文章来源:https://blog.thinkeridea.com/201901/go/shen_ru_pou_xi_slice_he_array.html
array 和 slice 看似相似,却有着极大的不同,但他们之间还有着千次万缕的联系 slice 是引用类型、是 array 的引用,相当于动态数组,
这些都是 slice 的特性,但是 slice 底层如何表现,内存中是如何分配的,特别是在程序中大量使用 slice 的情况下,怎样可以高效使用 slice?
今天借助 Go 的 unsafe 包来探索 array 和 slice 的各种奥妙。
数组
slice 是在 array 的基础上实现的,需要先详细了解一下数组。
** 维基上如此介绍数组:**
在计算机科学中,数组数据结构(英语:array data structure),简称数组(英语:Array),是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续的内存来存储,利用元素的索引(index)可以计算出该元素对应的存储地址。
** 数组设计之初是在形式上依赖内存分配而成的,所以必须在使用前预先请求空间。这使得数组有以下特性:**
- 请求空间以后大小固定,不能再改变(数据溢出问题);
- 在内存中有空间连续性的表现,中间不会存在其他程序需要调用的数据,为此数组的专用内存空间;
- 在旧式编程语言中(如有中阶语言之称的C),程序不会对数组的操作做下界判断,也就有潜在的越界操作的风险(比如会把数据写在运行中程序需要调用的核心部分的内存上)。
根据维基的介绍,了解到数组是存储在一段连续的内存中,每个元素的类型相同,即是每个元素的宽度相同,可以根据元素的宽度计算元素存储的位置。
通过这段介绍总结一下数组有一下特性:
- 分配在连续的内存地址上
- 元素类型一致,元素存储宽度一致
- 空间大小固定,不能修改
- 可以通过索引计算出元素对应存储的位置(只需要知道数组内存的起始位置和数据元素宽度即可)
- 会出现数据溢出的问题(下标越界)
Go 中的数组如何实现的呢,恰恰就是这么实现的,实际上几乎所有计算机语言,数组的实现都是相似的,也拥有上面总结的特性。
Go 语言的数组不同于 C 语言或者其他语言的数组,C 语言的数组变量是指向数组第一个元素的指针;
而 Go 语言的数组是一个值,Go 语言中的数组是值类型,一个数组变量就表示着整个数组,意味着 Go 语言的数组在传递的时候,传递的是原数组的拷贝。
在程序中数组的初始化有两种方法 arr := [10]int{} 或 var arr [10]int,但是不能使用 make 来创建,数组这节结束时再探讨一下这个问题。
使用 unsafe来看一下在内存中都是如何存储的吧:
package main
import (
"fmt"
"unsafe"
)
func main() {
var arr = [3]int{1, 2, 3}
fmt.Println(unsafe.Sizeof(arr))
size := unsafe.Sizeof(arr[0])
// 获取数组指定索引元素的值
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&arr[0])) + 1*size)))
// 设置数组指定索引元素的值
*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&arr[0])) + 1*size)) = 10
fmt.Println(arr[1])
}
这段代码的输出如下 (Go Playground):
12
2
10
首先说 12 是 fmt.Println(unsafe.Sizeof(arr)) 输出的,unsafe.Sizeof 用来计算当前变量的值在内存中的大小,12 这个代表一个 int 有4个字节,3 * 4 就是 12。
这是在32位平台上运行得出的结果, 如果在64位平台上运行数组的大小是 24。从这里可以看出 [3]int 在内存中由3个连续的 int 类型组成,且有 12 个字节那么长,这就说明了数组在内存中没有存储多余的数据,只存储元素本身。
size := unsafe.Sizeof(arr[0]) 用来计算单个元素的宽度,int在32位平台上就是4个字节,uintptr(unsafe.Pointer(&arr[0])) 用来计算数组起始位置的指针,1*size 用来获取索引为1的元素相对数组起始位置的偏移,unsafe.Pointer(uintptr(unsafe.Pointer(&arr[0])) + 1*size)) 获取索引为1的元素指针,*(*int) 用来转换指针位置的数据类型, 因为 int 是4个字节,所以只会读取4个字节的数据,由元素类型限制数据宽度,来确定元素的结束位置,因此得到的结果是 2。
上一个步骤获取元素的值,其中先获取了元素的指针,赋值的时候只需要对这个指针位置设置值就可以了, *(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&arr[0])) + 1*size)) = 10 就是用来给指定下标元素赋值。
