《Windows Azure Platform 系列文章目录》
之前在别的项目中遇到了类似的问题,SQL Server虚拟机中的订单数据,每天产生的数据约千万级别,数据库已经达到了5TB级别。之前需要人工对于SQL Server Table进行归档,费时费力。
我们可以利用Azure Data Factory,把SQL Server虚拟机的表,导入到Azure Storage中。
主要概念:
(1)ADF是云端的ETL工具
(2)Apache Parquet,列存储,高压缩比,数据保存在Azure Storage中
(3)Parquet Viewer,Windows下查看Parquet数据的工具:https://github.com/mukunku/ParquetViewer
主要步骤:
1.准备Azure虚拟机,安装SQL Server 2016,把数据插入到SQL Server表中,我们这里的sample data有411万行
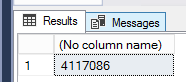
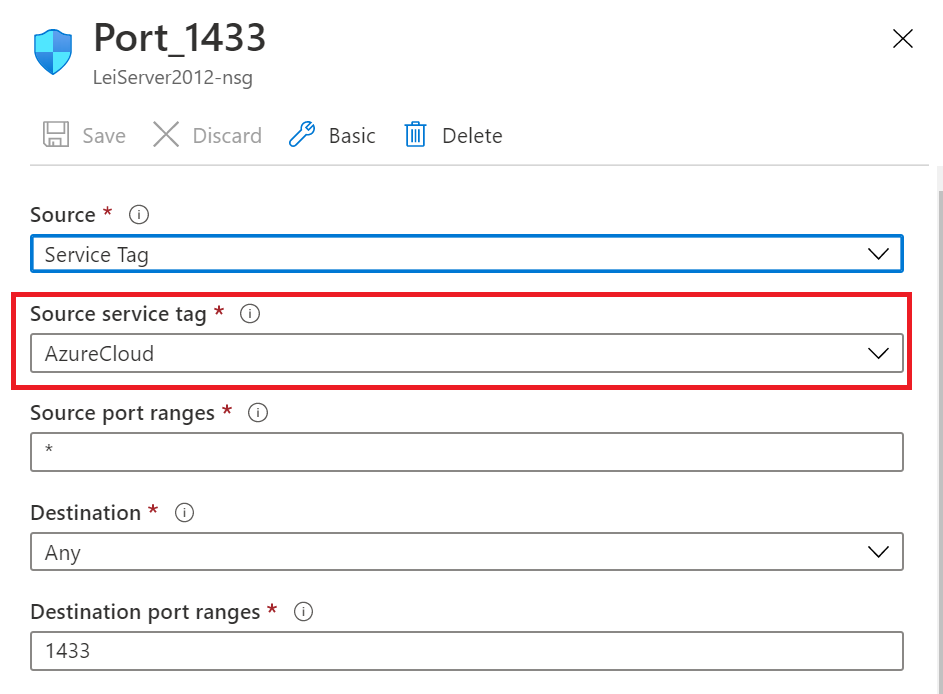
