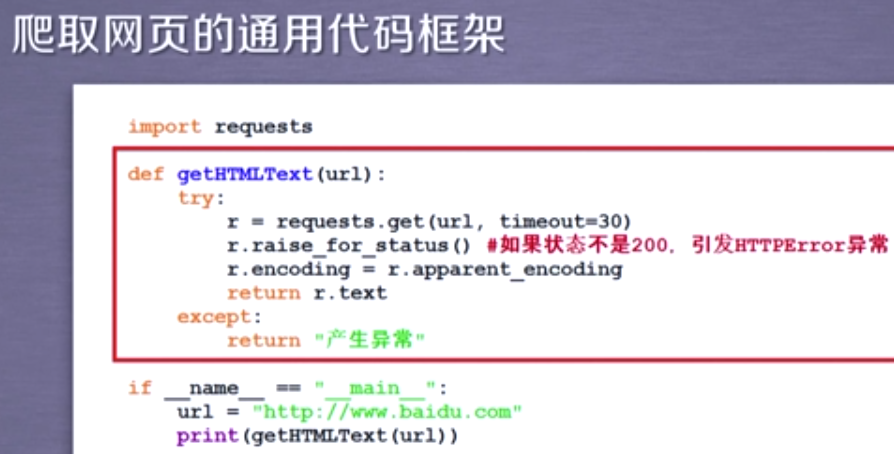
import requests def getHtmlText(url): try: r = requests.get(url,timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return '产生异常' if __name__ == '__main__': url='www.baidu.com/' print(getHtmlText(url))

HTTP ,Hypertext Transfer Protocol ,超文本传输协议
HTTP是一个基于‘请求与响应’ 模式的、无状态的应用层协议


Http 协议对资源的操作


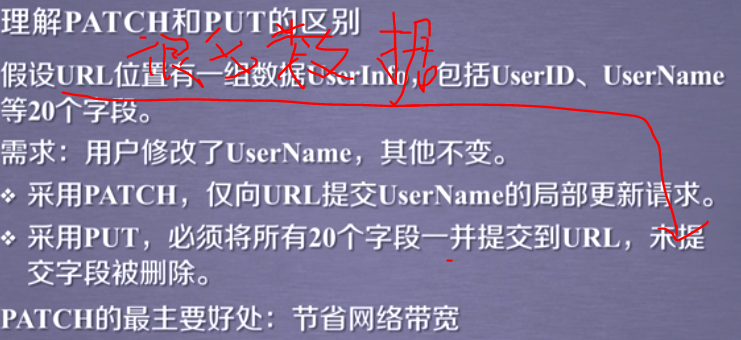
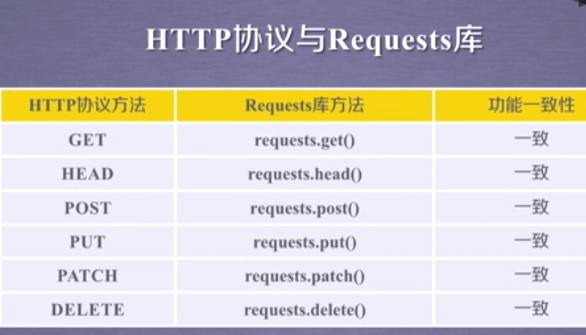


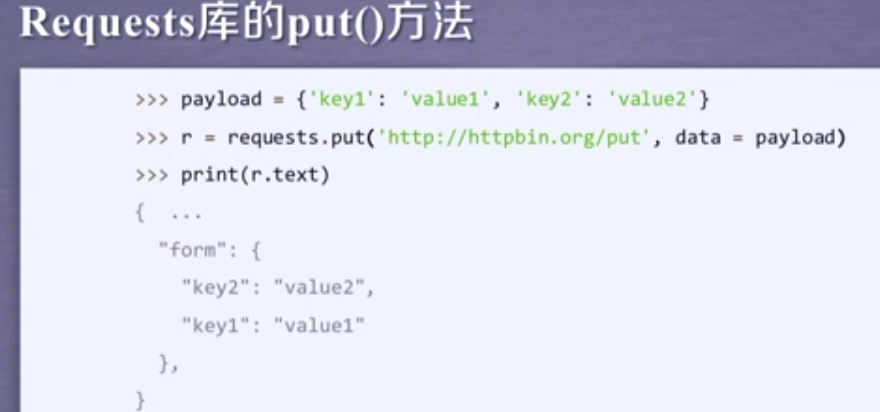
PUT 和 POST 方法类似,但PUT 可以将原有的数据覆盖
Requests

params

kv ={'k1':'1','k2':'2'}
r = requests.request('GET','http://python123.io/ws',params=kv)
print(r.url)
https://python123.io/ws?k1=1&k2=2
data