package main
import (
"fmt"
"unsafe"
)
func main() {
n:= 10
var arr = [n]int{}
fmt.Println(arr)
}
如上代码,动态的给数组设定长度,会导致编译错误 non-constant array bound n, 由此推导数组的所有操作都是编译时完成的,会转成对应的指令,通过这个特性知道数组的长度是数组类型不可或缺的一部分,并且必须在编写程序时确定。
可以通过 GOOS=linux GOARCH=amd64 go tool compile -S array.go 来获取对应的汇编代码,在 array.go 中做一些数组相关的操作,查看转换对应的指令。
之前的疑问,为什么数组不能用 make 创建? 上面分析了解到数组操作是在编译时转换成对应指令的,而 make 是在运行时处理(特殊状态下会做编译器优化,make可以被优化,下面 slice 分析时来讲)。
slice
因为数组是固定长度且是值传递,很不灵活,所以在 Go 程序中很少看到数组的影子。然而 slice 无处不在,slice 以数组为基础,提供强大的功能和遍历性。
slice 的类型规范是[]T,slice T元素的类型。与数组类型不同,slice 类型没有指定的长度。
** slice 申明的几种方法:**
s := []int{1, 2, 3}简短的赋值语句
var s []intvar申明
make([]int, 3, 8)或make([]int, 3)make内置方法创建
s := ss[:5]从切片或者数组创建
** slice 有两个内置函数来获取其属性:**
len获取slice的长度
cap获取slice的容量
slice 的属性,这东西是什么,还需借助 unsafe 来探究一下。
package main
import (
"fmt"
"unsafe"
)
func main() {
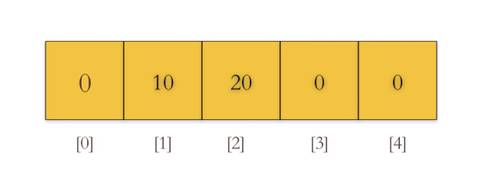
s := make([]int, 10, 20)
s[2] = 100
s[9] = 200
size := unsafe.Sizeof(0)
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size*2)))
fmt.Println(*(*[20]int)(unsafe.Pointer(*(*uintptr)(unsafe.Pointer(&s)))))
}
这段代码的输出如下 (Go Playground):
c00007ce90
10
20
[0 0 100 0 0 0 0 0 0 200 0 0 0 0 0 0 0 0 0 0]
这段输出除了第一个,剩余三个好像都能看出点什么, 10 不是创建 slice 的长度吗,20 不就是指定的容量吗, 最后这个看起来有点像 slice 里面的数据,但是数量貌似有点多,从第三个元素和第十个元素来看,正好是给 slice 索引 2 和 10 指定的值,但是切片不是长度是 10 个吗,难道这个是容量,容量刚好是 20个。
第二和第三个输出很好弄明白,就是 slice 的长度和容量, 最后一个其实是 slice 引用底层数组的数据,因为创建容量为 20,所以底层数组的长度就是 20,从这里了解到切片是引用底层数组上的一段数据,底层数组的长度就是 slice 的容量,由于数组长度不可变的特性,当 slice 的长度达到容量大小之后就需要考虑扩容,不是说数组长度不能变吗,那 slice 怎么实现扩容呢, 其实就是在内存上分配一个更大的数组,把当前数组上的内容拷贝到新的数组上, slice 来引用新的数组,这样就实现扩容了。
说了这么多,还是没有看出来 slice 是如何引用数组的,额…… 之前的程序还有一个输出没有搞懂是什么,难道这个就是底层数组的引用。
package main
import (
"fmt"
"unsafe"
)
func main() {
arr := [10]int{1, 2, 3}
arr[7] = 100
arr[9] = 200
fmt.Println(arr)
s1 := arr[:]
s2 := arr[2:8]
size := unsafe.Sizeof(0)
fmt.Println("----------s1---------")
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s1)))
fmt.Printf("%x\n", uintptr(unsafe.Pointer(&arr[0])))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size*2)))
fmt.Println(s1)
fmt.Println(*(*[10]int)(unsafe.Pointer(*(*uintptr)(unsafe.Pointer(&s1)))))
fmt.Println("----------s2---------")
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s2)))