2.设置虚拟机的1433端口号,设置Source Service Tag为AzureCloud。允许Azure Cloud服务访问。
3.创建Azure Data Factory。步骤略。
3.设置ADF的源数据,如下图:
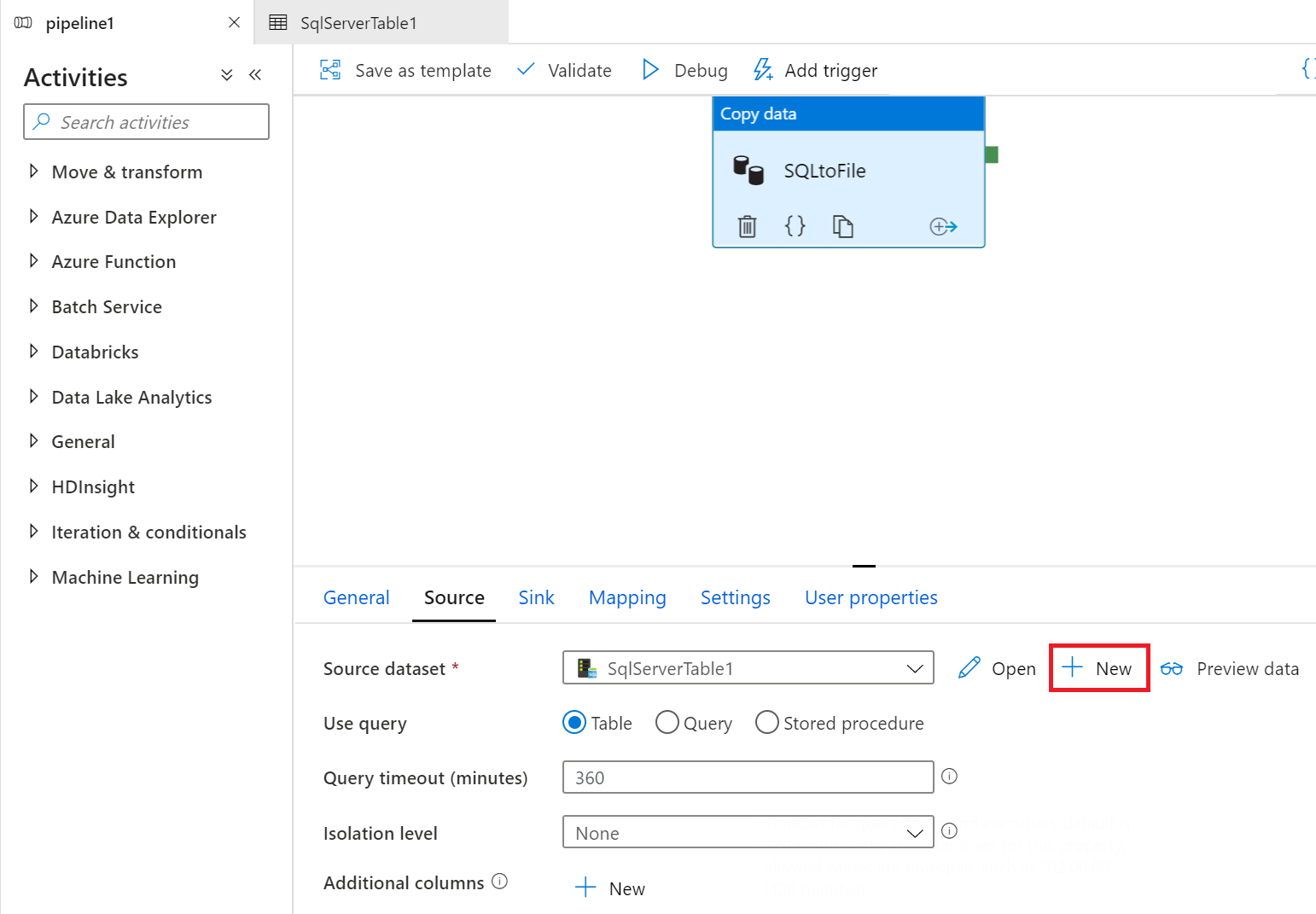
4.选择类型为SQL Server

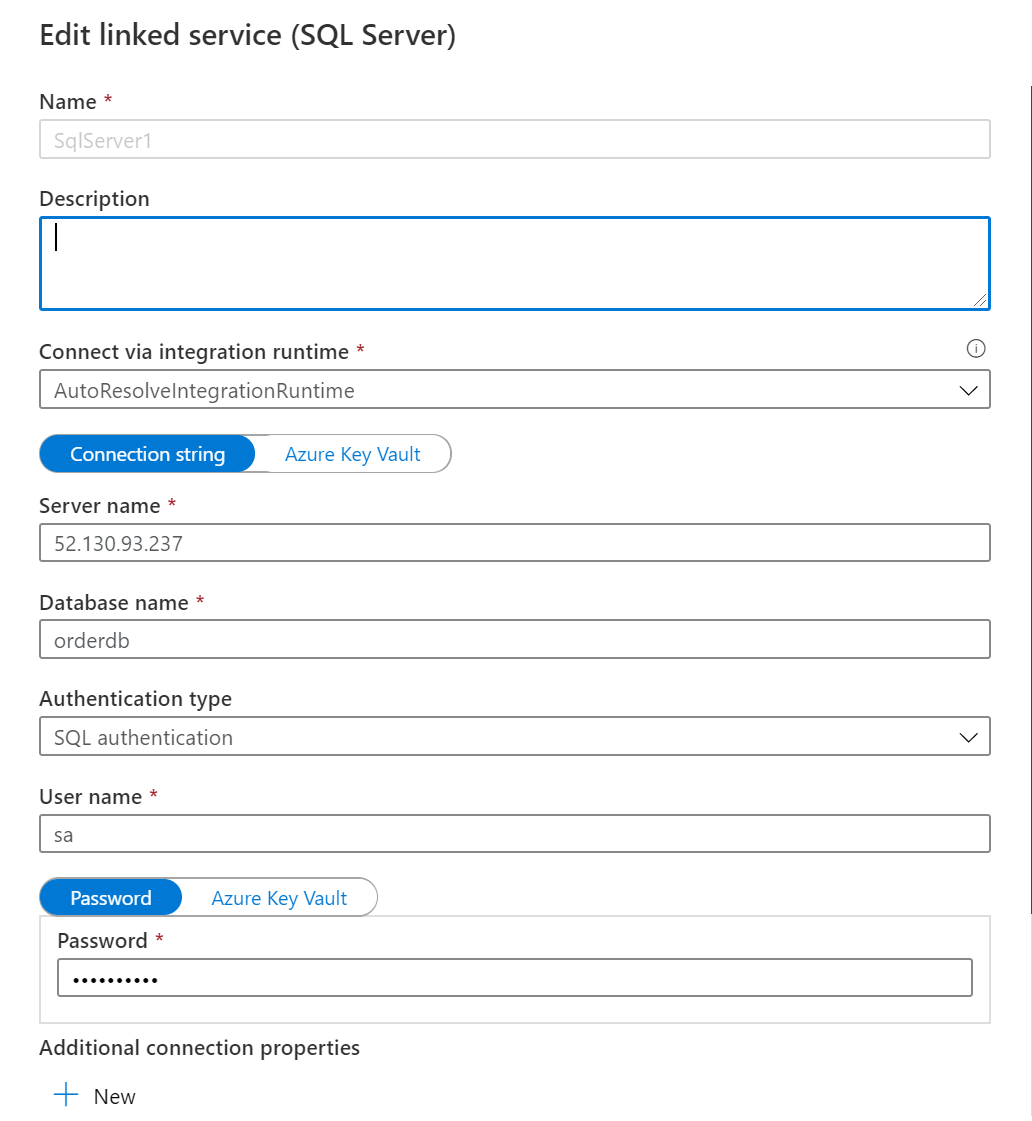
5.设置链接到SQL VM的链接字符串信息。如下图:
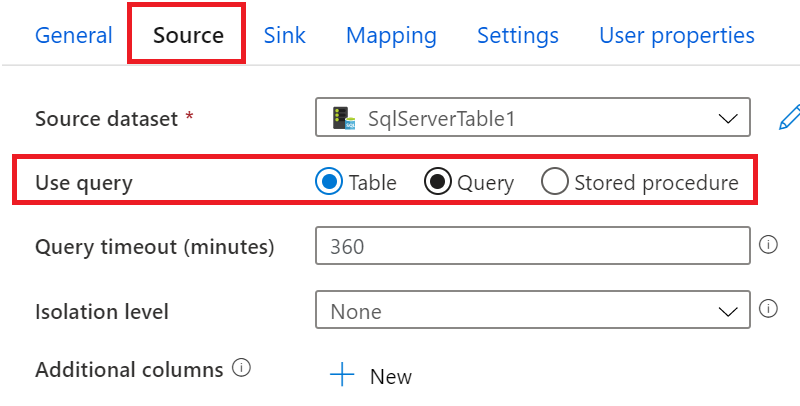
6.选择SQL Server Table表,或者执行T-SQL语句
7.然后我们设置目标数据

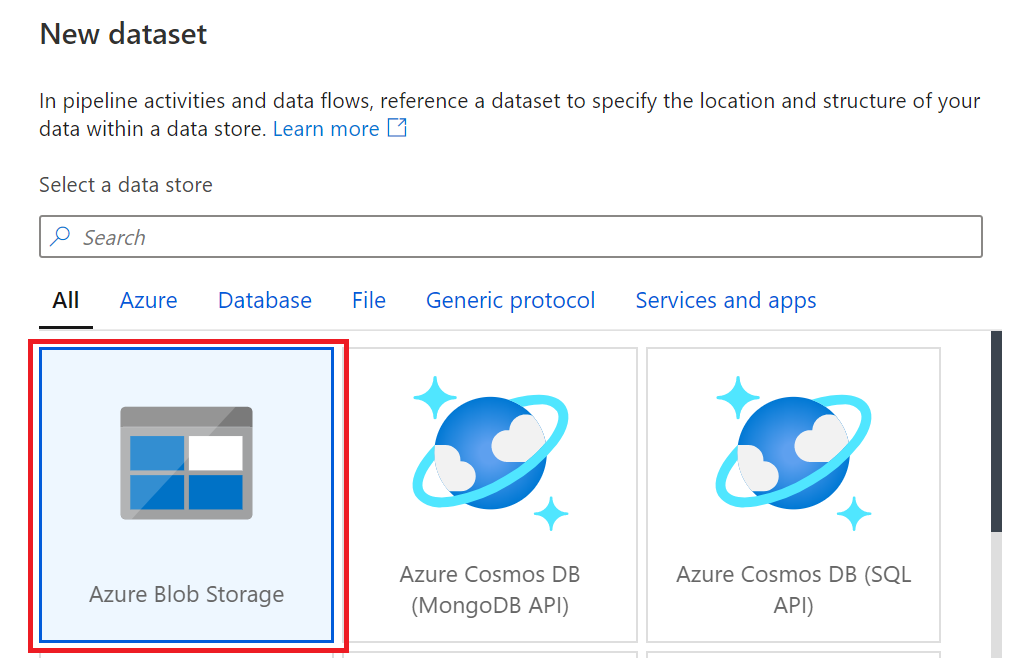
8.创建1个Azure Storage。再创建blob container,步骤略。
9.设置目标数据类型,为Azure Blob Storage
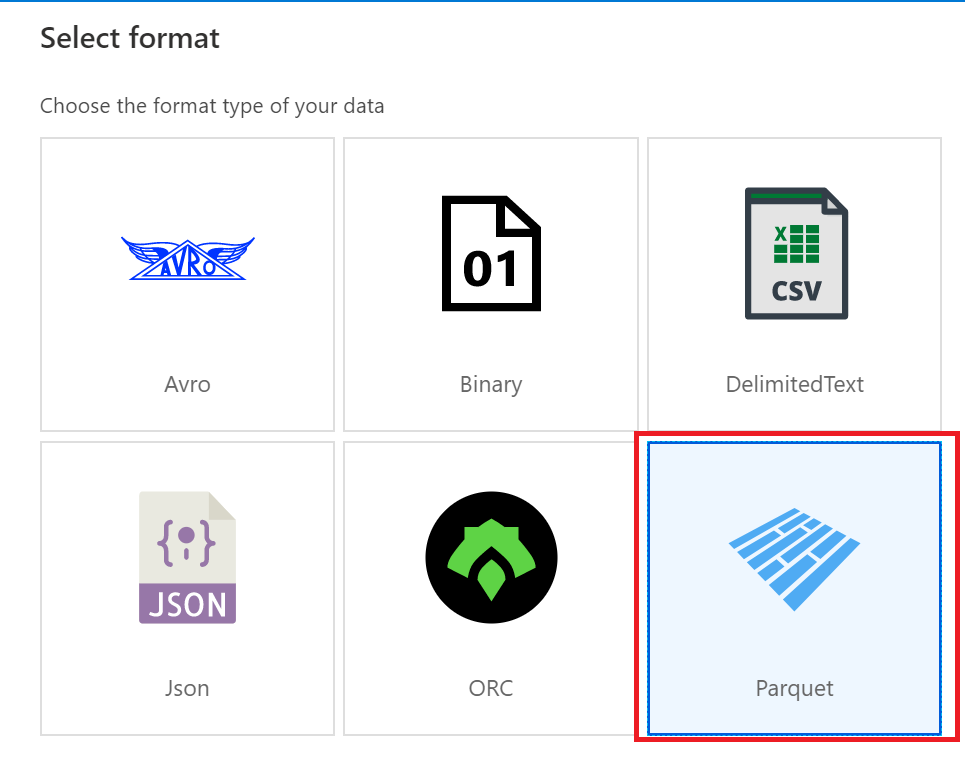
