字符编码
Ascill:字母,数字,特殊字符:一个字节,8位
Unicode:16位,2个字节;后升级32位,4个字节(中文英文都是)
utf-8:最少用8位表示,英文字母8位,1个字节
欧洲16位,2个字节
中文24位,3个字节
gbk:中文2个字节,英文字母1个字节
计算机系统通用的字符编码工作方式:
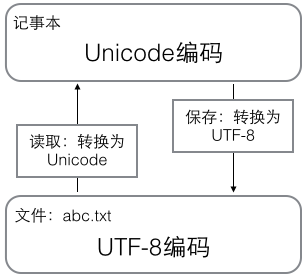
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
(1)用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
(2)浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
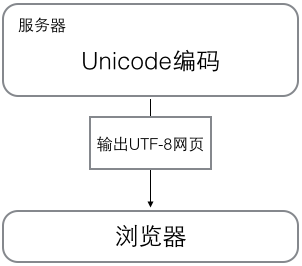
所以会看到很多网页的源码上会有类似如下信息,表示该网页正是用的UTF-8编码。
<meta charset="UTF-8" />
字符串
(1)字符和整数的转换
对于单个字符的编码,Python提供了ord()函数:字符 --> 整数, chr()函数:整数 --> 字符,如下:
>>> ord('A') 65 >>> ord('中') 20013 >>> chr(66) 'B' >>> chr(25991) '文'
(2)encode和decode
python内部的字符串一般都是 Unicode编码。代码中字符串的默认编码与代码文件本身的编码是一致的。所以要做一些编码转换通常是要以Unicode作为中间编码进行转换的,即先将其他编码的字符串解码(decode)成 Unicode,再从 Unicode编码(encode)成另一种编码。
- decode(解码) 的作用是将其他编码的字符串转换成 Unicode 编码,eg name.decode(“GB2312”),表示将GB2312编码的字符串name转换成Unicode编码
- encode (编码)的作用是将Unicode编码转换成其他编码的字符串,eg name.encode(”GB2312“),表示将unicode编码的字符串name转换成GB2312编码
(3)len函数
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len('ABC') 3 >>> len('中文') 2
>>> len(b'ABC') 3 >>> len(b'xe4xb8xadxe6x96x87') 6 >>> len('中文'.encode('utf-8')) 6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
(4)格式化
(1)最基础的是通过占位符输出格式化的字符串,用%实现:
>>> 'Hello, %s' % 'world' 'Hello, world' >>> 'Hi, %s, you have $%d.' % ('Michael', 1000000) 'Hi, Michael, you have $1000000.'
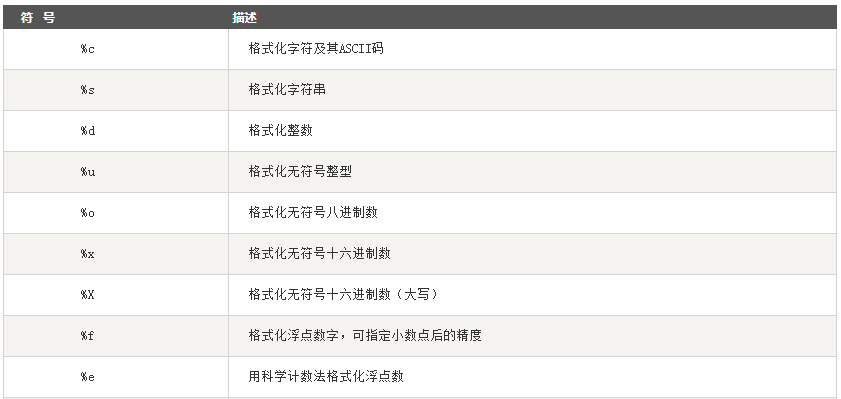
常用的字符串格式化符号:
(2)format()
用传入的参数依次替换字符串内的占位符{0},{1}...,不过这种方式写起来比%要麻烦得多。
详见大佬的博客 https://www.cnblogs.com/liwenzhou/p/8570701.html(Python中应该使用%还是format来格式化字符串?)
① format 函数可以接受不限个参数,位置可以不按顺序:
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
② 也可以设置参数:
#!/usr/bin/python # -*- coding: UTF-8 -*- print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com")) # 通过字典设置参数 site = {"name": "菜鸟教程", "url": "www.runoob.com"} print("网站名:{name}, 地址 {url}".format(**site)) # 通过列表索引设置参数 my_list = ['菜鸟教程', 'www.runoob.com'] print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的
输出结果为:
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
网站名:菜鸟教程, 地址 www.runoob.com
③ 也可以向 str.format() 传入对象:
#!/usr/bin/python # -*- coding: UTF-8 -*- class AssignValue(object): def __init__(self, value): self.value = value my_value = AssignValue(6) print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
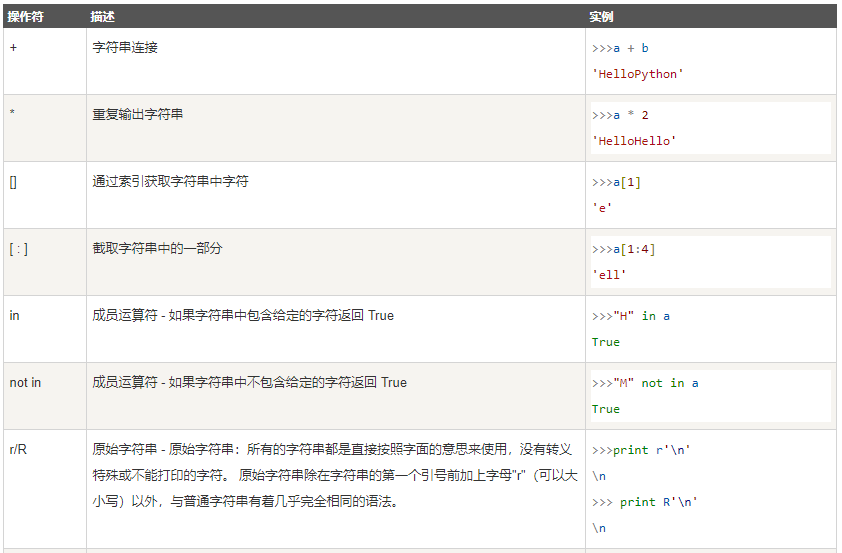
(5)运算符
下表实例变量 a 值为字符串 "Hello":
(6)join() 方法:用于将序列中的元素以指定的字符连接生成一个新的字符串
s = "'alex',[12,3,45],3" s1 = '_'.join(s) s2 = '+'.join(s1) #从前往后加入 print(s1) print(s2) 运行结果: '_a_l_e_x_'_,_[_1_2_,_3_,_4_5_]_,_3 '+_+a+_+l+_+e+_+x+_+'+_+,+_+[+_+1+_+2+_+,+_+3+_+,+_+4+_+5+_+]+_+,+_+3
(7)split() 方法:字符串分割,转换成列表
# str.split(str="", num=string.count(str)): # str:分隔符,默认为所有的空字符,包括空格、换行( )、制表符( ); # num -- 分割次数 s = "'alex',[12,3,45],3" s1 = s.split() print("无参数split",s1) s2 = s.split('3',1) print("带参数split",s2) 运行结果: 无参数split ["'alex',[12,3,45],3"] 带参数split ["'alex',[12,", ',45],3']