《Windows Azure Platform 系列文章目录》
Azure SQL Data Warehouse已经改名为Azure SQL Synapse,这里继续挖个坑。
本章我们介绍如何通过Polybase,把Parquet数据导入到SQL Synapse。
什么是Polybase?
借助 PolyBase,SQL Synapse 实例可处理从 Hadoop 中读取数据的 Transact-SQL 查询。 同一查询还可以访问 SQL Synapse 中的关系表。 借助 PolyBase,同一查询还可以联接 Hadoop 和 SQL Server 中的数据。
通过Polybase,SQL Synapse支持数据源保存在Azure Storage中的数据。
1.我们首先准备一个Parquet数据。可以在这里下载:
我是通过.NET Core来实现的。具体可以参考:Apache Parquet for .Net Platform,https://github.com/elastacloud/parquet-dotnet
具体的sample:
static void WriteParquetFile() { var idColumn = new DataColumn( new DataField<Int64>("id"), new Int64[] { 111111111111, 222222222222 }); var nameColumn = new DataColumn( new DataField<string>("name"), new string[] { "Zhang SAn", "Wang Er" }); var ageColumn = new DataColumn( new DataField<int>("age"), new int[] { 30, 36 }); var schema = new Schema(idColumn.Field, nameColumn.Field, ageColumn.Field); using (Stream fileStream = System.IO.File.OpenWrite(@"D:sample.parquet")) { using (var parquetWriter = new ParquetWriter(schema, fileStream)) { // create a new row group in the file using (ParquetRowGroupWriter groupWriter = parquetWriter.CreateRowGroup()) { groupWriter.WriteColumn(idColumn); groupWriter.WriteColumn(nameColumn); groupWriter.WriteColumn(ageColumn); } } } }
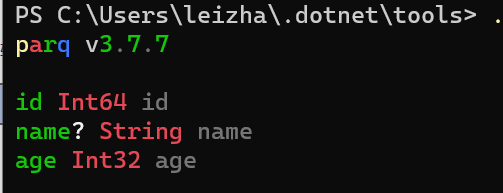
2.使用工具PARQ查看其schema中字段类型。如下图:
3.在Azure China创建1个存储账户,创建1个container,把上面的sample.parquet文件,上传到Azure Storage。步骤略
4.在Azure China创建SQL Synapse
5.通过SQL Server Management Studio,链接到Azure SQL Synapse
6.在SSMS中,执行下面的脚本:
--创建External PARQUET文件格式 CREATE EXTERNAL FILE FORMAT [ParquetFileSnappy] WITH ( FORMAT_TYPE = PARQUET, DATA_COMPRESSION = N'org.apache.hadoop.io.compress.SnappyCodec' ) GO --下面的password的秘钥内容,可以根据需要修改PASSWORD值 CREATE MASTER KEY ENCRYPTION BY PASSWORD = '23987hxJ#KL95234nl0zBe'; --identity是存储账号名称 --Secret是存储账户的秘钥 CREATE DATABASE SCOPED CREDENTIAL AzureStorageCredential01 WITH IDENTITY = '[你的存储账户名称]' ,SECRET = '[你的存储账户秘钥]' ; --下面的wasbs后面是containername@storage account name CREATE EXTERNAL DATA SOURCE [AzureBlobStorageHadoop] WITH ( TYPE = HADOOP, LOCATION = N'wasbs://[Blob container名称]@[你的存储账户名称].blob.core.chinacloudapi.cn', CREDENTIAL = AzureStorageCredential01 -- created earlier ) GO --创建新的TABLE,导入的文件名是Azure Blob的文件名,记住Location后面一定要有斜杠(/) --字段类型根据Parquet的字段类型决定 CREATE EXTERNAL TABLE dbo.employee( id BIGINT NULL, name nvarchar(50) NULL, age int NULL ) WITH ( LOCATION='/sample.parquet', DATA_SOURCE=AzureBlobStorageHadoop, FILE_FORMAT=ParquetFileSnappy );
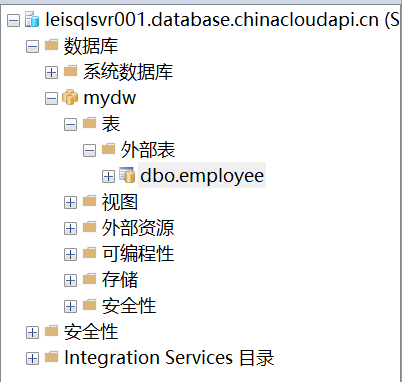
7.执行成功后,我们可以查看到创建成功的外部表。
8.最后,我们可以通过T-SQL语句,查看到该外部表中的内容。
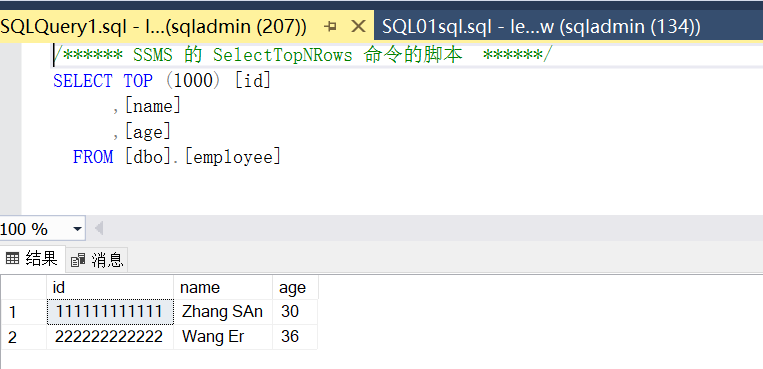
9.可以看到,通过Polybase方式,可以非常方便的查看到Azure Storage中的Parquet数据。