聚类 非监督学习的算法 从未标记的数据中学习。所以,在非监督学习中我们要做的是给这种 没有标记的训练集合一个算法并且通过算法来为我们定义一些数据的结构。 对于这种结构的数据集,我们通过算法来发现他们
就像被分成两个聚类的点集 因此对于一种算法能够找到 被圈出来的类别,就称为聚类算法
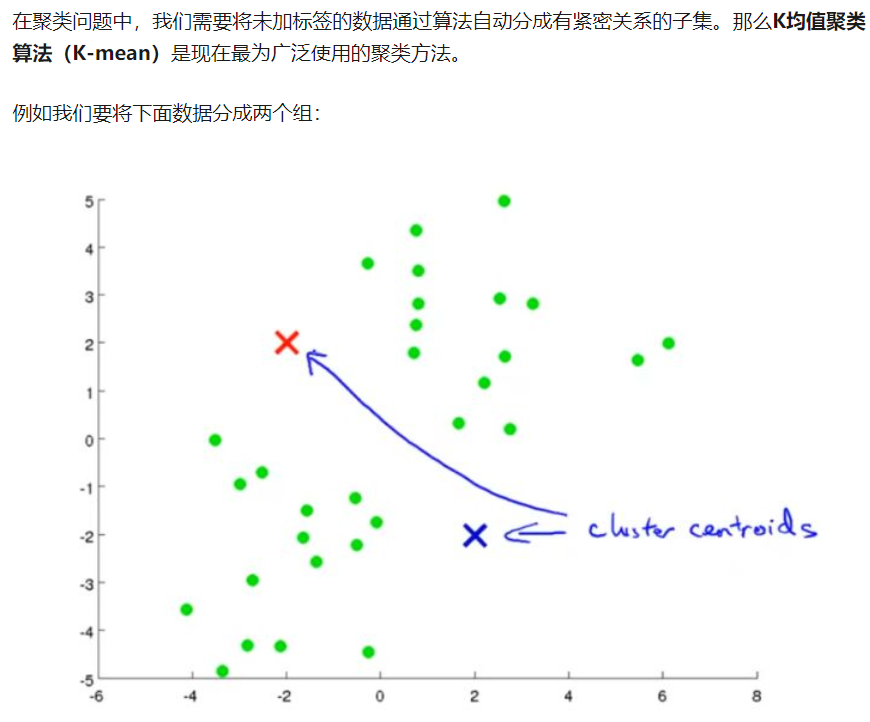







比如说 到目前为止 我们的K均值算法 都是基于一些像图中所示的数据
有很好的隔离开来的 三个簇 然后我们就用这个算法找出三个簇