JSON

headers
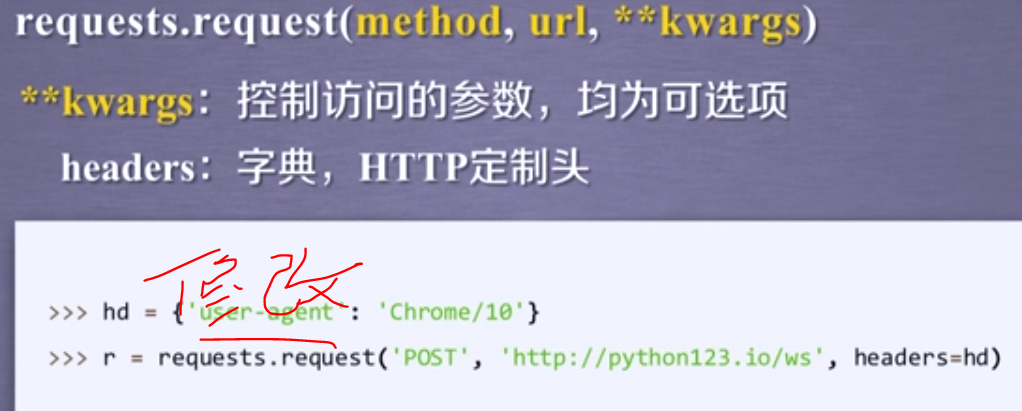
修改HTTP头部的user-agent
cookies
auth

files

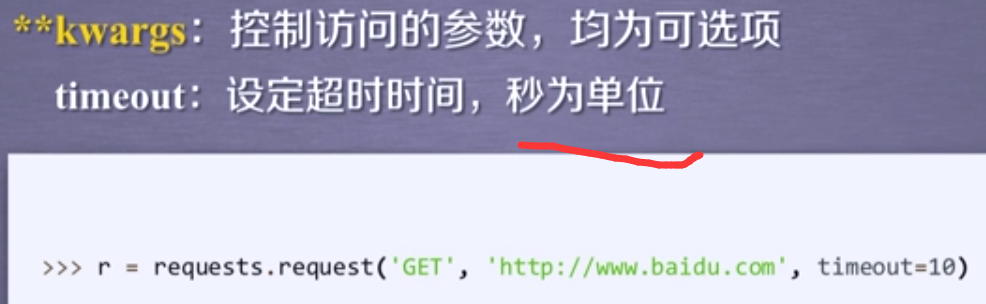
timeout
proxies
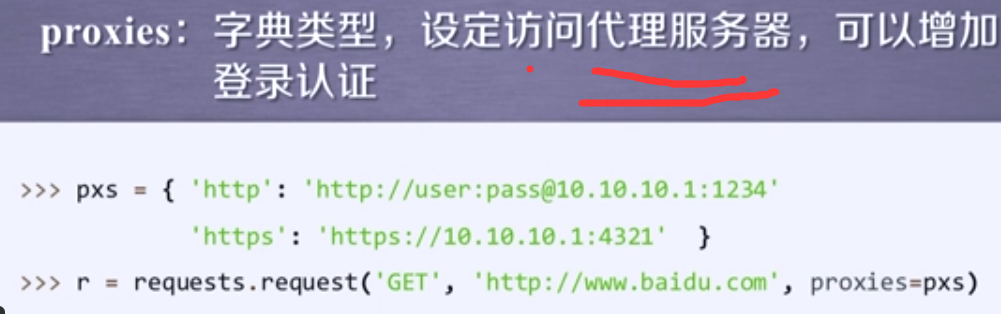
可以有效隐藏拥护爬取网页的原IP地址,能够有效的防止对爬虫的逆追踪
allow_redirects,stream,verify,cert

总结
request

get 最常用

head

post

put

patch

delete
