1.引言
最近接触到一个APP流量分析的项目,类似于友盟。涉及到几个C端(客户端)高并发的接口,这几个接口主要用于C端数据的提交。在没有任何缓冲的情况下,一个接口涉及到5张表的提交。压测的结果很不理想,原因有以下几点:
1.业务上处理原始数据,封装数据库对象,需要时间
2.服务与RDS的多张表进行交互
3.web接口同步处理业务
导致一台双核,16G机子,单实例,jdbc最大连接数100,吞吐量竟然只有50TPS。
能想到的改造方案就是引入一层缓冲,让C端接口不与RDS直接交互,也不直接处理业务,很自然就想到了rabbitmq,但是rabbitmq对分布式的支持比较一般,我们的数据体量也比较大,所以我们借鉴了友盟,引入了kafka,Kafka是一种高吞吐量的分布式发布订阅消息系统,起初在不做任何kafka优化的时候,简单地将C端提交的数据直接send到单节点kafka,就这样,我们的吞吐量达到了100TPS.还是有点小惊喜的。
最近一段时间研究了一下kafka,对一些参数进行调整,目前接口的吞吐量已经达到220TPS,写这篇文章主要想记录一下自己优化和部署经历。
2.kafka简介
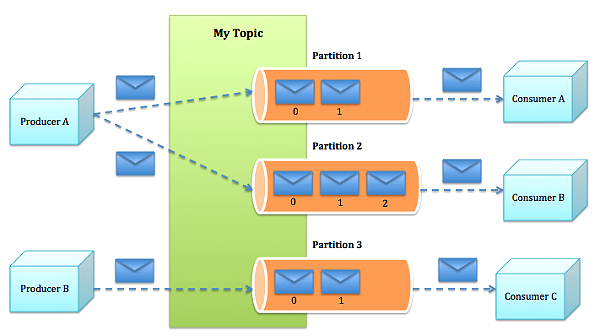
kafka的结构图
这张图很好的诠释了kafka的结构,但是遗漏了一点,就是group的概念,我这里补充一下,一个组可以包含多个consumer对多个topic进行消费,但是不同组的消费都是独立的。
也就是说同一个topic的同一条消息可以被不同组的consumer消费。
我这里的主要的优化途径就是将kafka集群化,多partition化,使其并发度更高。
集群化都很好理解,那什么是多partition?
partition是topic的一个概念,即对topic进行分组,不同partition之间的消费相互独立,且有序。并且任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费,所以咯,假如topic只有一个partition的话,那么在一个Consumer Group内有效的消费者实例最多也就1个,并发度就会受限于kafka的partition数目。
上面都是讲消费,其实send操作也是一样的,要保证有序必然要等上一个发送ack之后,下一个发送才能进行,如果只有一个partition,那send之后的ack的等待时间必然会阻塞下面一次send,设计多个partition之后,可以同时往多个partition发送消息,自然吞吐量也就上去。
3.kafka集群的搭建以及参数配置
集群搭建
准备两台机子,然后去官网(http://kafka.apache.org/downloads)下载一个包。通过scp到服务器上,解压进入config目录,编辑server.config.
第一台机子配置(172.18.240.36):
broker.id=0 每台服务器的broker.id都不能相同 #hostname host.name=172.18.240.36 #在log.retention.hours=168 下面新增下面三项 message.max.byte=5242880 default.replication.factor=2 replica.fetch.max.bytes=5242880 #设置zookeeper的连接端口 zookeeper.connect=172.18.240.36:4001
#默认partition数
num.partitions=2
第二台机子配置(172.18.240.62):
broker.id=1 每台服务器的broker.id都不能相同 #hostname host.name=172.18.240.62 #在log.retention.hours=168 下面新增下面三项 message.max.byte=5242880 default.replication.factor=2 replica.fetch.max.bytes=5242880 #设置zookeeper的连接端口 zookeeper.connect=172.18.240.36:4001 #默认partition数 num.partitions=2
新增或者修改成以上配置。
对了,在此之前请先安装zookeeper,如果你用的是zookeeper集群的话,zookeeper.connect可以填写多个,中间用逗号隔开。
然后启动
nohup ./kafka-server-start.sh ../config/server.properties 1>/dev/null 2>&1 &
测试一下:
在第一台机子上开启一个producer
./kafka-console-producer.sh --broker-list 172.18.240.36:9092 --topic test-test
在第二台机子上开启一个consumer
./kafka-console-consumer.sh --bootstrap-server 172.18.240.62:9092 --topic test-test --from-beginning
第一台机子发送一条消息

第二台机子立马收到消息

这样kafka的集群部署就完成了。就下来我们来看看,java的客户端代码如何编写。
4.kafka客户端代码示例
我这里的工程是建立在spring boot 之下的,仅供参考。
在 application.yml下添加如下配置:
kafka: consumer: default: server: 172.18.240.36:9092,172.18.240.62:9092 enableAutoCommit: false autoCommitIntervalMs: 100 sessionTimeoutMs: 15000 groupId: data_analysis_group autoOffsetReset: latest producer: default: server: 172.18.240.36:9092,172.18.240.62:9092 retries: 0 batchSize: 4096 lingerMs: 1 bufferMemory: 40960
添加两个配置类
package com.dtdream.analysis.config; import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.common.serialization.StringDeserializer; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory; import org.springframework.kafka.config.KafkaListenerContainerFactory; import org.springframework.kafka.core.ConsumerFactory; import org.springframework.kafka.core.DefaultKafkaConsumerFactory; import org.springframework.kafka.listener.ConcurrentMessageListenerContainer; import org.springframework.kafka.listener.adapter.RecordFilterStrategy; import java.util.HashMap; import java.util.Map; @ConfigurationProperties( prefix = "kafka.consumer.default" ) @EnableKafka @Configuration public class KafkaConsumerConfig { private static final Logger log = LoggerFactory.getLogger(KafkaConsumerConfig.class); private static String autoCommitIntervalMs; private static String sessionTimeoutMs; private static Class keyDeserializerClass = StringDeserializer.class; private static Class valueDeserializerClass = StringDeserializer.class; private static String groupId = "test-group"; private static String autoOffsetReset = "latest"; private static String server; private static boolean enableAutoCommit; public static String