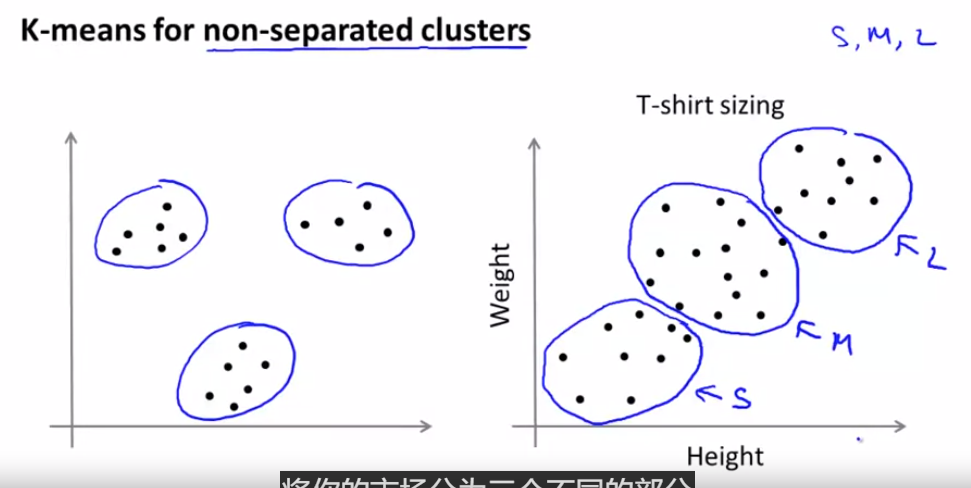
但是事实是 K均值经常会用于 一些这样的数据 看起来并没有 很好的分来的 几个簇
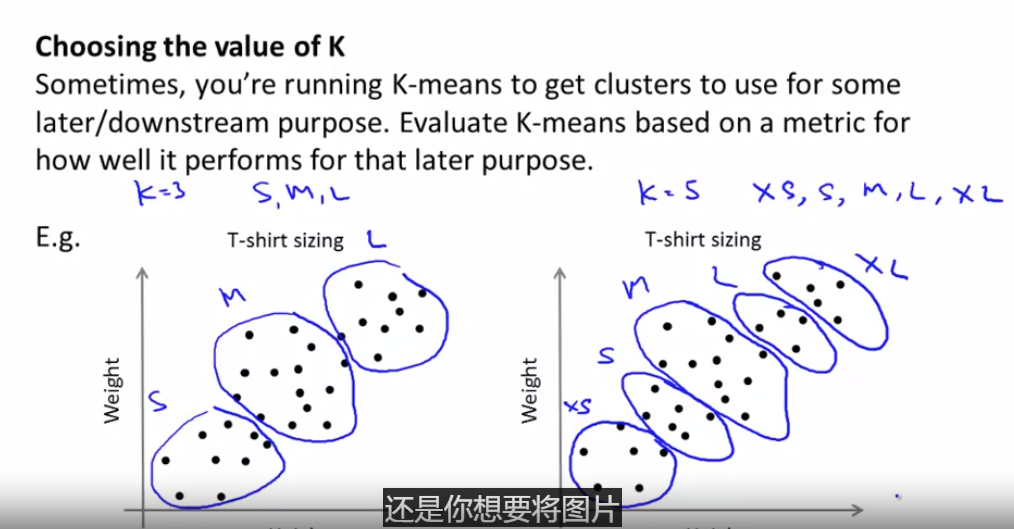
这是一个应用的例子 关于T恤的大小
优化对象


而我们上面第一个循环进行簇分类,实际上就是对代价函数J进行最小化 而
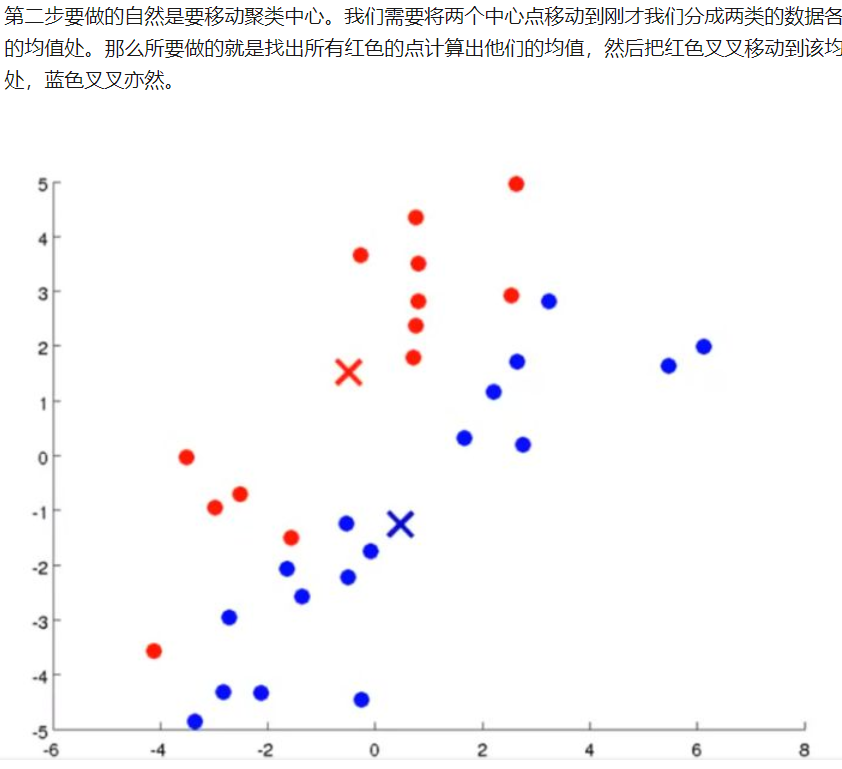