10.选择数据格式,为Parquet。如下图:
11.选择到Azure Storage Account的Container Name,并设置新创建的Parquet文件名为ADF执行成功的时间。
@formatDateTime(addhours(utcnow(),8),'yyyy-MM-ddTHH:mm:ss')
请注意:ADF执行的时间为UTC时区,我们需要把UTC时区转化为UTC+8北京时区

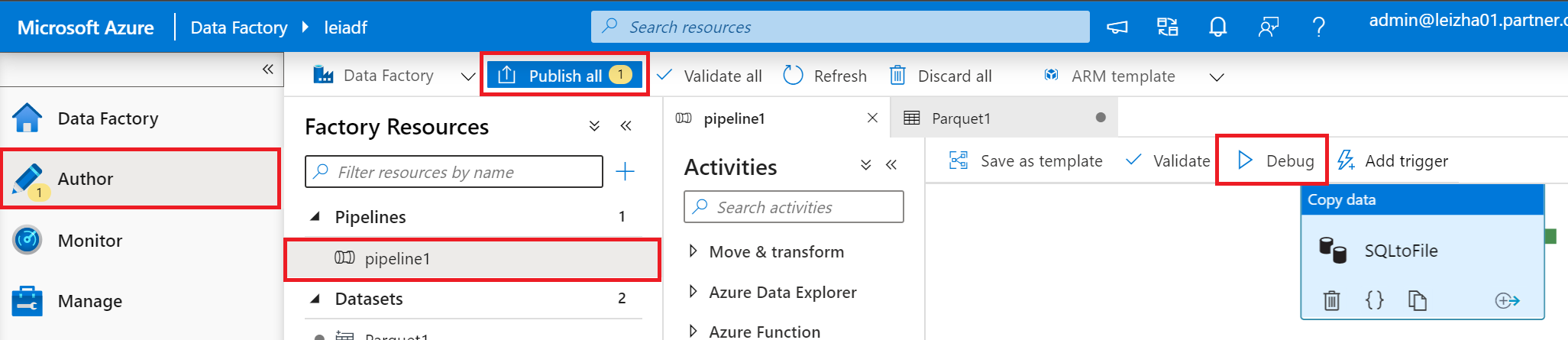
