Apache Hadoop,一个稳定 可扩展的分布式计算开源软件。尽管Hadoop版本更新快,但大版本仅包括两个(1和2),Hadoop2多出一层资源管理器Yarn提高了资源了利用率。
核心模块:
Hadoop Common、HDFS、Hadoop YARN、Hadoop MR
Hadoop Common:为其余模块提供支持实用程序,是整体Hadoop项目的核心
HDFS:提供对应用程序数据的高吞吐量访问(Google GFS),将大小不一的众多文件切成大小相同的数据块Block(默认128M),以多副本的方法存在不同集群节点中。
YARN:作业调度与集群资源管理框架。使得多种计算框架可以运行在同一个集群中。
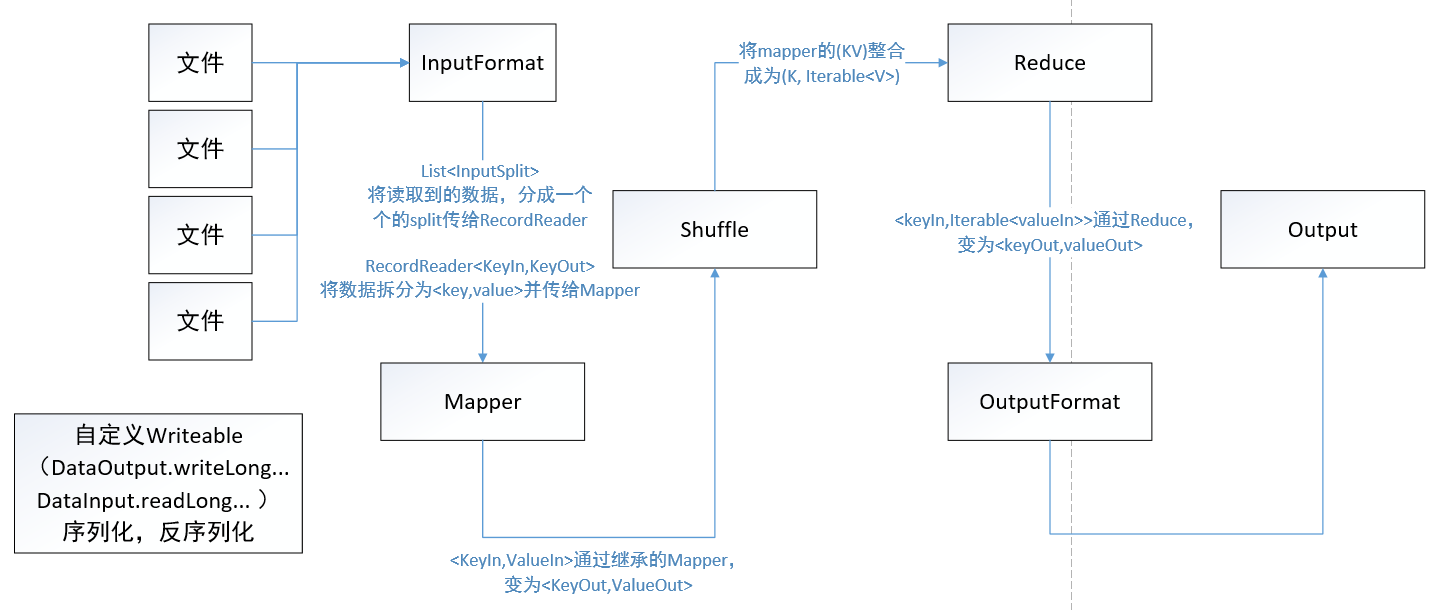
MR:MapReduce从HDFS中取出数据块进行分片,而后对每一个分片进行Mapper任务,将Mapper计算的结果通过Reducer进行汇总计算,得到最终的输出。
其余模块:HBase(实施读写分布式的面向列的非关系型数据库)、Hive(基于Hadoop的一个提供数据汇总和特定查询的数据库基础架构,将数据文件—>数据库表,HiveSQL)、Mahout(数据挖掘库)、Spark(采用内存分布数据集,相比MapReduce快很多)、Zookeeper(封装复杂且易出错的关键服务,提供简单易用的接口系统)
MapReduce工作原理
用户先创建一个Map函数处理一个基于键值对的数据集合,输出中间的Key-Value数据集合。然后再创建一个Reduce函数来合并所具有的相同Key的Value。
通过MapReduce模型接口,实现在大量普通的PC上进行高性能计算(大数据管理、分析、清洗)。
MR流程:
- 数据分片,每个输入分片针对一个Map任务,输入分片记录的是数据长度和位置数据(Defalult)
- Map过程,Map的数目通常是由输入数据的大小决定的,一般就是输入数据的Block块数。正常的并行规模是每个节点10-100个Map,
Mapper/Reducer:通过run方法,调用setup(预处理)、map/reduce(我们重载的),和cleanup(做最后的处理),由Context记录了map执行的上下文,是作为map和reduce执行中各个函数的一个桥梁
HDFS原理
文件线性切割成Block(各块包括offset),把Block分散存放在集群节点中,Block设置副本数但副本数不要超过节点数,且若是个常用的数据,副本数可以设置更多以防所有程序都在一个节点上跑。
HDFS体系结构为主从架构,由一个NameNode和一定数量的DataNode组成。对于CS架构中,Server包括了NameNode跟DataNode,Client为HdfsClient
- 主节点负责维护MetaData(size/offset/...),从节点负责处理具体的文件数据。
- 主节点单独一个服务器放守护进程。从节点在其余服务器上,具体维护本节点资源信息
- 从节点隔一定时间向主节点发送心跳,提交本节点管理的Block列表(从节点:我还活着,我挂了我也会告诉你)(3秒一次心跳,但如果10分钟以后还没消息,那你是真的死了,复制到别的地方去吧)
- Client向NameNode发送需求,通过主节点中的Block清单,返回有需求的数据的DataNode的地址,Client自己去这个DataNode拿数据(Client与DataNode交互Block数据)
- 切割后的数据块以文件的形式存在DataNode的某个目录下
