第三章
概率 与 概率分布
(一)事件
定义:在一定条件下,某种事物出现与否就称为是事件。
自然界和社会生活上发生的现象是各种各样的,常见的有两类。
1、在一定条件下必然出现某种结果或必然不出现某种结果。
确定事件:必然事件(U)(certain event); 不可能事件(V)(impossible event)
2、在一定条件下可能发生也可能不发生。
随机事件(random event);不确定事件(indefinite event)
为了研究随机现象,需要进行大量重复的调查、实验、测试等,这些统称为试验。
(二)频率(frequency)(W)
事件出现的频率(frequency)
若在相同的条件下,进行了n次试验,在这n次试验中,事件A出现的次数m称为事件A出现的频数,比值m/n称为事件A出现的频率(frequency),记为W(A)=m/n。
频率表明了事件频繁出现的程度,因而其稳定性说明了随机事件发生的可能性大小,是其本身固有的客观属性,提示了隐藏在随机现象中的规律性。
频率是在一次试验中某一事件出现的次数与试验总数的比值。概率是某一事件所固有的性质。频率是变化的每次试验可能不同,概率是稳定值不变。在一定条件下频率可以近似代替概率。
(三)概率(probability,P)
概率的统计定义:设在相同的条件下,进行大量重复试验,若事件A的频率稳定地在某一确定值p的附近摆动,则称p为事件A出现的概率。

统计概率(statistics probability)
后验概率(posterior probability)

在一般情况下,随机事件的概率P是不可能准确得到的。通常以试验次数n充分大时,随机事件A的频率作为该随机事件概率的近似值。
概率的古典定义
对于某些随机事件,不用进行多次重复试验来确定其概率,而是根据随机事件本身的特性直接计算其概率。
随机事件特性:
(1)试验的所有可能结果只有有限个,即样本空间中的基本事件只有有限个;
(2)各个试验的可能结果出现的可能性相等,即所有基本事件的发生是等可能的;
(3)试验的所有可能结果两两互不相容。
具有上述特征的随机试验,称为古典概型(classical model).
古典概率(classical probability);先验概率(prior probability)
概率的基本性质
任何事件 0≤P(A)≤1
必然事件 P(U)=1
不可能事件 P(V)=0
随机事件 0<P(A)<1
第二部分 概率的计算
(一)事件的相互关系

l 和事件: 事件A和事件B中至少有一个发生而构成的新事件称为事件A和事件B的和事件,记作A+B。n个事件的和,可表示为A1+A2+…+An
l 积事件:事件A和事件B中同时发生而构成的新事件称为事件A和事件B的积事件,记作A•B。n个事件的积,可表示为A1 •A2 •… • An
l 互斥事件(互不相容事件):事件A和事件B不能同时发生,则称这两个事件A和B互不相容或互斥。 A•B=V,n个事件两两互不相容,则称这n个事件互斥。
对立事件:事件A和事件B必有一个发生,但二者不能同时发生,且A和B的和事件组成整个样本空间。即A+B=U,AB=V。我们称事件B为事件A的对立事件。如:新生儿男或女。
l 独立事件:事件A和事件B的发生无关,事件B的发生与事件A的发生无关,则事件A和事件B为独立事件。如:种子发芽。如果多个事件A1、A2、A3、…、An 彼此独立,则称之为独立事件群。
完全事件系: 如果多个事件A1、A2、A3、…、An两两互斥,且每次试验结果必然发生其一,则称事件A1、A2、A3、…、An为完全事件系。完全事件系的和事件概率为1,任何一个事件发生的概率为1/n。即:

(二)概率的计算法则
1 互斥事件加法定理
定理: 若事件A与B互斥,则 P(A+B)=P(A)+P(B)
试验的全部结果包含n个基本事件,事件A包含其中m1个基本事件,事件B包含其中m2个基本事件。由于A和B互斥,因而它们各包含的基本事件应该完全不同。所以事件A+B所包含的基本事件数为m1+m2。