12.配置完毕后,我们可以通过debug进行调试
13.执行完毕后,我们可以在Azure Storage中,查看到执行成功后的Parquet文件,文件夹以yyyy-MM-ddTHH:mm:ss格式进行命名
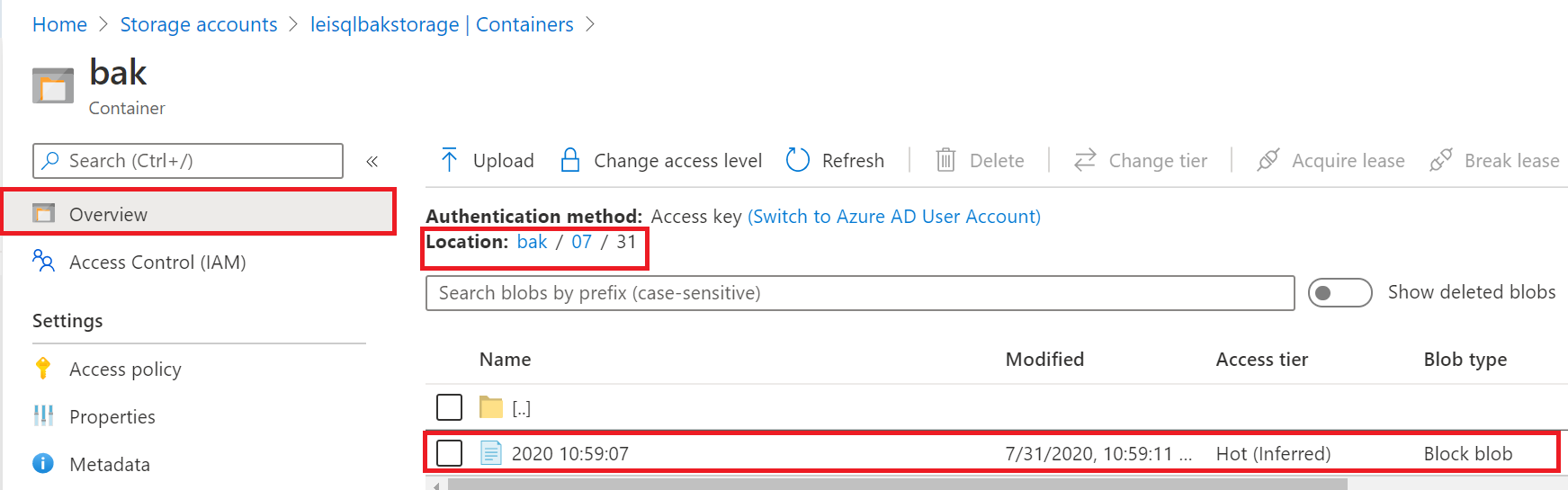
14.如果调试成功,我们可以设置触发器,设置每天执行。
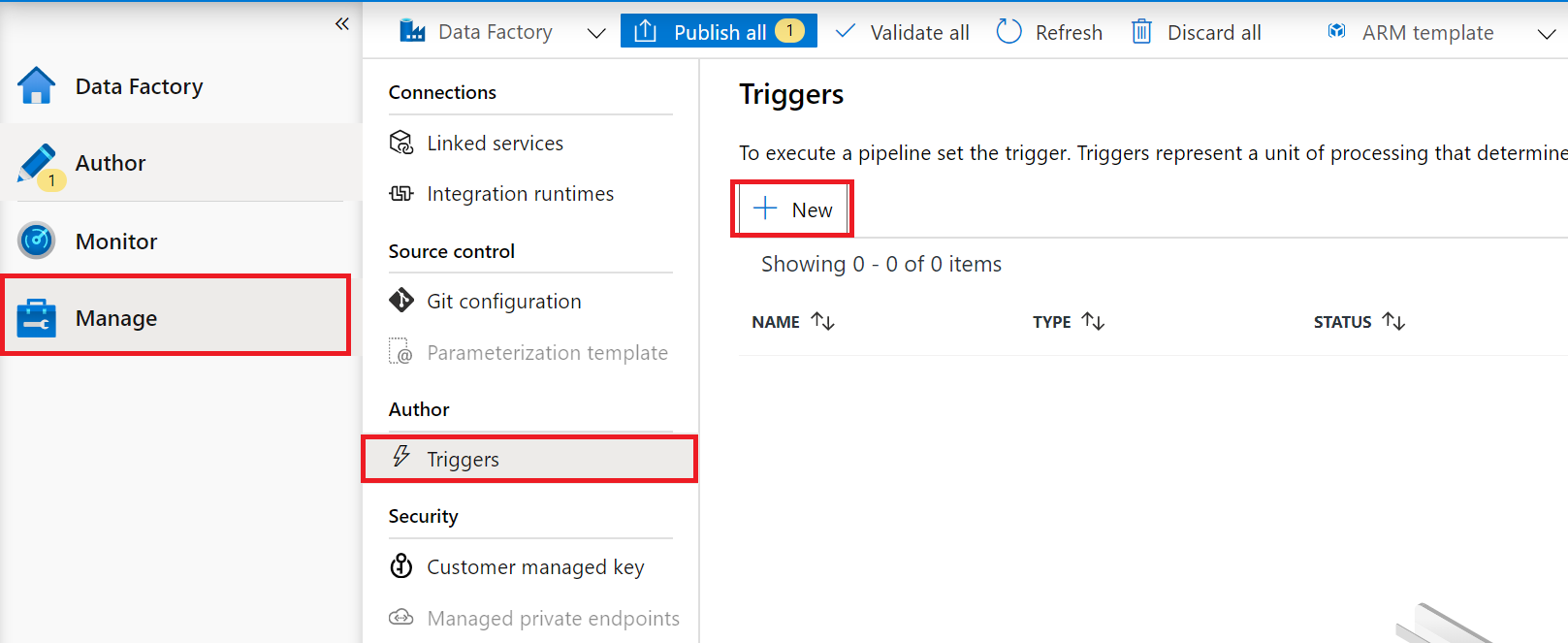
15.设置每天执行一次

16.最后,我们可以点击上图的Publish All,把这个ADF发布