fmt.Printf("%x\n", uintptr(unsafe.Pointer(&arr[0]))+size*2)
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s2)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s2)) + size*2)))
fmt.Println(s2)
fmt.Println(*(*[8]int)(unsafe.Pointer(*(*uintptr)(unsafe.Pointer(&s2)))))
}
以上代码输出如下(Go Playground):
[1 2 3 0 0 0 0 100 0 200]
----------s1---------
c00001c0a0
c00001c0a0
10
10
[1 2 3 0 0 0 0 100 0 200]
[1 2 3 0 0 0 0 100 0 200]
----------s2---------
c00001c0b0
c00001c0b0
6
8
[3 0 0 0 0 100]
[3 0 0 0 0 100 0 200]
这段输出看起来有点小复杂,第一行输出就不用说了吧,这个是打印整个数组的数据。先分析一下 s1 变量的下面的输出吧,s1 := arr[:] 引用了整个数组,所以在第5、6行输出都是10,因为数组长度为10,所有 s1 的长度和容量都为10,那第3、4行输出是什么呢,他们怎么都一样呢,之前分析数组的时候 通过 uintptr(unsafe.Pointer(&arr[0])) 来获取数组起始位置的指针的,那么第4行打印的就是数组的指针,这么就了解了第三行输出的是上面了吧,就是数组起始位置的指针,所以 *(*uintptr)(unsafe.Pointer(&s1)) 获取的就是引用数组的指针,但是这个并不是数组起始位置的指针,而是 slice 引用数组元素的指针,为什么这么说呢?
接着看 s2 变量下面的输出吧,s2 := arr[2:8] 引用数组第3~8的元素,那么 s2 的长度就是 6。 根据经验可以知道 s2 变量输出下面第3行就是 slice 的长度,但是为啥第4行是 8 呢,slice 应用数组的指定索引起始位置到数组结尾就是 slice 的容量, 所以 所以从第3个位置到末尾,就是8个容量。在看第1行和第2行的输出,之前分析数组的时候通过 uintptr(unsafe.Pointer(&arr[0]))+size*2 来获取数组指定索引位置的指针,那么这段第2行就是数组索引为2的元素指针,*(*uintptr)(unsafe.Pointer(&s2)) 是获取切片的指针,第1行和第2行输出一致,所以 slice 实际是引用数组元素位置的指针,并不是数组起始位置的指针。
** 总结:**
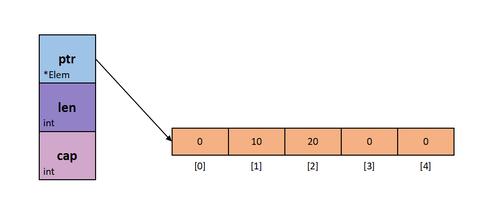
slice是的起始位置是引用数组元素位置的指针。slice的长度是引用数组元素起始位置到结束位置的长度。slice的容量是引用数组元素起始位置到数组末尾的长度。
经过上面一轮分析了解到 slice 有三个属性,引用数组元素位置指针、长度和容量。实际上 slice 的结构像下图一样:
slice 增长
slice 是如何增长的,用 unsafe 分析一下看看:
package main
import (
"fmt"
"unsafe"
)
func main() {
s := make([]int, 9, 10)
// 引用底层的数组地址
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
s = append(s, 1)
// 引用底层的数组地址
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
s = append(s, 1)
// 引用底层的数组地址
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
}
以上代码的输出(Go Playground):
c000082e90
9 10
c000082e90
10 10
c00009a000
11 20
从结果上看前两次地址是一样的,初始化一个长度为9,容量为10的 slice,当第一次 append 的时候容量是足够的,所以底层引用数组地址未发生变化,此时 slice 的长度和容量都为10,之后再次 append 的时候发现底层数组的地址不一样了,因为 slice 的长度超过了容量,但是新的 slice 容量并不是11而是20,这要说 slice 的机制了,因为数组长度不可变,想扩容 slice就必须分配一个更大的数组,并把之前的数据拷贝到新数组,如果一次只增加1个长度,那就会那发生大量的内存分配和数据拷贝,这个成本是很大的,所以 slice 是有一个增长策略的。
Go 标准库 runtime/slice.go 当中有详细的 slice 增长策略的逻辑:
func growslice(et *_type, old slice, cap int) slice {
.....