推理1 P(A1+A2+…+An)=P(A1)+P(A2)+…+P(An)
推理2 P(A)=1-P(A)
推理3 完全事件系的和事件的概率为1。
2 独立事件乘法定理
定理: 事件A和事件B为独立事件,则事件A与事件B同时发生的概率为各自概率的乘积。 P(AB)=P(A)P(B)
推理:A1、A2、…An彼此独立,则
P(A1A2A3…An)=P(A1)P(A2)P(A3)…P(An)
第三部分 概 率 分 布
(一)离散型变量的概率分布
要了解离散型随机变量x的统计规律,必须知道它的一切可能值xi及其每种可能值的概率pi。对离散型变量x的一切可能值xi(i=1,2,3…),及其对应的概率pi

P (x=xi)称为离散型随机变量x的概率函数。
(二)连续型变量的概率分布
当试验资料为连续型变量,一般通过分组整理成频率分布表。如果从总体中抽取样本的容量n相当大,则频率分布就趋于稳定,我们将它近似地看成总体概率分布。

当n无限大时,频率转化为概率,频率密度也转化为概率密度,阶梯形曲线也就转化为一条光滑的连续曲线,这时频率分布也就转化为概率分布了,此曲线为总体的概率密度曲线,曲线函数f(x)称为概率密度函数。

对于一个连续型随机变量x,取值于区间[a,b]内的概率为函数f(x)从a到b的积分,即:

连续型随机变量的概率由概率分布密度函数所确定。

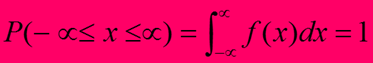
概率密度函数f(x)曲线与x轴所围成的面积为1。
第四部分 大 数 定 律
大数定律:是概率论中用来阐述大量随机现象平均结果稳定性的一系列定律的总称。
主要内容:样本容量越大,样本统计数与总体参数之差越小。
(1)贝努里大数定律
设m是n次独立试验中事件A出现的次数,而p是事件A在每次试验中出现的概率,则对于任意小的正数ε,有如下关系:
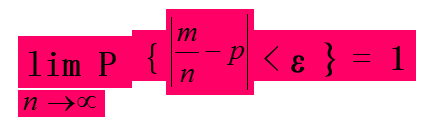
(2)辛钦大数定律
设x1,x2,x3,…,xn是来自同一总体的变量,对于任意小的正数ε,有如下关系:

第二节:几种常见的理论分布
随机变量的概率分布 (probability distribution)

一、二 项 分 布
二 项 分 布是一种离散型随机变量 的分布,对于某个性状,常常可以把其资料分为两个类型。试验结果只能是“非此即彼”构成对立事件,将这种事件构成的总体称为二项总体,其概率分布称为二项分布。



相比较就可以发现,在n重贝努里试验中,事件A发生x次的概率恰好等于展开式中的第x+1项,所以把P(x)称为随机变量x服从参数为n和p的二项分布(binomial distribution),也称为贝努里分布,记作B(n,p)。这种“非此即彼”的事件所构成的总体称为二项总体。
二项分布的两个条件:
试验只有两个对立结果,记为A和A,出现概率分别为p和q=1-p。
重复性:每次试验条件不变时,事件A出 现为恒定概率p;
独立性:任何一次试验中事件A的出现与其余各次试验结果无关。

二项分布的形状和参数
二项分布的形状由n和p两个参数决定。B(n,p)
(1)当p值较小且n不大时,分布是偏倚的。随n的增大,分布趋于对称;
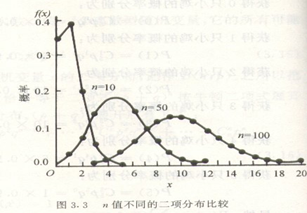
(2)当p值趋于0.5时,分布趋于对称。
 c
c
统计学证明,服从二项分布B(n,p)的随机变量所构成的总体的平均数μ 、标准差σ与n、p这两个参数有关。

在二项分布中,事件A发生的频率 x/n称为二项成数,即百分数或频率。则二项成数的平均数和标准差分别为:

