kafaka
broker:就是一个节点
topic:消息主题,对数据进行归类
partion:分区,一个topic对应多个分区(具体分区数需要根据业务需求计算,比如一个topic每秒产生1000MB消息,消费者每秒处理50MB,那就需要20个分区)。一个分区只能被消费组里面的一个消费者消费。
个人觉得可以理解为一个队列,通过offset偏移量读取消费。
消费者组:一群一样的消费者属于同一组,一个消费者可以消费多个分区的消息,一个分区只能被一个消费者消费。
offset偏移量:记录一个分区消费指针,其实就是个long类型的数字。
master分区(首领分区):kafaka集群A、B、C,比如一个topic1拥有三个分区p0,p1,p2,当然三个broker分别都拥有三个分区;每个broker可能都包含一个分区的master分区,是不是主分区需要依据选举。应该是基于zookeeper的二分选举法(过半),使用二分选举发可以解决脑裂的问题(其实脑裂就是有多个master的情况)。
主分区接收客户端的消息并同步到从分区。客户端可以根据配置设置ack方式, 0:只要消息发送出去了就确认;1:只要有一个broker接收到了消息;all: 所有集群副本都接收到了消息确认。
生产者——>序列化器——>分区器(找到发送到哪一个分区)——>最后达到kafakaserver
Rebalance分区再均衡发生的场景:
- 消费组员发生变更
- 订阅主题(topic)发生变更
- 分区数发生变更
解决方案:在消费者订阅时,添加一个再均衡监听器,也就是当kafaka发生在做 Rebalance操作前后均会调用再均衡监听器。可以在Rebalance之前提交消费者消费消息的偏移量。
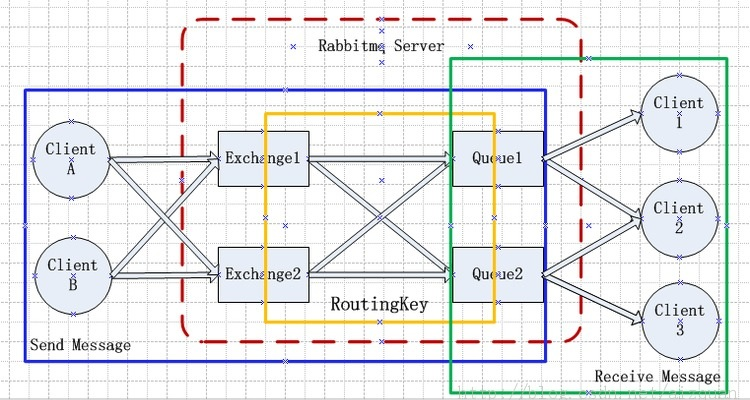
RabbitMq
VHost:通过vhost实现多租户系统,不同的virtual host是相互独立的。每个vhost都拥有自己的Exchange、Queue、以及Binding rule等。可以针对vhost设置权限和最大连接数等。
多租户的使用场景,比如主机资源紧缺情况下开发和测试共用一个RabbitMQ,可以使用Virtual Hosts将开发和测试隔离开。
Connection(连接)和Channel(信道):为什么要引入Channel?主要就是解决TCP连接多路复用的问题;如果一个应用程序中有多个线程生产或是消费消息的话,每个线程都建立一个TCP Connection,对于服务器来说频繁的建立和销毁TCP连接是很消耗性能的,
如果遇到使用高峰,很容易出现瓶颈。
https://www.cnblogs.com/eleven24/p/10326718.html
Exchange:交换机,生产者把消息发给RabbitMq,其实就是发给了交换机,然后再又交换机发送给队列。
交换机类型:
fanout:其实就是广播,发送到与交换机绑定的所有队列。会忽略routing key
direct:根据routing key 完全匹配
topic:支持模糊匹配,* 只能匹配 . 后的一个单词;# 匹配多个单词
headers:根据内容请求头匹配,用的较少
rpc:通过RabbitMq可以实现rpc通信;同步处理的场景下使用。发送消息时会告诉消费者处理完成后响应到指定队列,并携带correlation_id(根据业务指定,主要是找到两者的关系,便于处理)

Queue:队列
Binding:绑定,通过Binding把Exchange与Queue绑在一起
Binding Key:通过Binding Key指定Exchange和Queue的绑定规则;
Routing Key:在绑定(Binding)Exchange与Queue的同时,一般会指定一个binding key;消费者将消息发送给Exchange时,一般会指定一个routing key;当binding key与routing key相匹配时,消息将会被路由到对应的Queue中。
消息预取(消息发放机制):
rabbitmq会把消息最快以轮询的方式发送到客户端(如果消息没有确认的话,它会添加一个Unacked的状态标识);
这种机制不能根据各个服务器(或是服务)的消费能力合理分发消息,如果要解决这个问题就需要使用消息预取机制:其实就是先告诉rabbitmq我一次能消费多少消息,等我消费完了再告诉rabbitmq给我发消息
//设置消息预取的数量
simpleRabbitListenerContainerFactory.setPrefetchCount(1);