- DataNode里头也有一些元数据信息,因为需要保证下载下来的文件是完整的,如果不完整,您去别的地下吧。
由于主节点管理许多个从节点,所以要求处理速度快,所以不和磁盘交换 ——> NameNode存储是基于内存存储的(MetaData存在内存里)。缺点:掉电易失。因此通过持久化工作保存NameNode信息:
- 持久化别的信息都存,Block位置信息不存。(数据恢复的时候由活着的DataNode汇报)
- 存在fsimage中(Serializable)(写得慢,重来做得快,恢复时用它)或通过EditsLog记录对metadata的操作日志,恢复后重复做(写起来快,重来做的慢,平时写用它)
- 通过折中的方法来做,会把fsimage和Editslog在时间(checkPoint)和大小(64M)的条件下进行合并。具体操作把这两个文件发送给SecondNameNode在这里边做完再送回来。(毕竟主节点已经很忙了,再做合并工作效率低)
数据上传:第一个找个不忙的节点上传,第二个找个不同机架的节点,第三个找和第二个点同机架的不同节点(都是一个机架掉电就坏了)
写流程:
- 文件Split
- ClientNode告诉NameNode要创建个块,NameNode分配了地址和元数据(DataNode列表),ClientNode:“收到”。
- 在ClientNode里创建一个FSDataOutputStream,传给第一个DataNode(仅第一个节点对其负责),对于之后的DataNode,通过Pipeline of DataNode相互传
- DataNode收到FSDataOutputStream的第一个块传完后,给ClientNode汇报完成,ClientNode向NameNode汇报完成,开始第二块的传输(Pipeline之间还没传完,不过没关系的)
读流程:同理,CN向NN请求DN列表,通过FSDataInputSteam向各个点读文件并进行MD5验证完整性
HDFS常用命令及API操作
具体访问为三种方式,API、Web UI和命令行
命令行:具体命令看官网doc,http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
- 读文件 hadoop fs -cat /usr/test/wordCount/wordcount1.txt
- 复制文件 hadoop fs -cp /user/hadoop/file1 /targetPath1 /targetPath2
- 复制到本地 hadoop fs -get /user/hadoop/file localfile
- 本地上传 hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- 看文件(夹)信息 hadoop fs -ls /user/hadoop/file1(targetPath, nonexistfile)
- mkdir hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- 移动文件 hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- 删 hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir (rm rmr 记得配trash)
API:不说了,读读源码就完事了
YARN原理
(......待续)