getServer() { return server; } public static void setServer(String server) { KafkaConsumerConfig.server = server; } public static boolean isEnableAutoCommit() { return enableAutoCommit; } public static void setEnableAutoCommit(boolean enableAutoCommit) { KafkaConsumerConfig.enableAutoCommit = enableAutoCommit; } public static String getAutoCommitIntervalMs() { return autoCommitIntervalMs; } public static void setAutoCommitIntervalMs(String autoCommitIntervalMs) { KafkaConsumerConfig.autoCommitIntervalMs = autoCommitIntervalMs; } public static String getSessionTimeoutMs() { return sessionTimeoutMs; } public static void setSessionTimeoutMs(String sessionTimeoutMs) { KafkaConsumerConfig.sessionTimeoutMs = sessionTimeoutMs; } public static Class getKeyDeserializerClass() { return keyDeserializerClass; } public static void setKeyDeserializerClass(Class keyDeserializerClass) { KafkaConsumerConfig.keyDeserializerClass = keyDeserializerClass; } public static Class getValueDeserializerClass() { return valueDeserializerClass; } public static void setValueDeserializerClass(Class valueDeserializerClass) { KafkaConsumerConfig.valueDeserializerClass = valueDeserializerClass; } public static String getGroupId() { return groupId; } public static void setGroupId(String groupId) { KafkaConsumerConfig.groupId = groupId; } public static String getAutoOffsetReset() { return autoOffsetReset; } public static void setAutoOffsetReset(String autoOffsetReset) { KafkaConsumerConfig.autoOffsetReset = autoOffsetReset; } @Bean public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>(); factory.setConsumerFactory(consumerFactory()); factory.setConcurrency(10); factory.getContainerProperties().setPollTimeout(3000); factory.setRecordFilterStrategy(new RecordFilterStrategy<String, String>() { @Override public boolean filter(ConsumerRecord<String, String> consumerRecord) { log.debug("partition is {},key is {},topic is {}", consumerRecord.partition(), consumerRecord.key(), consumerRecord.topic()); return false; } }); return factory; } private ConsumerFactory<String, String> consumerFactory() { return new DefaultKafkaConsumerFactory<>(consumerConfigs()); } private Map<String, Object> consumerConfigs() { Map<String, Object> propsMap = new HashMap<>(); propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server); propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, enableAutoCommit); propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, autoCommitIntervalMs); propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionTimeoutMs); propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, keyDeserializerClass); propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, valueDeserializerClass); propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, autoOffsetReset); return propsMap; } /* @Bean public Listener listener() { return new Listener(); }*/ }
package com.dtdream.analysis.config; import org.apache.kafka.clients.producer.ProducerConfig; import org.apache.kafka.common.serialization.StringSerializer; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import org.springframework.kafka.annotation.EnableKafka; import org.springframework.kafka.core.DefaultKafkaProducerFactory; import org.springframework.kafka.core.KafkaTemplate; import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap; import java.util.Map; /** * Created with IntelliJ IDEA. * User: chenqimiao * Date: 2017/7/24 * Time: 9:43 * To change this template use File | Settings | File Templates. */ @ConfigurationProperties( prefix = "kafka.producer.default", ignoreInvalidFields = true )//注入一些属性域 @EnableKafka @Configuration//使得@Bean注解生效 public class KafkaProducerConfig { private static String server; private static Integer retries; private static Integer batchSize; private static Integer lingerMs; private static Integer bufferMemory; private static Class keySerializerClass = StringSerializer.class; private