最后执行结果:
1.411万行数据,总计花费56分钟,数据可以复制到Azure Storage
2.Parquet格式的文件,总大小为4.25 GB
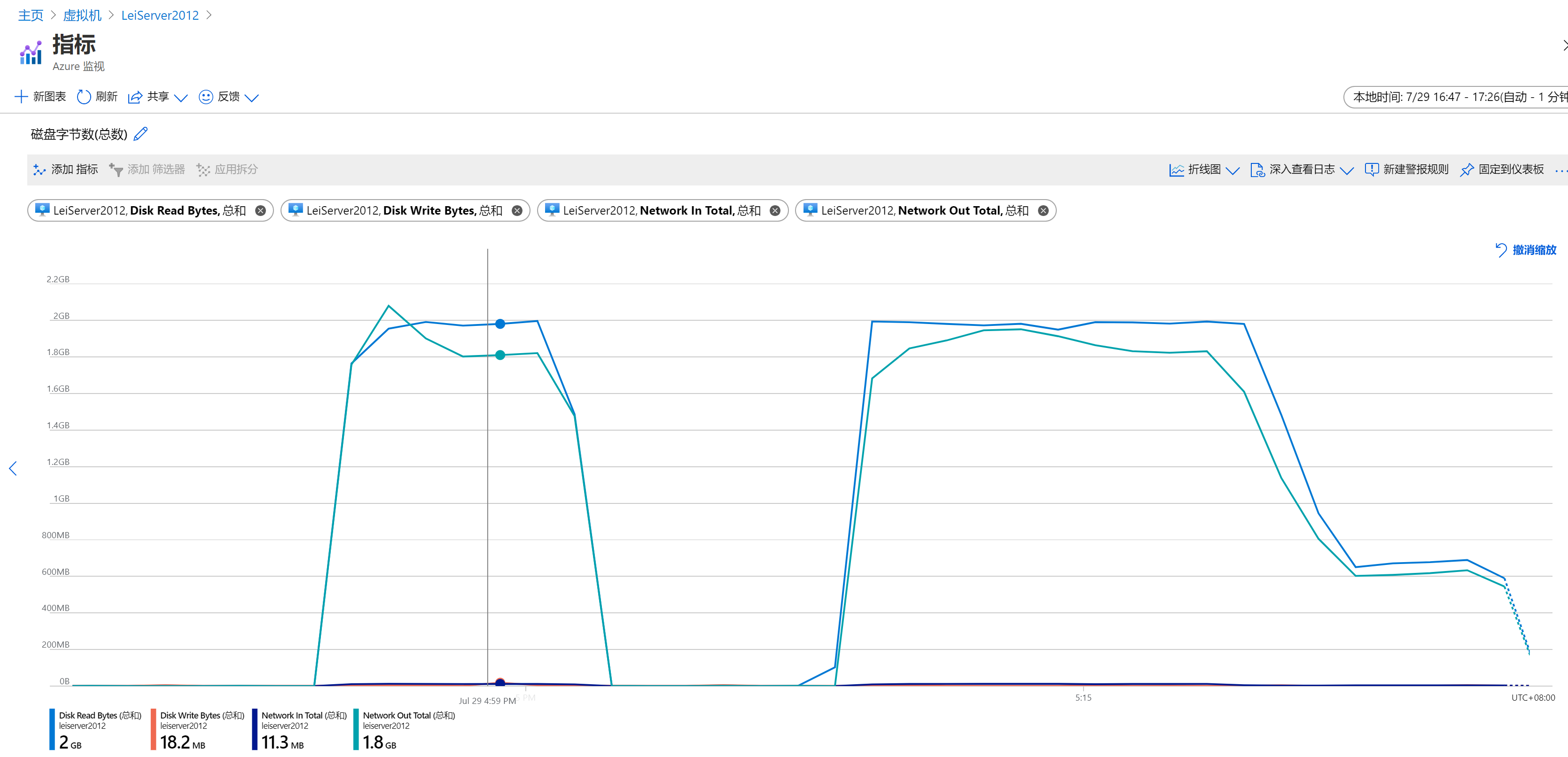
3.SQL Server虚拟机磁盘在ADF执行过程中,Disk Read 1分钟内峰值2GB。Network Out峰值为2GB
4.执行完毕后,可以通过ParquetViewer,查看存储在Azure Storage的文件。