二、泊 松 分 布
泊松分布就是描述某段时间内,事件具体的发生概率。
泊松分布(Poisson distribution) 是一种可以用来描述和分析随机地发生在单位空间或时间里的稀有事件的概率分布,也是一种离散型随机变量的分布。
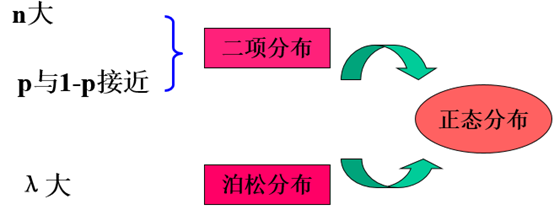
泊松分布是二项分布的一种特殊类型。
泊松分布的概率函数 可由二项分布概率函数推导出来


对于小概率事件,可用泊松分布描述其概率分布。
二项分布当p<0.1和np<5时,可用泊松分布来近似。
三、正 态 分 布normal distribution
围绕在平均值左右,由平均值到分布的两侧,变量数减少,即两头少,中间多,两侧对称。
正态分布也称为高斯分布(Gauss distribution)。
(一)正态分布的概率函数
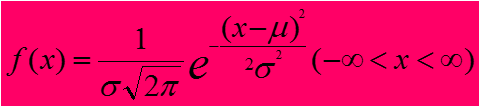
f(x) 为正态分布的概率密度函数,表示某一定x值出现的概率密度函数值。
μ总体平均数 σ总体标准差
N (μ,σ2)
(二)正态分布的特征

x=μ时,f(x)值最大,正态分布曲线以平均数μ为中心的分布。
x-μ的绝对值相等时,f(x)也相等,正态分布密度曲线以μ为中心向左右两侧对称。
f(x)是非负函数,以x轴为渐近线,x的取值区间为(-∞,+∞) 。

正态分布曲线由参数μ,σ决定, μ确定正态分布曲线在x轴上的中心位置,σ确定正态分布的变异度。

正态分布曲线在x=μ±σ处各有一个拐点,曲线通过拐点时改变弯曲度。
分布曲线与x轴围成的全部面积为1
若一个连续型随机变量x取值于区间[a,b],其概率为

f(u)称为标准正态分布(standard normal distribution)或u分布方程。

u表示标准正态离差(standard normal deviate),它表示离开平均数μ有几个标准差σ。


为了计算方便,对于不同的u值,计算出不同的F(u),编成函数表,称为正态分布表,从中可以查到u任意一个区间内取值的概率。
(四)正态分布的概率计算

服从正态分布N(μ,σ2)的随机变量,x的取值落在区间[x1,x2] 的概率,记作P(x1≤x<x2),等于服从标准正态分布的随机变量u在[(x1-μ)/ σ, (x2-μ)/ σ]内取值的概率。



 c
c
(五)正态分布的应用
正态分布是很多统计方法的理论基础。
二项分布,泊松分布的极限均为正态分布,在一定条件下,均可按正态分布的原理来处理。后面的t检验,方差分析,相关回归分析等多种统计方法均要求分析的指标服从正态分布。对于非正态分布资料,实施统计处理的一个重要途径是先作变量的转换,使转换后的资料近似正态分布,然后按正态分布的方法作统计处理。
第三节 统计数的分布
研究总体与从总体中抽取样本之间的关系:
1:总体-----样本,了解从总体中抽取样本的变异特点即抽样分布也称统计数的分布;
2样本-----总体,要根据样本统计数去推断总体即统计推断问题.
一、抽样试验与无偏估计
根据样本对总体做出估计和推断,并不是直接用样本本身,而是用样本的统计量来对总体做出估计和判断。但由于从总体中抽取的样本提供的信息仅是总体的一部分,因此它不能提供完全准确的信息,必然存在着一定的误差。即,对于样本容量相同的多次随机抽样,得到样本函数的观察值也是不同的,且其取值有一定的概率,即统计量也是一个随机变量,因而也有它的分布,称为抽样分布(sampling distribution)。
二、样本平均数的分布
由于从总体中抽出的样本为每一个可能样本,且每个样本中的变量均为随机变量,所以其样本平均数也为随机变量,也形成一定的理论分布,这种理论分布称为样本平均数的概率分布,或称样本平均数的分布。

样本平均数分布的基本性质


标准误反映了样本平均数 x 的抽样误差,即精确性的高低。
标准误大,各样本平均数间差异程度大,样本平均数的精确性低。
标准误小,各样本平均数间差异程度小,样本平均数的精确性高。
标准误的大小与原总体的标准差σ 成正比,与样本含量n的平方根成反比。
从某特定总体抽样,因为σ是一定值,所以只有增大样本容量,才能降低样本平均数的抽样误差。