static Class valueSerializerClass = StringSerializer.class; private Map<String, Object> producerConfigs() { Map<String, Object> props = new HashMap<>(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server); props.put(ProducerConfig.RETRIES_CONFIG, retries); props.put(ProducerConfig.BATCH_SIZE_CONFIG, batchSize); props.put(ProducerConfig.LINGER_MS_CONFIG, lingerMs); props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, bufferMemory); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, keySerializerClass); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, valueSerializerClass); return props; } private ProducerFactory<String, String> producerFactory() { return new DefaultKafkaProducerFactory<>(producerConfigs()); } public static String getServer() { return server; } public static void setServer(String server) { KafkaProducerConfig.server = server; } public static Integer getRetries() { return retries; } public static void setRetries(Integer retries) { KafkaProducerConfig.retries = retries; } public static Integer getBatchSize() { return batchSize; } public static void setBatchSize(Integer batchSize) { KafkaProducerConfig.batchSize = batchSize; } public static Integer getLingerMs() { return lingerMs; } public static void setLingerMs(Integer lingerMs) { KafkaProducerConfig.lingerMs = lingerMs; } public static Integer getBufferMemory() { return bufferMemory; } public static void setBufferMemory(Integer bufferMemory) { KafkaProducerConfig.bufferMemory = bufferMemory; } public static Class getKeySerializerClass() { return keySerializerClass; } public static void setKeySerializerClass(Class keySerializerClass) { KafkaProducerConfig.keySerializerClass = keySerializerClass; } public static Class getValueSerializerClass() { return valueSerializerClass; } public static void setValueSerializerClass(Class valueSerializerClass) { KafkaProducerConfig.valueSerializerClass = valueSerializerClass; } @Bean(name = "kafkaTemplate") public KafkaTemplate<String, String> kafkaTemplate() { return new KafkaTemplate<>(producerFactory()); } }
利用kafkaTemplate即可完成发送。
@Autowired private KafkaTemplate<String,String> kafkaTemplate; @RequestMapping( value = "/openApp", method = RequestMethod.POST, produces = MediaType.APPLICATION_JSON_UTF8_VALUE, consumes = MediaType.APPLICATION_JSON_UTF8_VALUE ) @ResponseBody public ResultDTO openApp(@RequestBody ActiveLogPushBo activeLogPushBo, HttpServletRequest request) { logger.info("openApp: activeLogPushBo {}, dateTime {}", JSONObject.toJSONString(activeLogPushBo),new DateTime().toString("yyyy-MM-dd HH:mm:ss.SSS")); String ip = (String) request.getAttribute("ip"); activeLogPushBo.setIp(ip); activeLogPushBo.setDate(new Date()); //ResultDTO resultDTO = dataCollectionService.collectOpenInfo(activeLogPushBo); kafkaTemplate.send("data_collection_open",JSONObject.toJSONString(activeLogPushBo)); // logger.info("openApp: resultDTO {} ,dateTime {}", resultDTO.toJSONString(),new DateTime().toString("yyyy-MM-dd HH:mm:ss.SSS")); return new ResultDTO().success(); }
kafkaTemplate的send方法会更根据你指定的key进行hash,再对partition数进行去模,最后决定发送到那一个分区,假如没有指定key,那send方法对分区的选择是随机。具体怎么随机的话,这里就不展开讲了,有兴趣的同学可以自己看源码,我们可以交流交流。
接着配置一个监听器
package com.dtdream.analysis.listener; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.kafka.annotation.KafkaListener; import java.util.Optional; @Component public class Listener { private Logger logger = LoggerFactory.getLogger(this.getClass()); @KafkaListener(topics = {"test-topic"}) public void listen(ConsumerRecord<?, ?> record) { Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { Object message = kafkaMessage.get(); logger.info("message is {} ", message); } } }
@KafkaListener其实可以具体指定消费哪个分区,如果不指定的话,并且只有一个消费者实例,那么这个实例会消费所有的分区的消息。
消费者的数量是一定要少于partition的数量的,不然没有任何意义。会出现消费者过剩的情况。
消费者数量和partition数量的多与少,会动态影响消费节点所消费的partition数目,最终会在整个集群中达到一种动态平衡。
具体的关系可以参考http://www.jianshu.com/p/6233d5341dfe