// 计算新的容量,核心算法用来决定slice容量增长
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
if newcap <= 0 {
newcap = cap
}
}
}
// 根据et.size调整新的容量
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem = roundupsize(uintptr(newcap) * et.size)
overflow = uintptr(newcap) > maxSliceCap(et.size)
newcap = int(capmem / et.size)
}
......
var p unsafe.Pointer
if et.kind&kindNoPointers != 0 {
p = mallocgc(capmem, nil, false) // 分配新的内存
memmove(p, old.array, lenmem) // 拷贝数据
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true) // 分配新的内存
if !writeBarrier.enabled {
memmove(p, old.array, lenmem)
} else {
for i := uintptr(0); i < lenmem; i += et.size {
typedmemmove(et, add(p, i), add(old.array, i)) // 拷贝数据
}
}
}
return slice{p, old.len, newcap} // 新slice引用新的数组,长度为旧数组的长度,容量为新数组的容量
}
基本呢就三个步骤,计算新的容量、分配新的数组、拷贝数据到新数组,社区很多人分享 slice 的增长方法,实际都不是很精确,因为大家只分析了计算 newcap 的那一段,也就是上面注释的第一部分,下面的 switch 根据 et.size 来调整 newcap 一段被直接忽略,社区的结论是:"如果 selic 的容量小于1024个元素,那么扩容的时候 slice 的 cap 就翻番,乘以2;一旦元素个数超过1024个元素,增长因子就变成1.25,即每次增加原来容量的四分之一" 大多数情况也确实如此,但是根据 newcap 的计算规则,如果新的容量超过旧的容量2倍时会直接按新的容量分配,真的是这样吗?
package main
import (
"fmt"
)
func main() {
s := make([]int, 10, 10)
fmt.Println(len(s), cap(s))
s2 := make([]int, 40)
s = append(s, s2...)
fmt.Println(len(s), cap(s))
}
以上代码的输出(Go Playground):
10 10
50 52
这个结果有点出人意料, 如果是2倍增长应该是 10 * 2 * 2 * 2 结果应该是80, 如果说新的容量高于旧容量的两倍但结果也不是50,实际上 newcap 的结果就是50,那段逻辑很好理解,但是switch 根据 et.size 来调整 newcap 后就是52了,这段逻辑走到了 case et.size == sys.PtrSize 这段,详细的以后做源码分析再说。
** 总结 **
- 当
slice的长度超过其容量,会分配新的数组,并把旧数组上的值拷贝到新的数组 - 逐个元素添加到
slice并操过其容量, 如果selic的容量小于1024个元素,那么扩容的时候slice的cap就翻番,乘以2;一旦元素个数超过1024个元素,增长因子就变成1.25,即每次增加原来容量的四分之一。 - 批量添加元素,当新的容量高于旧容量的两倍,就会分配比新容量稍大一些,并不会按上面第二条的规则扩容。
- 当
slice发生扩容,引用新数组后,slice操作不会再影响旧的数组,而是新的数组(社区经常讨论的传递slice容量超出后,修改数据不会作用到旧的数据上),所以往往设计函数如果会对长度调整都会返回新的slice,例如append方法。
slice 是引用类型?