若样本中各观测值为x1,x2,x3,…xn,则

均数的标准误与标准差成正比,而与样本例数n的平方根成反比。若标准差固定不变,可通过增加样本含量n来减少抽样误差。
样本平均数分布的基本性质
(3)如果从正态分布总体N(μ,σ2)进行抽样,其样本平均数x是一具有平均数 μ,方差σ2/n的正态分布,记作N(μ,σ2/n)。
中心极限定理 (central limit theorem)
(4)如果被抽总体不是正态分布总体,但具有平均数μ和方差σ2 ,当随样本容量n的不断增大,样本平均数 x 的分布也越来越接近正态分布,且具有平均数μ,方差σ2 /n ,这被称为中心极限定理 (central limit theorem) 。
不论总体为何种分布,只要是大样本,就可运用中心极限定理,认为样本平均数的分布是正态分布,在计算样本平均数出现的概率时,样本平均数可按下式进行标准化。

三、样本平均数差数的分布
样本平均数差数分布的基本性质
(1)样本平均数差数的平均数 = 总体平均数的差数.

(2)样本平均数差数的方差 = 两样本平均数方差之和.

(3)从两个独立正态分布总体中抽出的样本平均数差数的分布,也是正态分布。

四、t 分布

t分布概率密度函数
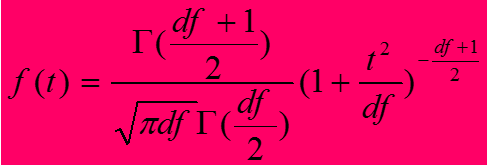


特征
(1)t分布曲线是左右对称的,围绕平均数μt =0 向两侧递降。
(2)t分布受自由度df=n-1的制约,每个自由度都有一条t分布曲线。
(3)和正态分布相比,t分布顶端偏低,尾部偏高,自由度df>30时,其曲线接近正态分布曲线,df→∝时则和正态分布曲线重合。
t分布曲线与横轴所围成的面积为1。
同标准正态分布曲线一样,统计应用中最为关心的是t分布曲线下的面积(即概率P)与横轴t值间关系。

1在相同的自由度df时,t值越大,概率P越小。
2在相同t值时,双尾概率P为单尾概率P的两倍
3 df增大,t分布接近正态分布,即t值接近u值。
五、x2 分布
从方差为σ2的正态总体中,随机抽取k个独立样本,计算出样本方差S2,研究其样本方差的分布。
在研究样本方差的分布时,通常将其标准化,得到k个正态离差u,则




χ2分布于区间[0,+∝ ),并且呈反J型的偏斜分布。
χ2分布的偏斜度随自由度降低而增大,当自由度df=1时,曲线以纵轴为渐近线。
随自由度df的增大, χ2分布曲线渐趋左右对称,当df>30时,卡方分布已接近正态分布。

对于给定的α(0<α<1),
称满足条件 P{x2>xα2(n)}=α的点 xα2(n)为
x2分布的上α分位点(右尾概率)。

六、F 分布
设从一正态总体N(μ,σ2) 中随机抽取样本容量为n1、n2的两个独立样本,其样本方差为s12、 s22,则定义其比值F为 :

此F值具有s12的自由度df1=n1-1和s22的自由度df2=n2-1。
如果对一正态总体在特定的df1和df2进行一系列随机独立抽样,则所有可能的F值就构成一个F分布。
F分布的概率密度函数是两个独立χ2变量的概率密度所构成的联合概率密度。


F分布是随自由度df1和df2进行变化的一组曲线。
F分布的概率累积函数



F分布的平均数μF=1 ,F的取值区间为[0,+∝)
F分布曲线的形状仅决定于df1和df2。在df1=1或2时,F分布曲线呈严重倾斜的反向J型,当df1≧ 3时,转为左偏曲线。

对于给定的α(0<α<1) 称满足条件
P{F>Fα(n1,n2)}=α的点Fα(n1,n2)为F分布的上α分位点(或临界值点)。