保持不变的操作。第二个循环进行移动聚类中心,实际上就是对代价函数J进行最小化
而保持
不变的操作。
所以代价函数J也被称为失真函数,我们可以在调试K均值聚类计算的时候可以看其是否收敛来判断算法是否正常工作。
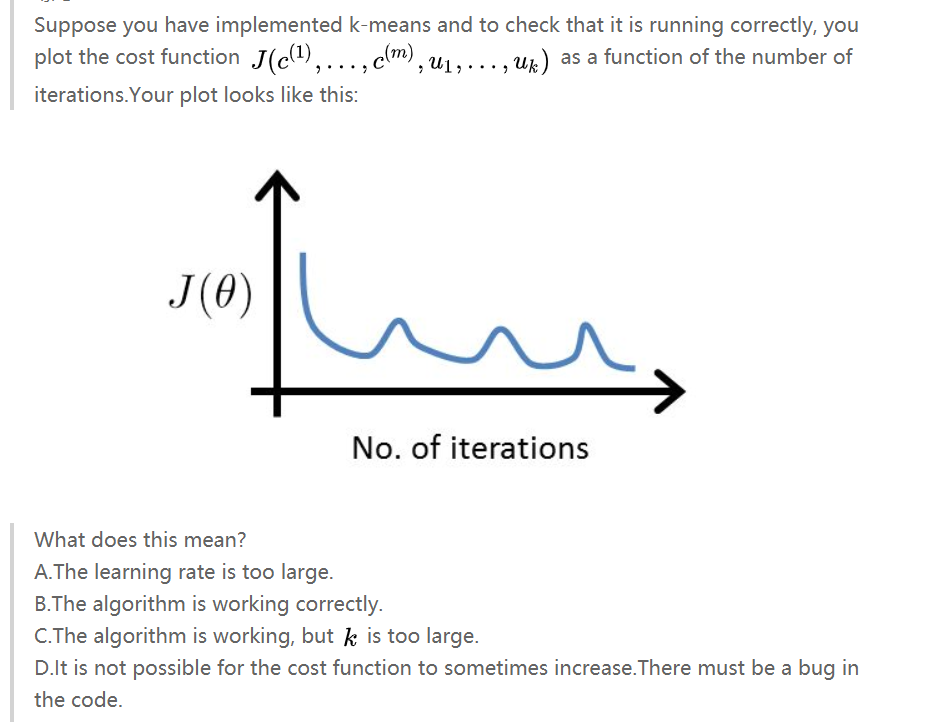
分析:代价函数应该随着迭代的次数而收敛的,图上出现震荡那说明是出现问题了。
随意初始化
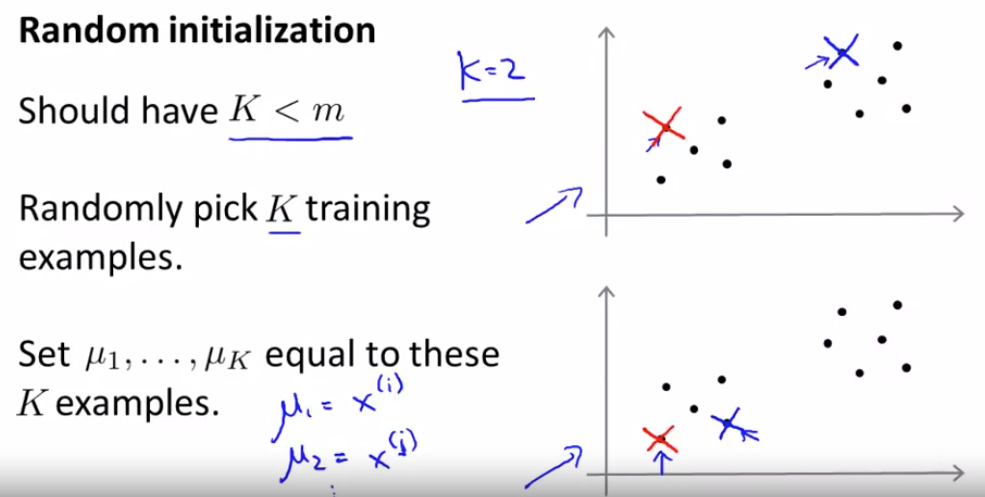



选择簇类的数目