slice 不发生扩容,所有的修改都会作用在原数组上,那如果把 slice 传递给一个函数或者赋值给另一个变量会发生什么呢,slice 是引用类型,会有新的内存被分配吗。
package main
import (
"fmt"
"strings"
"unsafe"
)
func main() {
s := make([]int, 10, 20)
size := unsafe.Sizeof(0)
fmt.Printf("%p\n", &s)
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size*2)))
slice(s)
s1 := s
fmt.Printf("%p\n", &s1)
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s1)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size*2)))
fmt.Println(strings.Repeat("-", 50))
*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size)) = 20
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size*2)))
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s1)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s1)) + size*2)))
fmt.Println(s)
fmt.Println(s1)
fmt.Println(strings.Repeat("-", 50))
s2 := s
s2 = append(s2, 1)
fmt.Println(len(s), cap(s), s)
fmt.Println(len(s1), cap(s1), s1)
fmt.Println(len(s2), cap(s2), s2)
}
func slice(s []int) {
size := unsafe.Sizeof(0)
fmt.Printf("%p\n", &s)
fmt.Printf("%x\n", *(*uintptr)(unsafe.Pointer(&s)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size)))
fmt.Println(*(*int)(unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + size*2)))
}
这个例子(Go Playground)比较长就不逐一分析了,在这个例子里面调用函数传递 slice 其变量的地址发生了变化, 但是引用数组的地址,slice 的长度和容量都没有变化, 这说明是对 slice 的浅拷贝,拷贝 slice 的三个属性创建一个新的变量,虽然引用底层数组还是一个,但是变量并不是一个。
第二个创建 s1 变量,使用 s 为其赋值,发现 s1 和函数调用一样也是 s 的浅拷贝,之后修改 s1 的长度发现 s1 的长度发生变化,但是 s 的长度保持不变, 这也说明 s1 就是 s 的浅拷贝。
这样设计有什么优势呢,第三步创建 s2 变量, 并且 append 一个元素, 发现 s2 的长度发生变化了, s 并没有,虽然这个数据就在底层数组上,但是用常规的方法 s 是看不到第11个位置上的数据的, s1 因为长度覆盖到第11个元素,所有能够看到这个数据的变化。这里能看到采用浅拷贝的方式可以使得切片的属性各自独立,而不会相互影响,这样可以有一定的隔离性,缺点也很明显,如果两个变量都引用同一个数组,同时 append, 在不发生扩容的情况下,总是最后一个 append 的结果被保留,可能引起一些编程上疑惑。
** 总结 **
slice 是引用类型,但是和 C 传引用是有区别的, C 里面的传引用是在编译器对原变量数据引用, 并不会发生内存分配,而 Go 里面的引用类型传递和赋值会进行浅拷贝,在32位平台上有12个字节的内存分配, 在64位上有24字节的内存分配。
*** 传引用和引用类型是有区别的, slice 是引用类型。***
slice 的三种状态
slice 有三种状态:零切片、空切片、nil切片。
零切片
所有的类型都有零值,如果 slice 所引用数组元素都没有赋值,就是所有元素都是类型零值,那这就是零切片。
package main
import "fmt"
func main() {
var s = make([]int, 10)
fmt.Println(s)
var s1 = make([]*int, 10)
fmt.Println(s1)
var s2 = make([]string, 10)
fmt.Println(s2)
}
以上代码输出(Go Playground):
