JMM内存模型
JMM即Java内存模型(Java Memory Model)。可以理解为它是一种抽象出来的硬件存储模型的规范。
根据JMM的设计,系统存在一个主内存(Main Memory),Java中所有变量都储存在主存中,对于所有线程都是共享的。每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是在工作内存中进行,线程之间无法相互直接访问,变量传递均需要通过主存完成。
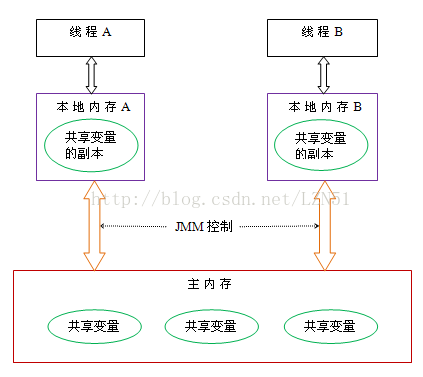
(图片来源于网络)
JVM内存模型
主要包括:堆,虚拟机栈,本地方法栈,方法区和程序计数器。
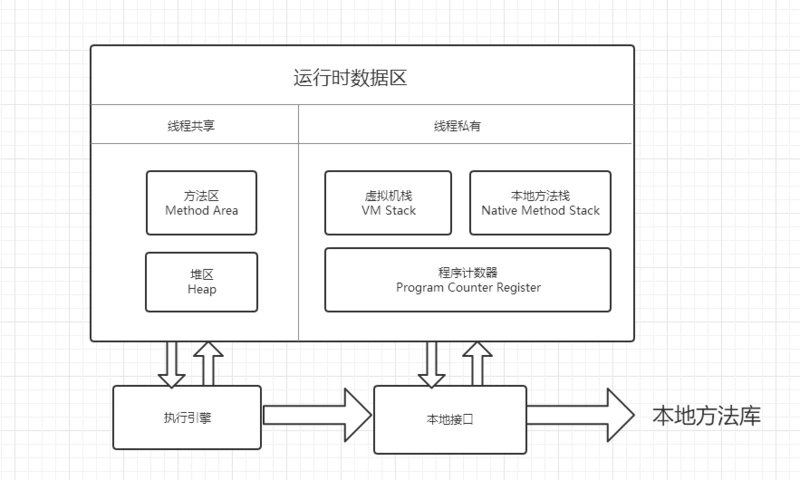
JMM内存模型与JVM内存模型的关系
JMM定义了一种模型规范,而JVM就是基于这中规范实现的一种内存模型划分方式。
jmm中的主内存、工作内存与jvm中的堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来,那从变量、主内存、工作内存的定义来看,主内存主要对应于Java堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域。从更低层次上说,主内存就直接对应于物理硬件的内存,而为了获取更好的运行速度,虚拟机(甚至是硬件系统本身的优化措施)可能会让工作内存优先存储于寄存器和高速缓存中,因为程序运行时主要访问读写的是工作内存。
JVM内存结构
JVM内存结构主要有三大块:堆内存、方法区和栈
https://www.cnblogs.com/ityouknow/p/5610232.html
JVM的基本结构(组成部分)
类加载子系统
运行时数据区(内存结构:堆、方法区和栈,本地方法栈,程序计数器)
执行引擎

JVM调优
所谓调优主要的其实就有两个点:用户卡顿时间(用户体验)、吞吐量(其实就是CPU运行用户代码的时间站CPU总消耗时间的比值。提升吞吐量)
新生代:采用标记复制算法(因为这个区大多存活几率比较低)
老年代:采用标记整理/标记清除(大多存活几率较高)
Serial:串行的,会出现stop the world,但是没有线程交互的开销。具有较高的单线程收集效率。(运行在客户端模式下的虚拟机不错的选择)
ParNew:其实就是Serial的多线程版本(许多server模式下虚拟机的首要选择),可以和CMS配合工作。
Parallel Scavenge:类似于ParNew,关注点是吞吐量(高效利用CPU)。CMS关注点更多的是用户线程停顿时间(提升用户体验);jvm默认的收集器。
第一次调优,设置Metaspace大小:增大元空间大小-XX:MetaspaceSize=64M -XX:MaxMetaspaceSize=64M
第二次调优,增大年轻代动态扩容增量(默认是20%),可以减少YGC:-XX:YoungGenerationSizeIncrement=30
Serial Old:Serial收集器的老年代版本
Parallel Old:Parallel Scavenge收集器的老年代版本。
CMS:收集器是一种以获取最短回收停顿时间为目标的收集器。(jdk9要被淘汰了)
G1:基本都用G1;是一款面向服务器的垃圾收集器,主要针对多核及大容量内存的机器,满足GC停顿时间要求的同时还具备高吞吐量性能的特征。使用Region划分内存。
并行与并发
分代收集
可预测的停顿
第一次调优,设置Metaspace大小:增大元空间大小-XX:MetaspaceSize=64M -XX:MaxMetaspaceSize=64M
第二次调优,添加吞吐量和停顿时间参数:-XX:GCTimeRatio=99 -XX:MaxGCPauseMillis=10
可以根据相应命令导出日志,使用工具再进行分析(比如GCeasy)。