这个预取的数值的大小与性能成正比,要结合具体业务场景进行指定。
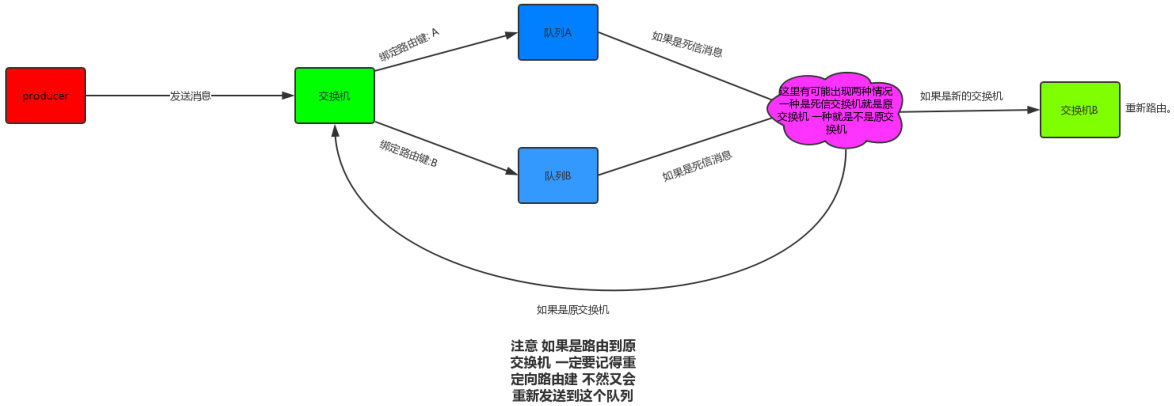
死信交换机和死信队列:(有些人可能叫作垃圾回收器,垃圾交换机等)
https://juejin.im/post/5c540fdde51d457ff9779e02
https://www.cnblogs.com/lori/p/9984760.html
经典的应用场景就是:超时订单取消,下单的时候为每个订单设置超时时间(rabbitMq可以从两种维度设置消息过期时间,分别是队列和消息本身),超时直接进入死信交换机(转发给死信队列)取消订单的服务订阅该死信队列。
基础概念详解: https://juejin.im/entry/5a7a71455188254e5c6c51c1
集群
普通模式(默认的集群模式):
设置每个服务器节点的hostname;需要将各个节点的.erlang.cookie文件内容保持一致;执行加入集群的命令(可以指定是磁盘节点还是内存节点,集群下至少有一个节点是磁盘节点):rabbitmqctl join_cluster rabbit@rabbitmq1 --ram
镜像模式(把需要的队列做成镜像队列,存在于多个节点,属于RabbiMQ的HA方案,在对业务可靠性要求较高的场合中比较适用)。
要实现镜像模式,需要先搭建一个普通集群模式,在这个模式的基础上再配置镜像模式以实现高可用。
1、重复消费
通过offset偏移指针(保存到zookepeer,新版本的kafaka都保存在broker上了)标记消费到了哪里,可以消费多条一次提交,如果消费一批中某个异常挂掉了导致没有提交,导致没有提交偏移位,下次就可能导致重复消费问题。
解决重复消费保证幂等问题:
(1)比如你拿个数据要写库,你先根据主键查一下,如果这数据都有了,你就别插入了,update一下
(2)比如你是写redis,那没问题了,反正每次都是set,天然幂等性
https://blog.csdn.net/u013425438/article/details/102553536
2、消息丢失
Kafaka通常采用如下方式:
(1)对于生产端丢消息:ack=all 保证消息所有节点都会同步到才算生产成功(保证可靠消息),不然master宕机还没有同步到其它broker。
一般比较重要的消息才会这么做,不然影响吞吐率。
(2)对于消费端丢消息:接收到消息直接入库,然后再去执行消费逻辑,并且采用定时补偿机制,防止消息失败。
RabbitMq:
通过发送方确认机制+失败回调;RabbitMq发送消息流程:发布消息---->交换机---->(队列是绑定到交换机上)队列,主要是这两个环节可能出错导致消息丢失。
通过发送方确认机制确保消息能够到达交换机上(其实也就是一个Broker上),然后通过失败回调确保交换机发送到队列上。
消费方确认模式:实例话一个监听器容器SimpleRabbitListenerContainerFactory,并且在容器里面指定消息确认为手动确认。消费方不管消费成功与否都需要确认,失败了可以指定回退消息或是废弃。
@RabbitListener(queues = "testQueue",containerFactory ="simpleRabbitListenerContainerFactory")
public void getMessage(Message message, Channel channel){}
3、消息堆积
kafaka:(一个分区只能被组里面的一个消费者消费),如果ramitmq可以添加消费者
(1)多建几个分区,用原来的消费端把消息转发到扩容的分区,然后再用对应的消费端消费
(2)消费端收到先暂时不做任何操作直接返回,让kafaka清掉消息
4、消息顺序
Kafka官方保证了在一个partition内部的数据有序性(追加写、offset读);
为了提高Topic的并发吞吐能力,可以提高Topic的partition数,并通过设置partition的replica来保证数据高可靠;但是在多个Partition时,不能保证Topic级别的数据有序性。因此,如果就使用kafka,但是对数据有序性有严格要求,
那我建议:创建Topic只指定1个partition,这样的坏处就是磨灭了kafka最优秀的特性。所以可以思考下是不是技术选型有问题, kafka本身适合与流式大数据量,要求高吞吐,对数据有序性要求不严格的场景。