[0 0 0 0 0 0 0 0 0 0]
[]
[ ]
零切片很好理解,数组元素都为类型零值即为零切片,这种状态下的 slice 和正常的 slice 操作没有任何区别。
空切片
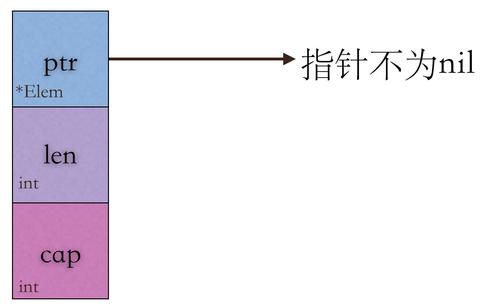
空切片可以理解就是切片的长度为0,就是说 slice 没有元素。 社区大多数解释空切片为引用底层数组为 zerobase 这个特殊的指针。但是从操作上看空切片所有的表现就是切片长度为0,如果容量也为零底层数组就会指向 zerobase ,这样就不会发生内存分配, 如果容量不会零就会指向底层数据,会有内存分配。
package main
import (
"fmt"
"reflect"
"strings"
"unsafe"
)
func main() {
var s []int
s1 := make([]int, 0)
s2 := make([]int, 0, 0)
s3 := make([]int, 0, 100)
arr := [10]int{}
s4 := arr[:0]
fmt.Println(strings.Repeat("--s--", 10))
fmt.Println(*(*reflect.SliceHeader)(unsafe.Pointer(&s)))
fmt.Println(s)
fmt.Println(s == nil)
fmt.Println(strings.Repeat("--s1--", 10))
fmt.Println(*(*reflect.SliceHeader)(unsafe.Pointer(&s1)))
fmt.Println(s1)
fmt.Println(s1 == nil)
fmt.Println(strings.Repeat("--s2--", 10))
fmt.Println(*(*reflect.SliceHeader)(unsafe.Pointer(&s2)))
fmt.Println(s2)
fmt.Println(s2 == nil)
fmt.Println(strings.Repeat("--s3--", 10))
fmt.Println(*(*reflect.SliceHeader)(unsafe.Pointer(&s3)))
fmt.Println(s3)
fmt.Println(s3 == nil)
fmt.Println(strings.Repeat("--s4--", 10))
fmt.Println(*(*reflect.SliceHeader)(unsafe.Pointer(&s4)))
fmt.Println(s4)
fmt.Println(s4 == nil)
}
以上代码输出(Go Playground):
--s----s----s----s----s----s----s----s----s----s--
{0 0 0}
[]
--s1----s1----s1----s1----s1----s1----s1----s1----s1----s1--
{18349960 0 0}
[]
--s2----s2----s2----s2----s2----s2----s2----s2----s2----s2--
{18349960 0 0}
[]
--s3----s3----s3----s3----s3----s3----s3----s3----s3----s3--
{824634269696 0 100}
[]
--s4----s4----s4----s4----s4----s4----s4----s4----s4----s4--
{824633835680 0 10}
[]
以上示例中除了 s 其它的 slice 都是空切片,打印出来全部都是 [],s 是nil切片下一小节说。要注意 s1 和 s2 的长度和容量都为0,且引用数组指针都是 18349960, 这点太重要了,因为他们都指向 zerobase 这个特殊的指针,是没有内存分配的。
nil切片
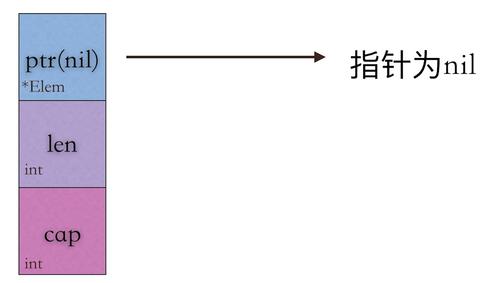
什么是nil切片,这个名字说明nil切片没有引用任何底层数组,底层数组的地址为nil就是nil切片。上一小节中的 s 就是一个nil切片,它的底层数组指针为0,代表是一个 nil 指针。
总结
零切片就是其元素值都是元素类型的零值的切片。
空切片就是数组指针不为nil,且 slice 的长度为0。
nil切片就是引用底层数组指针为 nil 的 slice。
操作上零切片、空切片和正常的切片都没有任何区别,但是nil切片会多两个特性,一个nil切片等于 nil 值,且进行 json 序列化时其值为 null,nil切片还可以通过赋值为 nil 获得。
数组与 slice 大比拼
对数组和 slice 做了性能测试,源码在 GitHub。
对不同容量和数组和切片做性能测试,代码如下,分为:100、1000、10000、100000、1000000、10000000
func BenchmarkSlice100(b *testing.B) {
