前言
最早做非结构化数据搜索时用的还是lucene.net,一直说在学习java的同时把lucene这块搞一搞,这拖了2年多了,终于开始搞这块了。
开发环境
idea2016、lucene6.0、jdk1.8
使用lucene准备条件
1、pom.xml
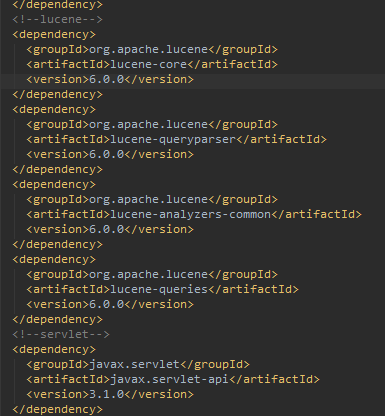
2、测试数据。 我从博客园首页拿了几条数据,直接写了个伪Dao返回一个List<Blog>
public List<Blog> listBlogs(){
List<Blog> list = new ArrayList<Blog>();
Blog b1=new Blog(6538488,"风过无痕-唐","你真的了解volatile吗,关于volatile的那些事","http://www.cnblogs.com/tangyanbo/p/6538488.html");
Blog b2=new Blog(6541312,"布鲁克石","TypeScript设计模式之职责链、状态","http://www.cnblogs.com/brookshi/p/6541312.html");
Blog b7=new Blog(6547215,"嵘么么","轻松理解JavaScript闭包","http://www.cnblogs.com/rongmm/p/6547215.html");
Blog b3=new Blog(6541220,"一线码农","使用Task的一些知识优化了一下同事的多线程协作取消的一串代码","http://www.cnblogs.com/huangxincheng/p/6541220.html");
Blog b4=new Blog(6516387,"xybaby","并发与同步、信号量与管程、生产者消费者问题","http://www.cnblogs.com/xybaby/p/6516387.html");
Blog b5=new Blog(6532713,"王福朋","深入理解 JavaScript 异步系列(4)—— Generator","http://www.cnblogs.com/wangfupeng1988/p/6532713.html");
Blog b6=new Blog(6517788,"欢醉","入坑系列之HAProxy负载均衡","http://www.cnblogs.com/zhangs1986/p/6517788.html");
list.add(b1);
list.add(b2);
list.add(b3);
list.add(b4);
list.add(b5);
list.add(b6);
list.add(b7);
return list;
}
IndexSearcher搜索
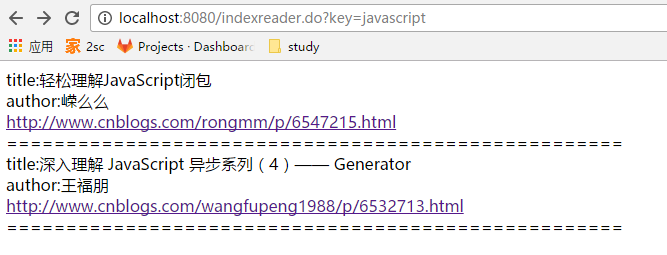
1、搜索体验,基于servlet开发,直接接受路径参数key
2、先写入索引
public class IndexWriterServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String index_path="d:\indexDir";
Directory dir=null;
Analyzer analyzer=null;
IndexWriterConfig config=null;
IndexWriter indexWriter=null;
try {
dir =new SimpleFSDirectory(Paths.get(index_path));
analyzer=new StandardAnalyzer();
config =new IndexWriterConfig(analyzer);
indexWriter =new IndexWriter(dir,config);
BlogDao blogDao=new BlogDao();
List<Blog> list = blogDao.listBlogs();
for (Blog blog:list){
Document document=new Document();
document.add(new Field("id",blog.getId().toString(),TextField.TYPE_STORED));
document.add(new Field("author",blog.getAuthor(),TextField.TYPE_STORED));
document.add(new Field("title",blog.getTitle(),TextField.TYPE_STORED));
document.add(new Field("url",blog.getUrl(),TextField.TYPE_STORED));
indexWriter.addDocument(document);
}
indexWriter.commit();
System.out.println("====索引创建完成====");
}catch (Exception ex){
ex.printStackTrace();
}finally {
if(indexWriter !=null){
indexWriter.close();
}
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
2、查询索引数据
public class IndexReaderServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
Directory dir =null;
DirectoryReader reader =null;
IndexSearcher searcher=null;
String index_path="d:\indexDir";
try{
//dir =new RAMDirectory();
dir =new SimpleFSDirectory(Paths.get(index_path));
reader = DirectoryReader.open(dir);
searcher=new IndexSearcher(reader);
String key = req.getParameter("key");
Query query = new TermQuery(new Term("title",key));
TopDocs rs=searcher.search(query,100);
resp.setContentType("text/html");
resp.setCharacterEncoding("UTF-8");
PrintWriter out = resp.getWriter();
StringBuilder strHtml =new StringBuilder();
for (int i = 0; i < rs.scoreDocs.length; i++) {
Document firstHit = searcher.doc(rs.scoreDocs[i].doc);
strHtml.append("title:"+firstHit.getField("title").stringValue()+"<br>");
strHtml.append("author:"+firstHit.getField("author").stringValue()+"<br>");
strHtml.append("<a href='"+firstHit.getField("url").stringValue()+"'>"+ firstHit.getField("url").stringValue()+"</a><br>");
strHtml.append("====================================================<br>");
}
out.write(strHtml.toString());
}catch (Exception ex){
ex.printStackTrace();
}finally {
reader.close();
}
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
总结
读写索引用到的几个关键类:IndexWriter、IndexSearcher、Directory、DirectoryReader、Document、TermQuery、Field