for i := 0; i < b.N; i++ {
s := make([]int, 100)
for i, v := range s {
s[i] = 1 + i
_ = v
}
}
}
func BenchmarkArray100(b *testing.B) {
for i := 0; i < b.N; i++ {
a := [100]int{}
for i, v := range a {
a[i] = 1 + i
_ = v
}
}
}
测试结果如下:
goos: darwin
goarch: amd64
pkg: github.com/thinkeridea/example/array_slice/test
BenchmarkSlice100-8 20000000 69.8 ns/op 0 B/op 0 allocs/op
BenchmarkArray100-8 20000000 69.0 ns/op 0 B/op 0 allocs/op
BenchmarkSlice1000-8 5000000 318 ns/op 0 B/op 0 allocs/op
BenchmarkArray1000-8 5000000 316 ns/op 0 B/op 0 allocs/op
BenchmarkSlice10000-8 200000 9024 ns/op 81920 B/op 1 allocs/op
BenchmarkArray10000-8 500000 3143 ns/op 0 B/op 0 allocs/op
BenchmarkSlice100000-8 10000 114398 ns/op 802816 B/op 1 allocs/op
BenchmarkArray100000-8 20000 61856 ns/op 0 B/op 0 allocs/op
BenchmarkSlice1000000-8 2000 927946 ns/op 8003584 B/op 1 allocs/op
BenchmarkArray1000000-8 5000 342442 ns/op 0 B/op 0 allocs/op
BenchmarkSlice10000000-8 100 10555770 ns/op 80003072 B/op 1 allocs/op
BenchmarkArray10000000-8 50 22918998 ns/op 80003072 B/op 1 allocs/op
PASS
ok github.com/thinkeridea/example/array_slice/test 23.333s
从上面的结果可以发现数组和 slice 在1000以内的容量上时性能机会一致,而且都没有内存分配,这应该是编译器对 slice 的特殊优化。
从10000~1000000容量时数组的效率就比slice好了一倍有余,主要原因是数组在没有内存分配做了编译优化,而 slice 有内存分配。
但是10000000容量往后数组性能大幅度下降,slice 是数组性能的两倍,两个都在运行时做了内存分配,其实这么大的数组还真是不常见,也没有比较做编译器优化了。
slice 与数组的应用场景总结
slice 和数组有些差别,特别是应用层上,特性差别很大,那什么时间使用数组,什么时间使用切片呢。
之前做了性能测试,在1000以内性能几乎一致,只有10000~1000000时才会出现数组性能好于 slice,由于数组在编译时确定长度,也就是再编写程序时必须确认长度,所有往常不会用到更大的数组,大多数都在1000以内的长度。我认为如果在编写程序是就已经确定数据长度,建议用数组,而且竟可能是局部使用的位置建议用数组(避免传递产生值拷贝),比如一天24小时,一小时60分钟,ip是4个 byte这种情况是可以用时数组的。
为什么推荐用数组,只要能在编写程序是确定数据长度我都会用数组,因为其类型会帮助阅读理解程序,dayHour := [24]Data 一眼就知道是按小时切分数据存储的,如要传递数组时可以考虑传递数组的指针,当然会带来一些操作不方便,往常我使用数组都是不需要传递给其它函数的,可能会在 struct 里面保存数组,然后传递 struct 的指针,或者用 unsafe 来反解析数组指针到新的数组,也不会产生数据拷贝,并且只增加一句转换语句。slice 会比数组多存储三个 int 的属性,而且指针引用会增加 GC 扫描的成本,每次传递都会对这三个属性进行拷贝,如果可以也可以考虑传递 slice 的指针,指针只有一个 int 的大小。
** 对于不确定大小的数据只能用 slice,否则就要自己做扩容很麻烦, 对于确定大小的集合建议使用数组。**
转载:
本文作者: 戚银(thinkeridea)
本文链接: https://blog.thinkeridea.com/201901/go/shen_ru_pou_xi_slice_he_array.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 4.0 CN协议 许可协议。转载请注明出处!